
Minjia Chen, Qixiang Cheng, Masafumi Ayata, Mark Holm, Richard Penty. Iterative photonic processor for fast complex-valued matrix inversion[J]. Photonics Research, 2022, 10(11): 2488
- Photonics Research
- Vol. 10, Issue 11, 2488 (2022)
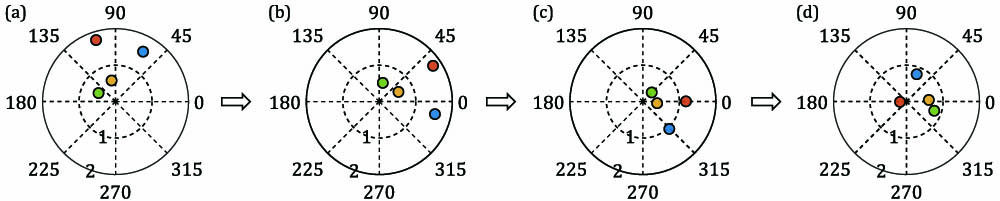
Fig. 1. Graphical explanation of the Min-Max algorithm for a 4 × 4 A ω A ω opt A I N − ω opt A ρ ( I N − ω opt A ) < 1
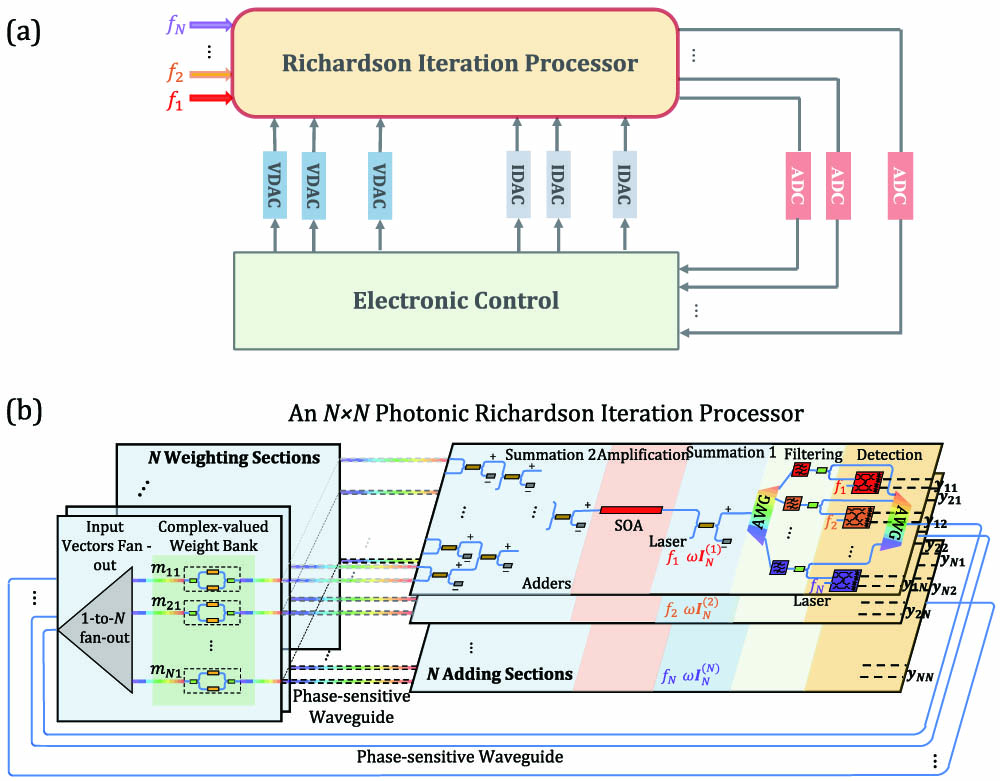
Fig. 2. System architecture of the proposed N × N N × N Laser , Summation 1 , Input Vectors Fan-Out , Weight Bank , Summation 2 , Amplification , Filtering , Detection , and Recirculating Loop . AWG, arrayed waveguide gratings.
Fig. 3. Models of (a) 1-to-N Fan-Out block, (b) Summation block, (c) Weight Bank block, (d) Laser block, (e) Amplification and Filtering blocks , (f) Detection block, and (g) electronic peripherals.
Fig. 4. (a) Typical signal amplitude changes during computation without filtering. (b) Plot of the sine integral function; (c) typical signal amplitude changes during computation after filtering.
Fig. 5. Conceptual figure of an integrated 4 × 4
Fig. 6. (a), (b) Net computing speed of different-sized N × N Si 3 N 4 N × N
Fig. 7. Matrix weights encoding error for (a)–(e) different DAC bit resolutions and (f) 20 nm wavelength span. Using a 16-bit DAC is enough to guarantee < 0.1 % P in , sat
Fig. 8. (a) Inversion accuracy of different-sized photonic RIPs when input signal powers are different (optical filter BW = 64.5 MHz > 1 dBm > 90 % 2 × 2 64 × 64
|
Table 1. Summary of Main Direct Inversion Methods
|
Table 2. Summary of Main Iterative Inversion Methods
|
Table 3. Correspondence between Key Photonic Blocks and Computational Functionalities
|
Table 4. Comparison of III-V-on-Si Integration Methods
|
Table 5. Length Estimation of an N × N
|
Table 6. Power Estimation of an N × N
|
Table 7. Parameters Used in Accuracy Analyses of the Iterative Photonic Processor

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20