
Jia Chen, Jiancong Li, Yi Li, Xiangshui Miao. Multiply accumulate operations in memristor crossbar arrays for analog computing[J]. Journal of Semiconductors, 2021, 42(1): 013104
- Journal of Semiconductors
- Vol. 42, Issue 1, 013104 (2021)
Abstract
1. Introduction
Against the backdrop of exploding data volumes nowadays, traditional computing architectures are facing the von Neumann bottleneck[
In-memory computing, as the term suggests, builds the computation directly into memory, which can eliminate the large amount of data throughput that exists between the memory unit and the computing unit, significantly reducing the energy consumption generated by data migration and data access. In-memory computing shows great potential for energy saving and computing acceleration and is expected to achieve high-density, low-power, massively parallel computing systems. Meanwhile, this kind of emerging technology is still facing key challenges such as hardware resource reuse, computing-in-memory unit design, and analog computing implementation.
As it stands, the technical paths for in-memory computing can be categorized in two ways by taking the memory as the core. One is to design circuits and architecture based on traditional memory, which is usually recognized as near-memory computing[
As an important member of the emerging non-volatile memory, the memristor is a simple metal–insulator–metal (MIM) sandwich structure that can achieve resistance switching (from a high resistance state (HRS) to a low resistance state (LRS)) under external voltage biases. Therefore, memristors were widely used as resistive random access memory (RRAM, HRS for logic “0”, and LRS for logic “1”) in the early stage of research. In this short review, we do not discuss the developments of high-performance memristors through mechanism characterization, material, and device engineering that have been intensively studied; readers are referred to several comprehensive reviews[
For the application of in-memory computing, analog memristors have been researched explosively and are prospected to be provided with such following properties: (1) an analog memristor essentially represents an analog quantity, which plausibly emulates biological synaptic weights, such as the implementation of LTP, LTD, and spike-timing-dependent plasticity (STDP) functions; (2) memristors have obvious performance advantages in non-volatility, simple structure, low power consumption, and high switching speed; (3) memristors are scalable and can be expanded on a large scale in terms of high-density integration, facilitating the construction of more analog computing tasks.
In recent years, in-memory computing accelerators based on memristors have received much attention from both academia and industry. It is not just that memristor-based in-memory computing accelerators that tightly integrate analog computing and memory functions, breaking the bottleneck of data transfer between the central processor and memory in traditional von Neumann architectures. More importantly, by adding some functional units to the periphery of the memristive array, the array is able to perform MAC computing within a delay of almost one read operation without increasing with the input dimension. Meanwhile, the MAC operation is frequently used and is one of the main energy-consuming operations in various analog computing tasks, such as neural networks and equation solvers. The marriage of memristor and analog computing algorithms has given rise to a new research area, namely “memristive analog computing” or “memristive in-memory computing”.
Notably, research and practice on this emerging interdisciplinary are still in early stages. In this paper, we conduct a comprehensive survey of the recent research efforts on memristive analog computing. This paper is organized as follows.
(1) Section 1 reviews the background of in-memory computing and the concept of the analog memristor.
(2) Section 2 introduces the basic MAC unit and its implementation in the memristive cross array.
(3) Section 3 focuses on the application of memristive MAC computation in the field of neural network hardware accelerators, as a representative case of analog computing.
(4) Section 4 mainly introduces the state-of-the-art solutions for numerical computing applications based on memristive MAC operations.
(5) Section 5 discusses other extended memristive devices and the progress of their application in analog computing.
(6) Finally, we discuss some open research challenges and opportunities of memristive analog computing paradigm.
For this survey, we hope it can elicit escalating attention, stimulate fruitful discussion, and inspire further research ideas on this rapidly evolving field.
