Author Affiliations
1Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen 518055, China2School of Microelectronics, Xidian University, Xi'an710071, China3School of Information and Communication, Guilin University of Electronic Technology, Guilin 541004, China4Changzhou Campus of Hohai University, Changzhou 213022, Chinashow less
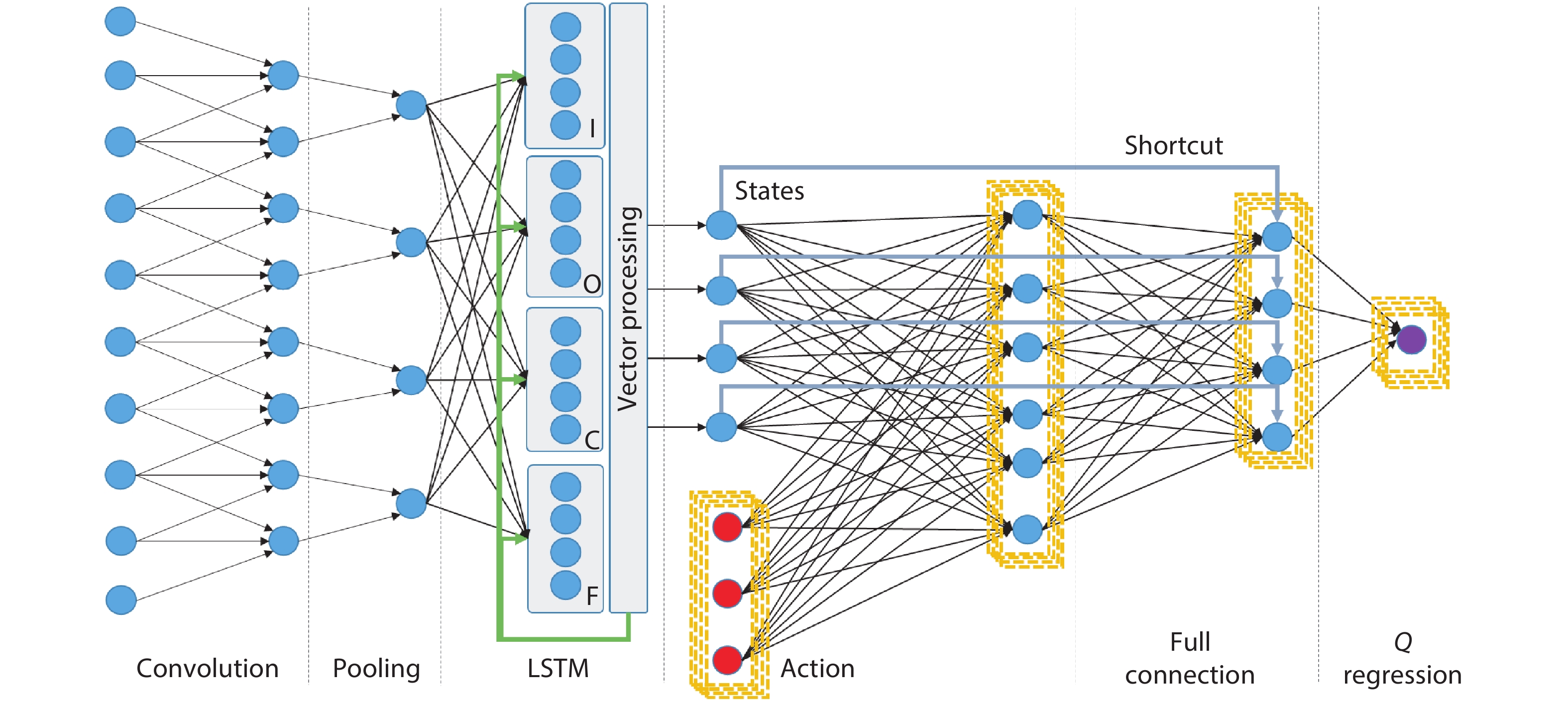
Fig. 1. (Color online) Structure of hybrid neural network targeting perception and control with layer-wise algorithmic kernels.
Fig. 2. Orientation and dimensions of compact CNN filters.
