
Haorui Zuo, Zhiyong Xu, Jianlin Zhang, Ge Jia. Visual tracking based on transfer learning of deep salience information[J]. Opto-Electronic Advances, 2020, 3(9): 190018-1
- Opto-Electronic Advances
- Vol. 3, Issue 9, 190018-1 (2020)
Abstract
Introduction
Visual tracking is a fundamental problem in computer vision with wide-spread applications in many areas such as auto driving, trajectory guidance, robot navigation, surveillance systems and so on. With the development of artificial intelligence, there are urgent needs of highly efficient and robust visual tracking algorithms. Although much great progress in visual tracking has been made with a wide range of new methods like MD-CNNs (multi-domain convolution neural network)
Aside from generative methods, discriminative methods track objects with a binary classification principle to distinguish the target from the background. These methods extract the typical and predefined features of both the target and background to exploit the information of the image. The traditional classifiers such as random forest
Recently deep learning methods have boosted the overall performance greatly in computer vision tasks including visual tracking. These methods explore the usage of autoencoder
The remaining of the paper is organized as below: In Section 2, the related work of visual tracking and salience detection is introduced. In Section 3 and Section 4, we give the details of the salience detection model and the new MD-CNN model. We perform the corresponding experiments to validate our methods in Section 5. In Section 6, our contributions are summarized and the conclusions are drawn.
Related work
With deep learning pervading many fields of computer vision, it is also applied in the area of salience detection. Many methods are designed for visual salience such as absorbing Markov chain
As deep learning shows excellent performance in object detection, researchers start spending efforts in exploring the combination of deep learning and visual tracking due to the similarity between object detection and tracking. Ref.
Salience detection model
In the human visual system, the visual attention mechanism plays a very important role as the key to ensure the human perception of the environment in time and efficiently. In the field of computer science, the research of visual attention mechanism is to process the given image and highlight the areas of interest. This process is the visual salience detection, visual salience detection is used to identify the most distinct region in a complex scene, which attracts ordinary creature's attention at the first sight. To reduce the complexity of image analysis and exclude useless information, visual salience detection is widely applied to tasks of computer vision including image compression, image segmentation, object recognition, visual tracking and so on. Visual attention prediction
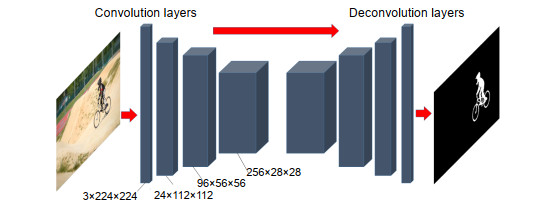
![]()
Figure 1.The FCNs for salience detection. Our network is designed for static salience detection. It takes a single frame as input and outputs the estimation of the static salience prediction of the image.
We propose a model adopting FCNs for pixel-wise salience detection. We investigate the deep learning methods for end-to-end training and pixel-wise salience predictions. Due to the lack of enough labeled salience detection training data, we adopt some famous video object segmentation datasets such as FBMS
![]()
Figure 2.Salience sketch image from videos.The 1st row images are from skier video. The 2nd row images are the salience maps of the skier; the 3rd row images are from leopard video; the 4th row images are the salience maps of leopard.
Our model
The deep learning methods require a large amount of labeled training data for supervised learning. Prior knowledge is not sufficient in the field of tracking in most cases. To improve the tracking performance by deep learning approaches, we design a new deep learning architecture for tracking by integrating the result of salience detection as prior knowledge. One of the advantages of the architecture is that it makes the target with salience easier to be detected. The deep convolution neural network can extract distinct features of the salient target, which can be exploited to track the target stably.
Basic model structure
The original MD-CNNs can learn domain-independent information from capturing domain-specific representations
![]()
Figure 3.The architecture of new multi-domain network.
The input of MD-CNNs is color image patch of size 224×224. For tracking, we only need to classify the image into the target and background. It is simply a binary classification problem. Let target be denoted as label "1" for output, and background as "0". There are 7 shared layers and the former 4 layers are used for salience detection. Since we have different targets in different tracking sequence, we train the last fully-connected layer as the domain-specific layer.