2. Multiply accumulate (MAC) operation in analog computing
2.1. Introduction of MAC operation
MAC operation is an important and expensive operation, which is frequently used in digital signal processing and video/graphics applications for convolution, discrete cosine transform, Fourier transform, and so on[
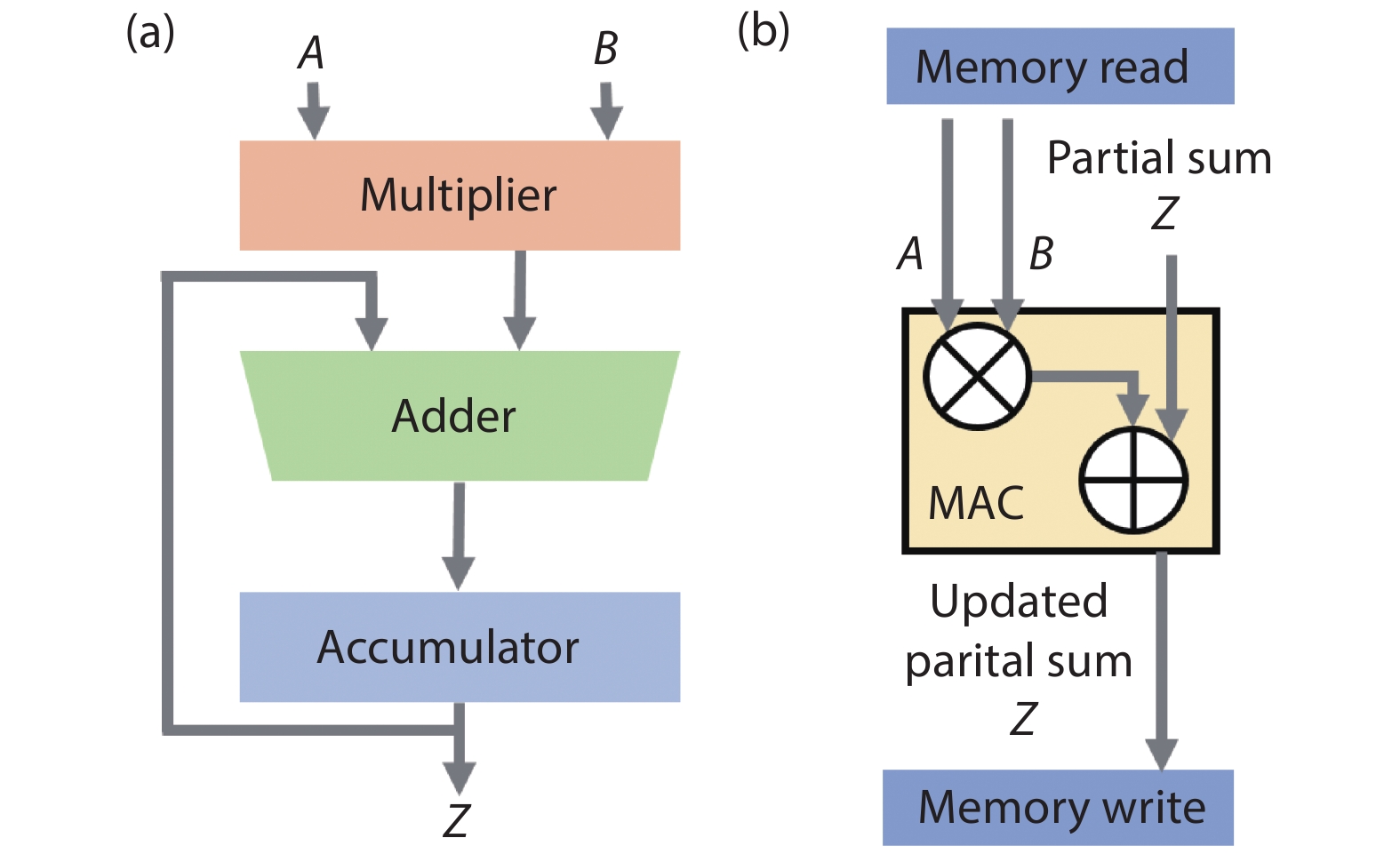
The traditional hardware unit that performs MAC operation is known as a multiplier–accumulator (MAC unit), which is a basic computing block used extensively in general digital processors. A basic MAC unit consists of multiplier, adder, and accumulator, as shown in Fig. 1(a), which occupies a certain circuit area and consumes considerable power and delay. For read and write access to memory for each MAC unit, it needs three memory reads and one memory write as shown in Fig. 1(b). Taking a typical AlexNet network model as an example, it supports almost 724 million MACs, which means nearly 3000 million DRAM accesses will be required[
![]()
Figure 1.(Color online) (a) Block diagram of the basic MAC unit. (b) Memory read and write for each MAC unit.
2.2. Implementation of MAC operation in memristor array
As a powerful alternative for improving the efficiency of data-intensive task processing in the era of big data, the in-memory computing hardware solution to the computational bottleneck is essentially a manifestation of the acceleration of MAC operations. Naturally, a memristive crossbar is highly efficient at executing vector-matrix multiplication (VMM) in one step by parallel MAC operations.
As shown in Fig. 2, for a memristive array, each row and column crossing node represents a memristor. The numerical values in a matrix can be directly mapped as the analog conductance on the crossbar array. When a forward input vector V is applied in the form of voltage pulses with different pulse amplitudes or widths to the rows, the currents collected at the columns result from the MAC operation between the input voltages and corresponding conductance nodes, following Ohm’s law and Kirchhoff’s current law. Thus, the array implements a one-step calculation of the VMM. The same goes for backpropagation. In other words, the VMM operation could be efficiently performed with O(1) time complexity.
![]()
Figure 2.(Color online) One-step vector-matrix multiplication (VMM) based on memristive array during (a) forward and (b) backward processes.
