
Haorui Zuo, Zhiyong Xu, Jianlin Zhang, Ge Jia. Visual tracking based on transfer learning of deep salience information[J]. Opto-Electronic Advances, 2020, 3(9): 190018-1
- Opto-Electronic Advances
- Vol. 3, Issue 9, 190018-1 (2020)
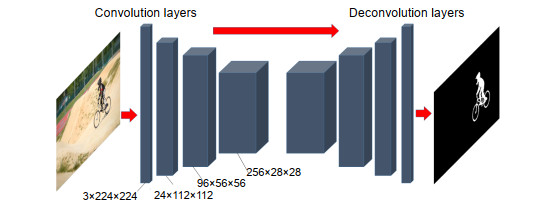
Fig. 1. The FCNs for salience detection. Our network is designed for static salience detection. It takes a single frame as input and outputs the estimation of the static salience prediction of the image.

Fig. 2. Salience sketch image from videos.The 1st row images are from skier video. The 2nd row images are the salience maps of the skier; the 3rd row images are from leopard video; the 4th row images are the salience maps of leopard.
Fig. 3. The architecture of new multi-domain network.
Fig. 4. Representative images selected from the Car2 sequence of VOT15. As can be seen from the three similar segment sequences, many images show little difference compared to others. When we go through at least 20 frames generally, scale variation, illumination variation, background clutter and so on can be found.
Fig. 5. The weights for the images distributed by Gaussian distribution to generate certain numbers of samples. As can be seen from the figure, the frames at the beginning and the end of the group will have less weight than those in the middle. The frames located closer to the center of the group are designed to generate more samples because they could make greater distinctions.
Fig. 6. The Precision plots and the success plots on the OTB50 dataset.We compare the results with the change of the salience extraction layers and find three layers best in them.
Fig. 7. The Precision plots and the success plots on the OTB50 dataset.
Fig. 8. Comparison with the state-of-the-art methods on the OTB100 dataset.
Fig. 9. Comparison among the proposed method and several deep-learning methods and traditional methods on UAV123.
Fig. 10. The tracking examples where our proposed algorithm is compared with other trackers. As illustrated by the challenging videos, other trackers are vulnerable and sensitive to inferences caused by generic objects and background clutter while our tracker recognizes the target in the most difficult cases.
|
Table 1. The testing results of our proposed method and some typical trackers on the VOT15 challenge.

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20