Samples generating methods
We have analyzed the tracking sequences of the benchmark dataset OTB100 and VOT15 and find that the object and background are updated slowly in a wide range of scenes. They remarkably resemble each other if there is a short length of sequence between them. The changes such as deformation, occlusion and scale variation, just occur occasionally. It can be seen from the
![]()
Figure 4.Representative images selected from the Car2 sequence of VOT15. As can be seen from the three similar segment sequences, many images show little difference compared to others. When we go through at least 20 frames generally, scale variation, illumination variation, background clutter and so on can be found.
Due to the bounding-box-regression
![]()
Figure 5.The weights for the images distributed by Gaussian distribution to generate certain numbers of samples. As can be seen from the figure, the frames at the beginning and the end of the group will have less weight than those in the middle. The frames located closer to the center of the group are designed to generate more samples because they could make greater distinctions.
We assign the number of samples generated from every image in the group. Hard-negative-mining
Experiments details
Model setting
For deep learning, it requires a large number of labeled data to train. In this paper, we use the salience information to optimize the supervised learning, and test the network in the task of single object tracking. The salience information can be used as guidance for training, which explicitly shows the relationship of the object between the source image and the salience information. According to the results of salience detection, we find that the salience image is capable of providing some information such as the location of the object and partial contour. These are distinct features or individual characteristics in the original image. There is a strong correlation between the salience information and source image. From some perspectives, salience information is the lightweight feature of the image. The performance shows us that although we train our network with a less scale dataset it can get good effects to a certain degree.
Our learning algorithm aims to train a multi-domain CNN to discriminate the target and the background in any different domains. It is not straightforward because in our training data some objects will be regarded as backgrounds from different domains and vice versa. When we set up the model, it needs to process the original data and recognize the tracking objects given in the first frame. We would set this model in this way rather than consider the ground truth of the salience information as the inputs. In our view, the supervised learning with labeled data can make convolution neural network extract the features automatically. We ensure that all operations are performed on a unified scale in the phase of the network training. The salience information detection as an additional procedure of feature extraction actually strengthens the ability of the networks. It can make the network "see" like a creature observer. With the experiments we perform we can make out whether the performances of the model mainly result from the salience information or the expansion of the model.
In the phase of offline training, we use the front part of the FCNs for salience detection to accomplish the initialization of parameter. Our network is trained with the SGD method. Next, we add the samples generated with ground truth to the network training. We set the learning rate as 0.001 and the reduction ratio as 10 after 10k iterations. The momentum is set as 0.9 and the decay is set as 0.0005.
When finishing the training and coming to online tracking, we use a single layer (fc6) to replace the multiple layers domain-specific of (fc61-fc6k). We pre-train the network with the first frame of the tracking sequence and randomly initialize the last layer's weight and bias. We update the weights of the layers when estimating the position.
Experiment results
We test our algorithm on OTB50, OTB100 and UAV123 Benchmark. One pass evaluation (OPE)
The legend shows the area under the curve (AUC) score for each tracker. OTB is the open challenging long-term dataset. OTB100 is the overall data that OTB50 is selected from. The test sequences are manually tagged with 9 attributes such as illumination, scale variation, and occlusion. They represent the challenging problems awaiting solutions in visual tracking. Despite of its simplicity, our method outperforms most of the other trackers, ranking among the top. We change the amount of the training data to find out if the scale of the training data has some influence. We decrease and increase the size of the training data by 1/4 and a similar result is obtained. It's beneficial to train the MD-CNN by transfer learning with salience information. To verify the effectiveness of salience detection layers we can directly compare our results with the MD-CNN. For the optimum effectiveness of the salience detection layers, we conduct the ablation experiments on the salience extraction layers. We change the layers transferred from the FCNs to optimize the tracking results. In order to eliminate the interference of the network structure, we keep the amount and the type of the new MD-CNNs' layers constant. The test shown in
![]()
Figure 6.The Precision plots and the success plots on the OTB50 dataset.We compare the results with the change of the salience extraction layers and find three layers best in them.
The experiment of the proposed algorithm shows that salience detection improves the representing ability for the feature of MD-CNNs in visual tracking. We compare our algorithm to other classic state-of-the-art tracking algorithms such as TLD
![]()
Figure 7.The Precision plots and the success plots on the OTB50 dataset.