Since VMM is an essential operation in various machine learning algorithms, in the past years developing memristor-based accelerators has become one of the mainstays of hardware neuromorphic computing. As far back as 2016, Hu et al.[
![]()
Figure 3.(Color online) Reprinted from Ref. [
Hence, memristor arrays present an emerging computing platform for efficient analog computing. The ability of parallel MAC operation enables the general acceleration of any matrix operations, naturally converting into the analog domain for low-power, high-speed computation. Also, the scalability and flexibility of the array architecture make it very re-programmable and provide excellent hardware acceleration for different MAC-based applications. It is worth noting that, although the applicability of a memristor-based MAC computing system is still limited by reliability problems that arise from the immature fabrication techniques, some fault detection and error correction methods have been studied to increase technical maturity[
3. Neural network acceleration with memristive MAC operations
Neural networks are a sizable area for MAC-based hardware acceleration research. Widely employed in machine learning, neural networks abstract the human brain neuron network from the information processing perspective, and builds various models to form different networks according to different connections[
3.1. Artificial neural network (ANN)
The fully connected multi-layer perceptron (MLP) is one of the most basic artificial neural networks (ANNs), without a biological justification. In addition to the input and output layers, it can have multiple hidden layers. The simplest two-layer MLP contains only one hidden layer and is capable of solving nonlinear function approximation problem, as shown in Fig. 3(a). For memristive neural networks, the key is the hardware mapping of the weight matrices into the memristive array, as shown in Fig. 4(b), while a large amount of MAC calculation can be executed in an efficient parallel manner for acceleration. Typically, a weight with a positive or negative value requires a differential connectio of two memristive devices: W = G+ – G–, which means two memristive arrays are needed to load one weight matrix.
![]()
Figure 4.(Color online) (a) The basic structure of a fully connected artificial neural network (ANN). In a backpropagation network, the learning algorithm has two phases: the forward propagation to compute outputs, and the back propagation to compute the back-propagated errors. (b) The mapping schematic of an ANN to memristive arrays.
Thanks to the capability of the memristive array to perform VMM operations in both forward and backward directions, it can naturally implement a on-chip error-backpropagation (BP) algorithm, the most successful learning algorithm. The forward pattern information and the backward error signal can both be encoded as the corresponding voltage signal input to the array, taking the MAC computing advantage to proceed with both inference and update phases of the neural network algorithm.
In the early stages of research, many works were devoted to improving the performances of memristive devices[
(1) For the multi-level analog property of memristors, 5–6 bits are generally required for basic full-precision multi-layer perceptron[
(2) The linearity and symmetry of the bidirectional conductance tuning behavior are indeed important, both in terms of network performance and peripheral circuit friendliness. Due to the existence of device imperfections, such as read/write noises, uncontrollable dynamic conductance range, poor retention, and low array yield, the analog conductance tuning behaviors still need to be improved for better reliability. For memristor-based neural network inference engines, the accurate write-in method and the retention property of multi-level states become significant.
(3) A simple crossbar array can cause many practical problems, including IR drop, leakage current, etc. These cannot be ignored in hardware design, especially the voltage sensing errors caused by IR drop.
Until recently, there have been many breakthroughs in the on-chip hardware implementation of memristive ANN. As shown in Figs. 5(a)–5(c), Bayat et al. demonstrated a mixed-signal integrated hardware chip for a one-hidden layer perceptron classifier with a passive 0T1R 20 × 20 memristive crossbar array[
![]()
Figure 5.(Color online) Reprinted from Ref. [
A memristive ANN chip for face recognition classification was also presented by Yao et al.[
Taking the functional completeness of the memristive ANN chips into account, a fully integrated, functional, reprogrammable memristor chip was proposed[
![]()
Figure 6.(Color online) Reprinted from Ref. [
In total, from device array fabrication, core architecture design, peripheral circuit solutions, and overall system functionality improvement, the development of memristive ANN chips is maturing. With the summation property of neural networks, non-ideal factors such as the unmitigated intrinsic noise of memristor arrays will not completely constrain the development of memristive ANN chips, which suggests the adaptability of memristors to low-precision computing tasks. Based on non-volatile and natural MAC parallel properties of memristive arrays, the memristive ANN chips benefit from high integration, low power consumption, high computational parallelism, and high re-programmability, which have great promise in the field of analog computing.
3.2. CNN/DNN
As the amount of data information explodes, traditional fully-connected ANNs exhibit their information processing limitations. For example, there are 3 million parameters when processing a low-quality 1000 × 1000 RGB image, which is very resource-intensive. The proposal of the convolutional neural network (CNN) greatly improves this problem. The CNN performs two main features: firstly, it can effectively reduce a large amount of parameters, including simplifying the input pattern and lowering the weight volume in the network model; then, it can effectively retain the image characteristics, in line with the principles of image processing.
CNN consists of three main parts: the convolutional layer, the pooling layer, and the fully connected layer. The convolutional layer is responsible for extracting local features in the image through the filtering of the convolutional kernel; the pooling layer is used to drastically reduce the parameter magnitude (downscaling), which not only greatly reduces the amount of computation but also effectively avoids overfitting; and the fully connected layer is similar to the part of a traditional neural network and is used to output the desired results. A typical CNN is not just a three-layer structure as mentioned above, but a multi-layer structure, such as the structure of LeNet-5 as shown in Fig. 7(a)[
![]()
Figure 7.(Color online) (a) Basic structure of LeNet-5. (b) Schematic of convolution operation in an image. (c) Typical mapping method of 2D convolution to memristive arrays.
Based on the investigation of memristive ANN, memristive CNN can also be accelerated due to the parallel MAC operations, and the effect of memristive devices on CNN has similar conclusions, such as ideal linearity, symmetry, smaller variation, better retention and endurance[
As shown in Fig. 7(b), it is the basic principle of the image convolution operation. By sliding the convolution kernels over the image, the pixel value of the image is multiplied by the value on the corresponding convolution kernels, and then all the multiplied values are added as the grayscale value of the corresponding pixel point in the feature map until the entire convolution process is done. The most commonly used mapping method on memristive arrays is to store the weights of the convolutional kernels in the array. Specifically, as shown in Fig. 7(c), a column of the memristive array is used to store a convolutional kernel, the two-dimensional image is unrolled as a one-dimensional input voltage signal, and the information of the convolutional feature image is obtained as the output current value of the array.