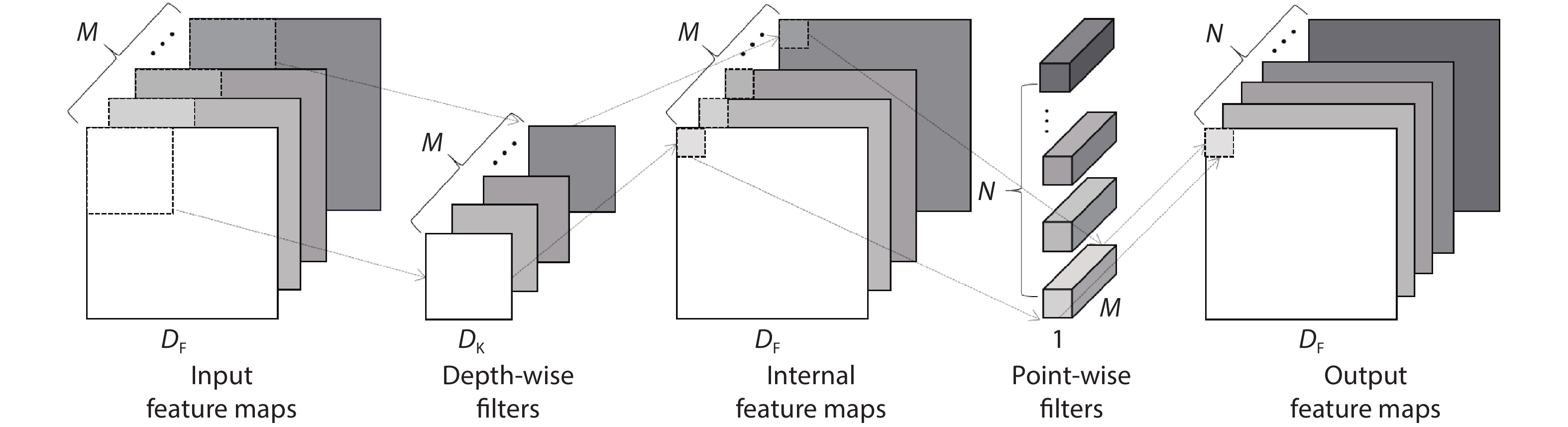
Fig. 3. (Color online) Structure and operation distribution for Mobile-Net.
Fig. 4. (Color online) Reconfiguration of dataflow, PE and storage functionalities for standard kernels.
Fig. 5. (Color online) Reconfiguration of dataflow for pointwise (PW) and depthwise (DW) convolution kernels.
Fig. 6. (Color online) Microarchitecture of proposed reconfigurable dataflow processor.
Fig. 7. (Color online) Instruction set architecture (ISA) and developing toolchain.
Fig. 8. (Color online) Operational phases of proposed architecture.
Fig. 9. (Color online) Comparison of Q iteration time between proposed architecture and host machine (CPU)[27].
Fig. 10. (Color online) (a) ASIC layout with 16 reconfigurable PEs. Logics (middle) surrounded by 18 SRAM blocks. (b) Micrograph of taped-out chip with UMC CMOS 65 nm low-leakage technology.
Fig. 11. (Color online) Views of the testing board. The front view contains testing IC under CLCC84 packaging and socket. The rear view contains FPGA for interfacing IC with the host machine.
Fig. 12. (Color online) Testing infrastructure with measurement of both signal voltages and currents.
Fig. 13. (Color online) Runtime current measurement across different phases of operation under 30 MHz frequency.
| NN Layer | Convolution | Pooling | FC | LSTM | State-action | Shortcut |
|---|
| Operands | Sparse matrix | Vector | Dense matrix | Dense matrix | Dense matrix | Vector | | Operators | Sum of product (SoP) | Max, min, mean | SoP | SoP vector multiply vector sum | SoP | Vector sum | | Nonlinear functions | ReLU sigmoid | None | ReLU sigmoid | Sigmoid tangent | ReLU sigmoid | None | | Dataflow property | Serial in/out thread-level parallelism | Parallel in/out | Serial in/out thread-level parallelism | Serial in/out shared among gates | Serial in/out action nodes iteration | Parallel in/out | | Buffering property | Activation dominant | Activation dominant | Weight dominant | Weight, states | Weight, states, actions | Activation pointer |
|
Table 1. Operation characteristics among multiple standard neural network kernels.
| Layer | Filter size | Input size | MAC amounts |
|---|
| Standard conv | | | | | Conv DW | | | | | Conv PW | | | |
|
Table 2. Number of operations of standard, DW and PW convolution layers.