![]()
Figure 8.Comparison with the state-of-the-art methods on the OTB100 dataset.
![]()
Figure 9.Comparison among the proposed method and several deep-learning methods and traditional methods on UAV123.
We also compare the accuracy and the speed of our proposed method with that of other typical trackers on VOT15 datasets. For VOT15, three main measures used to analyze tracking performance are accuracy, failures and the overlap. The overlap is the proportion of the overlapping area in both object area and predicted area. If the overlap is 0, the sequence is treated as a failure. The accuracy is used to evaluate the success of the trackers. Additionally, we evaluate their speed to see if they meet real-time requirements. The structure with shallow layers takes effects on its accuracy and saves time for forward and backward propagation of the network during training. We test these algorithms under the same hardware environment. We compare our tracker with other trackers like SO-DLT
| Tracker | Accuracy | Failures | Overlap | Speed (fps) |
| Struck | 0.4129 | 103 | 0.2014 | 2 |
| DLT | 0.4345 | 113 | 0.2152 | 0.5 |
| SO-DLT | 0.5086 | 117 | 0.2006 | 6 |
| DeepSRDCF | 0.5216 | 64 | 0.2931 | 0.3 |
| SiameseFC | 0.4931 | 95 | 0.2307 | 35 |
| MD-CNNs | 0.5543 | 49 | 0.3488 | 1 |
| Ours | 0.5592 | 55 | 0.3694 | 1 |
Table 1. The testing results of our proposed method and some typical trackers on the VOT15 challenge.
In
![]()
Figure 10.The tracking examples where our proposed algorithm is compared with other trackers. As illustrated by the challenging videos, other trackers are vulnerable and sensitive to inferences caused by generic objects and background clutter while our tracker recognizes the target in the most difficult cases.
Conclusions
In this paper, an effective algorithm for visual object tracking is proposed and it further enhances the feature exploiting ability of CNN. In consideration of the problems in visual tracking, we make the trackers use the prior information by transfer learning in the sequence to distinguish the target. We combine the salience detection and deep learning in the light of their biological characteristics. We make the data processing of CNN match the information processing by human visual perception better in our methods. We change the structure of the original MD-CNNs and propose a new model. In certain aspects, we improve the original MD-CNNs and make it robust in spite of interference under certain circumstances. The final results manifest that our network provides rich features, and allows for object tracking in practical situations. We believe that our algorithm is complementary to tracking methodologies based on neuroscience principles of deep learning. Attention mechanism will present great potential by the investigation of biometric vision characteristics. Further study by integrating more information from vision attention mechanism will make the approach straightforward and better.
Acknowledgements
This work was supported by the West Light Foundation for Innovative Talents of the Chinese Academy of Sciences (CAS) (No.YA18K001). This work is done in the Signal Processing Laboratory, Institute of Optics and Electronics, CAS. We express our thanks for the experiment equipment provided by the lab. We appreciate the support of the relevant department.
Competing interests
The authors declare no competing financial interests.
References
[1] Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 4293-4302 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.465.
[2] Yang M H, Lin R S, Lim J, Ross D. Adaptive discriminative generative model and application to visual tracking: US, 7369682. 2008.
[3] Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 4312-4320 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.467.
[5] Proceedings of 2011 International Conference on Computer Vision 1156-1163 (IEEE, 2011); http://doi.org/10.1109/ICCV.2011.6126364.
[6] Wang N Y, Yeung D Y. Learning a deep compact image representation for visual tracking. In Proceedings of the 26th International Conference on Neural Information Processing Systems 809-817 (Curran Associates Inc, 2013).
[7] Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 1449-1458 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.161.
[8] Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 1373-1381 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.153.
[9] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems 1097-1105 (Curran Associates Inc, 2012).
[10] Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition 1-8 (IEEE, 2007); http://doi.org/10.1109/CVPR.2007.383267.
[11] Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition 580-587 (IEEE, 2014); http://doi.org/10.1109/CVPR.2014.81.
[12] Proceedings of 2017 IEEE International Conference on Multimedia and Expo 271-276 (IEEE, 2017); http://doi.org/10.1109/ICME.2017.8019309.