As shown in Fig. 8(a), Gao et al. firstly implemented convolution operation on a 12 × 12 memristor crossbar array in 2016[
![]()
Figure 8.(Color online) Reprinted from Ref. [
Although the preliminary implementation of convolution operation on 2D and 3D memristive arrays has been achieved, this mapping approach still has significant concerns. First, the conversion of a 2D matrix to 1D vectors losses the structural information of the image, which is still important in the subsequent process, and also causes very complex data processing in the back-propagation process. Secondly, if the one-shot MAC operation of one-dimensional image information is required for convolution, the memristive array is sparsely stored for convolution kernels, and too many unused cells could cause serious sneak path issues. While compact kernels on arrays without any redundancy space require more complex rearrangements of the input image and sacrifice significant time delays and peripheral circuits for convolution operation. In one word, the problem of convolutional operation raises challenges that need to be properly addressed while training memristive CNNs.
Recently, to solve the severe speed mismatch between the memristive fully connected layer and convolutional layer, which comes from the time consumption during the sliding process, Yao et al. proposed a promising way of replicating the same group of weights in multiple parallel memristor arrays to recognize an input image efficiently in a memristive CNN chip[
![]()
Figure 9.(Color online) Reprinted from Ref. [
A more recent work by Lin et al. has demonstrated a unique 3D memristive array to break through the limitations of 2D arrays that can only accomplish simplified interconnections[
It can be seen that to improve the efficiency of a memristive CNN, various mapping methods for memristive arrays are being actively explored, including multiplex and interconnection of multiple small two-dimensional arrays, or specially designed 3D stacking structures. In addition to considering the mapping design of the memristive array cores, the peripheral circuit implementation of memristive CNN is another important concern, which also determines the performance and efficiency of the system to a large extent. While memristive arrays are conducive to efficient analog computing, the consumed ADCs and DACs come at a cost. Moreover, due to the severe resistive drift, the accurate readout circuit is also worthy of further investigation.
Chang et al. have placed their effort on circuit optimization for on-chip memristive neural networks. They proposed an approach of efficient logic and MAC operation on their fabricated 1Mb 1T1R binary memristive array. As shown in Figs. 10(a) and 10(b), the structure of the fully integrated memristive macro included a 1T1R memristor array, digital dual-mode word line (WL) drivers (D-WLDRs), small-offset multi-level current-mode sense amplifiers (ML-CSAs), and a mode-and-input-aware reference current generator (MIA-RCG). Specifically, D-WLDRs, which replaced DACs, were used to control the gates of the NMOS transistors of 1T1R cells sharing the same row. Two read-out circuit techniques (ML-CSAs and MIA-RCG) were designed. Thus, high area overhead, power consumption, and long latency caused by high-precision ADCs could be eliminated; reliable MAC operations for the small sensing margin caused by device variability and pattern-dependent current leakage could be enhanced. Based on such circuit optimization, a 1-MB memristor-based CIM macro with 2-bit inputs and 3-bit weights for CNN-based AI edge processors was further developed[
![]()
Figure 10.(Color online) Reprinted from Ref. [
3.3. Other network models
Based on the parallel MAC computing in an array, more memristive neural network models have been investigated. One example is the generative adversarial network (GAN), which is a kind of unsupervised learning by having two neural networks play against each other to learn itself. GAN has two subnetworks: a discriminator (D) and a generator (G), as illustrated in Fig. 11(a). Both D and G typically are modeled as deep neural networks. In general, D is a classifier that is trained by distinguishing real samples from generated ones and G is optimized to produce samples that can fool the discriminator. On the one hand, two competing networks are simultaneously co-trained, which significantly increases the need for memory and computation resources. To address this issue, Chen et al proposed ReGAN, a memristor-based accelerator for GAN training, which achieved 240× performance speedup compared to GPU platform averagely, with an average energy saving of 94×[
![]()
Figure 11.(Color online) Reprinted from Ref. [
Another example is the long short-term memory (LSTM) neural network, which is a special kind of recurrent neural network. LSTM is proposed to solve the "gradient disappearance" problem, and is suitable for processing and predicting events with relatively long intervals and delays in a time series. By connecting a fully connected network to a LSTM network, a two-layer LSTM network is illustrated in Fig. 11(b). Traditional LSTM cells consist of a memory cell to store state information and three gate layers that control flow of information within cells and network. The LSTM network with significantly increased complexity and a large number of parameters have a bottleneck in computing power resulting from both limited memory capacity and bandwidth. Hence, besides the implementation of the fully connected layer, memristive LSTM pays more attention to store a large number of parameters and offer in-memory computing capability for the LSTM layer, as shown in Fig. 11(c). Memristive LSTMs have been demonstrated for gait recognition, text prediction, and so on[
4. Memristor-based MAC for numerical computing
In previous sections, we introduced the acceleration of various neural networks by using MAC operations with low computation complexity in arrays. As shown in Fig. 12, in general, these neuromorphic computing and deep learning tasks can be considered to be “soft” computations[
![]()
Figure 12.(Color online) The application landscape for in-memory computing[
To date, the accuracy of analog MAC operation in a memristor array is still relatively limited, so building an accelerator suitable for numerical computation, as an interesting topic, remains a great challenge and, again, an excellent opportunity to further develop potential application scenarios for memristive in-memory computing. In view of this, in recent years, some remarkable technological solutions have been proposed, achieving new breakthroughs from principle to verification.