| Layer type | Input size | #. MACs | Multi-threaded streaming architecture @ 100 MHz | Single-threaded latency (ms)[24] |
|---|
| Max BW utilization | Max PE utilization | #. stream | ns / stream | Latency (ms) |
|---|
| Conv0 Std. | 224 × 224 × 3 | 10.84M | 3% | 6.70% | 25088 | 3340 | 83.8 | 83.8 | | Conv1 DW | 112 × 112 × 32 | 3.61M | 10% | 6.70% | 25088 | 2080 | 17.4 | 380.5 | | Conv1 PW | 112 × 112 × 32 | 25.69M | 100% | 100.00% | 3136 | 1835 | 5.8 | 92.1 | | Conv2 DW | 112 × 112 × 64 | 1.81M | 10% | 6.70% | 12544 | 2080 | 8.7 | 190.2 | | Conv2 PW | 56 × 56 × 64 | 25.69M | 100% | 100.00% | 1568 | 3520 | 5.5 | 88.3 | | Conv3 DW | 56 × 56 × 128 | 3.61M | 10% | 6.70% | 25088 | 2080 | 17.4 | 380.5 | | Conv3 PW | 56 × 56 × 128 | 51.38M | 100% | 100.00% | 1568 | 6890 | 10.8 | 172.9 | | Conv4 DW | 56 × 56 × 128 | 0.90M | 10% | 6.70% | 6272 | 2080 | 4.3 | 95.1 | | Conv4 PW | 28 × 28 × 128 | 25.69M | 100% | 100.00% | 784 | 6890 | 5.4 | 86.4 | | Conv5 DW | 28 × 28 × 256 | 1.81M | 10% | 6.70% | 12544 | 2080 | 8.7 | 190.2 | | Conv5 PW | 28 × 28 × 256 | 51.38M | 100% | 100.00% | 784 | 13630 | 10.7 | 171 | | Conv6 DW | 28 × 28 × 256 | 0.45M | 10% | 6.70% | 3136 | 2080 | 2.2 | 47.6 | | Conv6 PW | 14 × 14 × 256 | 25.69M | 100% | 100.00% | 416 | 13630 | 5.7 | 90.7 | | Conv7-11DW | 14 × 14 × 512 | 0.90M | 10% | 6.70% | 6272 | 2080 | 4.3 | 95.1 | | Conv7-11PW | 14 × 14 × 512 | 51.38M | 100% | 100.00% | 416 | 27110 | 11.3 | 180.4 | | Conv12 DW | 14 × 14 × 512 | 0.23M | 10% | 6.70% | 1568 | 2080 | 1.1 | 23.8 | | Conv12 PW | 7 × 7 × 512 | 25.69M | 100% | 100.00% | 256 | 27110 | 6.9 | 111 | | Conv13 DW | 7 × 7 × 1024 | 0.45M | 10% | 6.70% | 3136 | 2080 | 2.2 | 47.6 | | Conv13 PW | 7 × 7 × 1024 | 51.38M | 100% | 100.00% | 256 | 54070 | 13.8 | 221.5 | | Avg Pool | 7 × 7 × 1024 | 0.05M | 10% | 6.70% | 64 | 1767 | 0.1 | 0.1 | | FC | 1 × 1 × 1024 | 1.02M | 55% | 6.70% | 63 | 90218 | 5.7 | 5.7 | | Total | — | 569M | — | — | — | — | 294.3 | 3856.5 |
|
Table 3. Benchmark of performance for MobileNet with proposed architecture[25].
| Network layer specification | 1st LSTM layer | 2nd LSTM layer (if need) | 1st FC layer (if need) | 2nd FC layer |
|---|
| In nodes: 3, Out nodes: 12, Recurrent nodes: 48 | In nodes: 12, Out nodes: 12, Recurrent nodes: 48 | In nodes: 12, Out nodes: 12 | In nodes: 12, Out nodes: 5 |
|---|
| * Simulation result, not account for data transferring between disk storage and DRAM. | | Network | Performance (ms/sample) | Average power consumption | | 1 LSTM + 1 FC | 2 LSTM + 1 FC | 2 LSTM + 2 FC | | CPU Intel i7-8700 @3.20 GHz | 11.981 | 22.362 | 23.962 | 60–70 W | | CPU Intel i7 w. GPU NVIDIA GTX 1050 | 2.87 | 4.94 | 5.74 | 50–70 W | | Proposed design with 16 PEs @ 100 MHz * | 1.033 | 1.157 | 1.957 | 30–50 mW |
|
Table 4. Benchmark of performance for LSTM networks among three processing architectures.
| Frequency (MHz) | Initialize | Conv1 | Pool1 | Conv2 | Pool2 | FC | Idle | Avg. (conv1-fc) |
|---|
| 30 | 1.92 | 2.84 | 2.58 | 3.04 | 2.71 | 3.32 | 1.92 | 2.62 | | 60 | 3.32 | 5.29 | 4.76 | 5.47 | 5.09 | 5.74 | 3.32 | 4.71 | | 100 | 5.19 | 8.56 | 7.67 | 8.71 | 8.26 | 8.97 | 5.19 | 7.51 |
|
Table 5. Runtime power consumption in mW for different phases and frequencies.
| Parameter | Eyeriss[28] | ENVISION[29] | Thinker[30] | This work | This work |
|---|
| Technology (nm) | 65 | 28 | 65 | 65 | 65 | | Core area (mm2)
| 12.25 | 1.87 | 19.36 | 3.24 | 3.24 | | Bit precision (b) | 16 | 4/8/16 | 8/16 | 8 | 8 | | Num. of MACs | 168 | 512 | 1024 | 16 | 256 | | Core frequency (MHz) | 200 | 200 | 200 | 100 | 100 | | Performance (GOPS) | 67.6 | 76 | 368.4 | 3.2 | 51.2 | | Power (mW) | 278 | 44 | 290 | 7.51 (measured) | 55.4 (estimated) | | Energy efficiency | 166.2 GOPS/W | 1.73 TOPS/W | 1.27 TOPS/W | 426 GOPS/W | 0.92 TOPS/W |
|
Table 6. Comparison of physical properties with state-of-the-art designs.