[13] Zhang L H, Ai J W, Jiang B W, Lu H C, Li X K. Saliency Detection via Absorbing Markov Chain with Learnt Transition Probability. IEEE Transactions on image processing: a Publication of the IEEE Signal Processing Society. 27 (2), 987-998 (IEEE, 2018)
[14] Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition 1597-1604 (IEEE, 2009); http://doi.org/10.1109/CVPR.2009.5206596.
[15] Proceedings of CVPR 2011 409-416 (IEEE, 2011); http://doi.org/10.1109/CVPR.2011.5995344.
[16] Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition 1265-1274 (IEEE, 2015); http://doi.org/10.1109/CVPR.2015.7298731.
[17] Proceedings of the 14th European Conference on Computer Vision 825-841 (Springer, 2016); http://doi.org/10.1007/978-3-319-46493-0_50.
[18] Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 678-686 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.80.
[20] Wang N Y, Li S Y, Gupta A, Yeung D Y. Transferring rich feature hierarchies for robust visual tracking. In Proceedings of 2015 Conference on Computer Vision and Pattern Recognition (2015).
[21] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv: 1409.1556 (2014).
[22] Proceedings of the 14th European Conference on Computer Vision 2016 472-488 (Springer, 2016); http://doi.org/10.1007/978-3-319-46454-1_29.
[23] Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition 6931-6939 (IEEE, 2016); http://doi.org/10.1109/CVPR.2017.733.
[25] Proceedings of 2011 IEEE International Conference on Acoustics, Speech and Signal Processing 1293-1296 (IEEE, 2011); http://doi.org/10.1109/ICASSP.2011.5946648.
[27] Proceedings of 2013 IEEE International Conference on Computer Vision 2192-2199 (IEEE, 2013); http://doi.org/10.1109/ICCV.2013.273.
[28] Proceedings of COMPSTAT'2010 177-186 (Springer, 2010); http://doi.org/10.1007/978-3-7908-2604-3_16.
[29] Proceedings of the 12th European Conference on Computer Vision 702-715 (Springer, 2012); http://doi.org/10.1007/978-3-642-33709-3_50
[30] Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition 2411-2418 (IEEE, 2013); http://doi.org/10.1109/CVPR.2013.312.
[32] Proceedings of 2011 International Conference on Computer Vision 263-270 (IEEE, 2011); http://doi.org/10.1109/ICCV.2011.6126251.
[33] Danelljan M, Häger G, Khan F S, Felsberg M. Accurate scale estimation for robust visual tracking. In Proceedings of British Machine Vision Conference (BMVA Press, 2014).
[34] Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition 5000-5008 (IEEE, 2017); http://doi.org/10.1109/CVPR.2017.531.
[35] Wang Q, Gao J, Xing J L, Zhang M D, Hu W M. DCFNet: discriminant correlation filters network for visual tracking. arXiv: 1704.04057 (2017).
[36] Proceedings of the 13th European Conference on Computer Vision 188-203 (Springer, 2014); http://doi.org/10.1007/978-3-319-10599-4_13.
[37] Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 1404-1409 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.156.
[38] Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition 5388-5396 (IEEE, 2015); http://doi.org/10.1109/CVPR.2015.7299177.
[40] Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops 2217-2224 (IEEE, 2017); http://doi.org/10.1109/CVPRW.2017.275.
[41] Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition 1349-1358 (IEEE, 2017); http://doi.org/10.1109/CVPR.2017.148.
[42] Proceedings of 2015 IEEE International Conference on Computer Vision 4310-4318 (IEEE, 2015); http://doi.org/10.1109/ICCV.2015.490.
[43] Proceedings of 2015 IEEE International Conference on Computer Vision Workshop 621-629 (IEEE, 2015); http://doi.org/10.1109/ICCVW.2015.84.
[44] Proceedings of the European Conference on Computer Vision 850-865 (Springer, 2016); http://doi.org/10.1007/978-3-319-48881-3_56.
[45] Proceedings of 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics 1-5 (IEEE, 2017); http://doi.org/10.1109/CISP-BMEI.2017.8302003.


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20