4.1. Mixed-precision architecture
Typically, to reach the numerical accuracy usually required for a digital computer to execute the data analytics and scientific computing. For the memristor-based MAC processer, the limitations arising from the device non-ideal factors must be addressed.
Le Gallo et al. introduced a mixed-precision in-memory computing architecture, to process the numerical computing tasks[
In this hybrid system, the memristor process unit performs the bulk of MAC operations, as the digital computer implements a backward method to improve the calculation accuracy and provides other mathematical operations like iteration (Fig. 13(a)). To illustrate the concept, the process of solving linear equations was shown.
![]()
Figure 13.(Color online) Illustration of the hybrid in-memory computing[
Solving the linear equations is to find an unknown vector
The matrix A is known as the coefficient matrix and is a non-singular matrix, the b is also known as a column vector.
An iterative refinement algorithm was utilized in the mixed precision architecture. An initial solution was chosen as the start point, and the solving algorithm iteratively updated with a low precision error-correction term z by solving the equation
Experimentally, a prototype memristive MAC chip containing one million phase-change memory (PCM) array, which consists of 512 world lines and 2048 bit lines, was used to construct the low precision computing unit. Since the current is a non-linear function in the PCM, a ‘pseudo’ Ohm’s law was employed in the MAC operation:
The
As the main application of this work was to solve the dense covariance matrix problems, a practical problem in which the coefficient matrix A is based on real-world RNA data was used to test the mixed-precision computer. By using the iterative refinement method and the ‘pseudo’ Ohm’s law, the mixed-precision computer is capable of solving a linear system with 5000 equations, the achievable speedup comes from reducing the number of iterations need to solve the problems and result in overall computational complexity of O(N2) for an N × N matrix, which is usually O(N3) in traditional numerical algorithms.
Moreover, the energy efficiency of the mixed-precision computer has been further estimated by the research team. The energy efficiency of a fully integrated mixed-precision computer is 24 times higher than the state-of-the-art CPU/GPU to deal with 64-bit precision problems. Their results also show that the PCM chip offers up to 80 times lower energy consumption than the field-programmable gate array (FPGA) when dealing with low-precision 4-bit MAC operations.
As this mixed-precision computer can outperform the traditional von Neumann computer in terms of energy consumption and processing speed. How to extend this architecture and method of solving linear equations to more applications such as optimization problem, deep learning, signal processing, automatic control, etc. in the future deserves further in-depth study.
4.2. Matrix slice and bit slice
The mixed-precision in-memory computing has been verified to be able to improve the MAC calculating accuracy, but the scale of the matrix that can be processed by the MAC unit is still limited by the scale of the memristive array. Moreover, as the array size increases, the impact of intra-device variation and other problems such as the I-R drop will come to the fore.
Zidan et al. recently introduced a high-precision general memristor based partial differential equation (PDE) solver, in which multiply small memristive arrays were used to solve both the static and time-evolving partial differential equations[
As the partial differential systems usually contain hyper dimensional matrices, especially for high-precision solution. For example, a 2-D partial system that is divided to 100 × 100 coarse grids can lead to a coefficient matrix with
![]()
Figure 14.(Color online) Reprinted from Ref. [
A complete hardware platform and software package were implemented for the experimental test. Ta2O5–x memristor arrays were integrated on a printed circuit board (PCB) to store the partial differential coefficient matrix and execute the MAC operation. The Python software package provided the system level operations including matrix slices, high-precision matrix mapping, and the iteration process control. The software package also presented the interface between the hardware and end user for data input/output. To test the performance of the general solver, a Poisson’s equation and a 2-D wave equation were used as the static and time-evolving solution examples. Besides, the PDE solver was inserted into the workflow of a plasma-hydrodynamics simulator to verify its applicability. Benefiting from the architecture-level optimizations such as the precision-extension techniques, the PDE solver can perform computations achieving 64-bit accuracy.
The introduction of the matrix and bit slice technique can also substantially improve the energy efficiency of the in-memory MAC unit to execute sparse matrix computation. The energy efficiency of a 64-bit fully integrated memristor matrix slice system was reported to have achieved 950 GOPs/W, whereas the energy efficiency of the state-of-art CPU and GPU to process a sparse matrix with the same accuracy requirement is 0.3 GOPs/W (Intel Xeon Phi 7250) and 0.45 GOPs/W (NVIDIA Tesla V100)[
Note that the matrix slice method can only be used for systems with sparse coefficient matrix with limitation in reconfigurability. Although the bit-slice technique already shows the ability to improve the accuracy of the analogue MAC operation, to control multiple crossbar arrays will increase the system complexity.
4.3. One-shot operation for numerical computing
To further reduce the dependence on the von Neumann computer or software package. Sun et.al recently demonstrated a pure in-memory computing circuit based on the memristor MAC unit to process linear algebra problems. With a feedback structure, the computing circuit has the ability to implement solving linear equation in the so-called “one-shot operation” and O(1) time complexity can be achieved[
Basically, solving linear equations usually requires a large number of iterations in the mathematical solution algorithms. The in-memory solver based on the numerical algorithms will also be suffering from the performance degradation due to the data transfer between the digital processing unit and in-memory processing unit during the iterative cycles. The “one-shot” solvers, on the construct, based on the inevitability of coefficient matrix A and motivated by the circuit principles, can eliminate the limitation of the numerical iteration.
Fig. 15(a) clearly illustrated this proposed in-memory computing circuit. The array performed the MAC operation
![]()
Figure 15.(Color online) Reprinted from Ref. [
Thus, to solve the linear equations
As device conductance can only map positive elements, to solve equations with both positive and negative elements, another memristive array was connected to the circuit with the inverting amplifiers (Fig. 15(c)). The coefficient matrix A was splinted into two positive matrices, B and C. The matrix
Eigenvector calculation could also be implemented in the one-step operation. To solve the eigenvector equation
A 3 × 3 Ti/HfO2/C memristive array was experimentally used to construct these one-shot computing circuits. The real-world data was also used to test the performance of the circuits, a 100 × 100 memristive array based on a memristive device model was constructed for simulation to solve the 1-D steady-state Fourier equation. This partial differential equation was converted to a linear form by the finite difference method. A 1-D time-independent Schrödinger equation also was solved in the simulation with the same scale memristive array to test the performance of the eigenvector solution. Moreover, the eigenvector computing circuit can accelerate the PageRank algorithm with significant improvements in speed and energy efficiency for practical big-data tasks, such as the Havard 500 data set.
Based on the feedback amplifiers theory and the circuit dynamics, further analysis results showed that only if the minimal eigenvalue (or real part of eigenvalue)
As the computing time is free of the N-dependence, the “one-shot solver” can significantly boost the computing performance and realize high energy efficiency, especially in the scene of processing data-intensive tasks. Take the eigenvector solution circuit as an example, its energy efficiency achieves 362 TOPs/W when running the PageRank algorithm for a 500 × 500 coefficient matrix. Compared to the energy efficiency of 2.3 TOPS/W of the tensor processing unit (TPU), the in-memory direct solver provides 157 times better performance.
Although these “one-shot” circuits require a high-performance device to improve the computing accuracy, this work shows great potential to process numerical problems with high process speed (O(1) time-complexity) and low energy consumption. This circuit is particularly suited to those scenarios that require high process speed and low energy consumption but low precision. However, as the implementation of the one-shot computing circuit is hardwired, the scalability of these computing circuits should be further improved.
4.4. Short conclusion
Although the approximate solutions are sufficient for many computing tasks in the domain of machine learning, the numerical computing tasks, especially the scientific computing tasks pose high requirement on high precision numerical results. To evaluate the overall performance of an in-memory system for numerical computing, the system complexity, computational time complexity, computing accuracy, and energy/area efficiency need to be considered in a comprehensive manner.
Taking advantage of sparsity, the matrix slice processor has shown a good potential to process a giant sparse matrix by using multiply small-scale arrays with high processing speed and low energy consumption. Combining this with the traditional bit-slice technique, a high precision solution can be obtained. This technique can also be used to expand the application of the traditional flash memory to process numerical missions[
By combining a von Neumann machine with the memristive MAC unit, the mixed-precision in-memory computing architecture already overperforms the CPU/GPU-based numerical computers in terms of the energy consumption and computation speed, with the same accuracy level to process giant non-sparse matrices. The mixed-precision system still suffers from the fact that the data needs to be stored both in the memristor array and the high-precision digital unit. Additional resources are needed to solve the problem. Although O(N2) computation time complexity can be achieved, it still depends on the matrix scale.
With the fastest process speed and highest energy/area efficiency, the one-shot in-memory computing architecture is another good example of the powerful capability of the memristive MAC unit, and can even outperform the quantum computing accelerator in computation complexity[
For further development of the memristor-based numerical computation system, the first issue is to improve the programming precision of the memristors. Besides, at the algorithmic level, how a range of important numerical algorithms such as matrix factorization can be implemented efficiently in a memristive MAC unit remains a challenge. These recent breakthroughs mainly focused on the non-singular linear equations, we believe the solution of singular linear equations, non-linearity equations, and ordinary differential equations, etc. also deserve attention. After that, we can envisage the construction of a universal equation solver and even develop it to a universal numerical processor.
5. MAC operation in other nonvolatile devices
As one of the representatives of the emerging non-volatile devices, the memristor, based on the analog property and the parallel MAC computing, demonstrates the hardware acceleration in different fields, from low-precision neural networks to numerical analysis with high precision requirements. Since the core idea is to store and update nonvolatile conductance states in a high-density nano-array, it is naturally easy to think that other nonvolatile devices could be used to perform similar functions, although based on different physical mechanisms.
In past decades, many other types of non-volatile devices, such as phase change memory (PCM), magnetic tunneling junctions, ferroelectric field effect transistors (FeFETs), and floating gate transistors have been intensively studied for high-performance memory application. Recently, many studies have proved that these devices can perform MAC operations and thus accelerate computing.
Phase change memory (PCM) works by the transformations of the crystalline phase (LRS) and amorphous phase (HRS) of the chalcogenide material as its basic principle. The RESET process of PCM is relatively abrupt due to the melting and rapid cooling of the crystalline, and the naturally asymmetric conductance tuning leads to a more complex synaptic unit. To realize the bi-directional analog conductance modulation as a synaptic device, generally, two PCMs are seen as one synaptic unit, while only the analog SET process is used to implement the LTP or LTD process[
![]()
Figure 16.(Color online) Emerging analog computing based on (a) phase change memory (PCM)[
Ferroelectric devices tune the device resistance by reversibly switching between the two remnant polarized states. FeFET is a three-terminal device and uses a ferroelectric thin film as the gate insulator, which is highly compatible with the CMOS process. The multi-domain polarization switching capability of a polycrystalline ferroelectric thin film can be utilized to modulate FeFET channel conductance, thus the multi-conductance levels can be used in analog computing[
The floating-gate transistors modulate the channel current by controlling the amount of charge stored in the floating gate. The channel conductance could represent the analog synaptic value. NOR flash and NAND flash have been maturely used in neural network hardware implementations. Relying on mature memory peripheral circuits and mass production ability, some neuromorphic chips based on flash memory have been demonstrated. Representatively, Lee et al. have put forward a novel 2T2S (two transistors and two NAND cell strings) synaptic device capable of XNOR operation based on NAND flash memory, and implemented a high-density and highly reliable binary neural network (BNN) without error correction codes[
6. Conclusions and outlook
MAC operation based on memristors or memristive devices is now becoming a prominent subject of research in the field of analog computing. In this paper, we have discussed two niche areas of applications of this low computation complexity, energy-efficient in-memory computing method based on physical laws. Memristive neural network accelerators have been intensively demonstrated for various network structures, including MLP, CNN, GAN, LSTM, etc., with high tolerance to the imperfections of the memristors. In addition, significant progress has been made in numerical matrix computing with memristive arrays, which sets a solid foundation for future high-precision computation. Several representative memristive applications have been illustrated in Table 1 to show the superiority at efficiency.
Further studies are needed to understand the physics of memristors and optimize the device performance. While the traditional application of memristors in the field of semiconductor memory focuses on the binary resistive switching characteristics, MAC operation and analog computing put forward high requirements on the analog characteristics of the device. Unfortunately, the device operation relies on the physical mechanism of conductive filament formation and disruption, making it very difficult to obtain high-precision, highly uniform, linear and symmetric conductance regulation. Although for neural networks, some degree of conductance write/read variation and noise and other reliability issues (such as yield, state drift, and device failure) could be tolerated, for numerical computation, these flaws all lead to a dramatic reduction in computation accuracy. Besides, the conductance tuning operation, power consumption, scalability, etc. all need to be improved before the memristor can be taken a step forward to practical applications. For this purpose, advances in both theoretical and experimental knowledge are required, which not only help with better control of the conductive filament evolution and stability but also provide guidance in material selection, device structure optimization, and fabrication process development. In other words, a complete picture of the resistive switching mechanisms will be desirable. First principle models to predict and reveal the nature of filaments are essential. Experimental probes that can uncover the real-time dynamic electronic and ionic processes under external stimulus are also valuable to form an in-depth understanding. Beyond the fundamental device level, efforts are required to scale it up to array and chip-scale with high yield. The intra-device variation should be well controlled, the I-R drop issue and other parasitic effects should be taken into account. The integration with specially designed peripheral circuits for targeted applications, such as compact neuron circuits, analog-digital and digital-analog converters, is of equally importance.
Meanwhile, the design and optimization of the matrix computation algorithm require more dedicated attention to make them synergistic with the development of high-performance devices. First, deep learning and other machine learning techniques have pushed AI beyond the human brain in some application scenarios like image and speech recognition, but the scale of the network is too large from a hardware implementation perspective, requiring the storage of network parameters far beyond the capabilities of today’s memristor technology. As a result, the development of the memristive network compression method, such as quantization and distillation, becomes particularly important, especially for edge-end IOT devices with limited computing resources. Secondly, whether we can develop universal equation solvers based on memristor arrays, or even scientific computing cores, remains an open question. It is certainly easier to start with some basic and important matrix computations. When it comes to more complex and large-scale problems, it still takes longer and more committed exploration. It will be interesting to see numerical computing processing unit built by memristors to complement or replace the high-precision CPU or GPU in specific applications. In addition, the re-configurability of the computing system would be another direction worth exploring. This means the “soft” neural network acceleration and the “hard” numerical computing can be performed arbitrarily in the same memristor-based in-memory computing system, depending on the needs and definition of the user.
Overall, analog computing in memristive crossbar arrays have proven to be a promising alternate to existing computing paradigms. It is believed that memristors and their intriguing in-memory computing capability will continue to attract increasing attention in the coming era of artificial intelligence. We point out here that only through concerted effort in the device, algorithm, and architecture levels can we see applied memristive computing systems in everyday life in the 2020s.
Acknowledgements
This work is supported by the National Key Research and Development Plan of MOST of China (2019YFB2205100, 2016YFA0203800), the National Natural Science Foundation of China (No. 61874164, 61841404, 51732003, 61674061), and Hubei Engineering Research Center on Microelectronics. The authors thank Yifan Qin, Han Bao, and Feng Wang for useful discussions.
References
[1] Can programming be liberated from the von Neumann style. Commun ACM, 21, 613(1978).
[2] Moore’s law. Electron Magaz, 38, 114(1965).
[3] Moore's law: Past, present and future. IEEE Spectr, 34, 52(1997).
[4] Fifty years of Moore's law. IEEE Trans Semicond Manufact, 24, 202(2011).
[5] The chips are down for Moore's law. Nature, 530, 144(2016).
[6] Hitting the memory wall. SIGARCH Comput Archit News, 23, 20(1995).
[7] In-memory computing with resistive switching devices. Nat Electron, 1, 333(2018).
[8] et alMixed-precision in-memory computing. Nat Electron, 1, 246(2018).
[9] The building blocks of a brain-inspired computer. Appl Phys Rev, 7, 011305(2020).
[10] et alMemory devices and applications for in-memory computing. Nat Nanotechnol, 15, 529(2020).
[12] et alEmerging memory devices for neuromorphic computing. Adv Mater Technol, 4, 1800589(2019).
[13] et alDevice and materials requirements for neuromorphic computing. J Phys D, 52, 113001(2019).
[16] et alA review of near-memory computing architectures: Opportunities and challenges. 2018 21st Euromicro Conference on Digital System Design (DSD), 608(2018).
[19] et alDaDianNao: A machine-learning supercomputer. 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, 609(2014).
[20] et alLoihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro, 38, 82(2018).
[22] Memristor – The missing circuit element. IEEE Trans Circuit Theory, 18, 507(1971).
[23] et alPhase change memory. Proc IEEE, 98, 2201(2010).
[24] et alFerroelectric memories. Ferroelectrics, 104, 241(1990).
[26] et alResistive switching materials for information processing. Nat Rev Mater, 5, 173(2020).
[30] et alHigh-speed and low-energy nitride memristors. Adv Funct Mater, 26, 5290(2016).
[33] High speed and area-efficient multiply accumulate (MAC) unit for digital signal prossing applications. 2007 IEEE International Symposium on Circuits and Systems, 3199(2007).
[34] Review on multiply-accumulate unit. Int J Eng Res Appl, 7, 09(2017).
[36] Efficient posit multiply-accumulate unit generator for deep learning applications. 2019 IEEE International Symposium on Circuits and Systems (ISCAS), 1(2019).
[38] ImageNet classification with deep convolutional neural networks. Commun ACM, 60, 84(2017).
[39] et alDot-product engine for neuromorphic computing: Programming 1T1M crossbar to accelerate matrix-vector multiplication. 2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC), 1(2016).
[43] et alTheory study and implementation of configurable ECC on RRAM memory. 2015 15th Non-Volatile Memory Technology Symposium (NVMTS), 1(2015).
[44] Low power memristor-based ReRAM design with Error Correcting Code. 17th Asia and South Pacific Design Automation Conference, 79(2012).
[45] Multilayer feedforward networks are universal approximators. Neural Networks, 2, 359(1989).
[46] Deep learning. Nature, 521, 436(2015).
[47] et alPhoto-realistic single image super-resolution using a generative adversarial network. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 105(2017).
[48] Long short-term memory. Neural Comput, 9, 1735(1997).
[50]
[51] et alFathom: reference workloads for modern deep learning methods. 2016 IEEE International Symposium on Workload Characterization (IISWC), 1(2016).
[56] Memristive crossbar arrays for brain-inspired computing. Nat Mater, 18, 309(2019).
[59] et alResistive memory device requirements for a neural algorithm accelerator. 2016 International Joint Conference on Neural Networks (IJCNN), 929(2016).
[67] A quantized training method to enhance accuracy of ReRAM-based neuromorphic systems. 2018 IEEE International Symposium on Circuits and Systems (ISCAS), 1(2018).
[68] et alBinary neural network with 16 Mb RRAM macro chip for classification and online training. 2016 IEEE International Electron Devices Meeting (IEDM), 16.2.1(2016).
[70] et alFace classification using electronic synapses. Nat Commun, 8, 15199(2017).
[71] et alA fully integrated analog ReRAM based 78.4TOPS/W compute-in-memory chip with fully parallel MAC computing. 2020 IEEE International Solid- State Circuits Conference (ISSCC), 500(2020).
[73]
[75]
[76] et alDeep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770(2016).
[77] et alError-reduction controller techniques of TaO
[87] et alFully hardware-implemented memristor convolutional neural network. Nature, 577, 641(2020).
[90]
[91] et alDemonstration of generative adversarial network by intrinsic random noises of analog RRAM devices. 2018 IEEE International Electron Devices Meeting (IEDM), 3.4.1(2018).
[93]
[95] et alMemristive LSTM network for sentiment analysis. IEEE Trans Syst Man Cybern: Syst, 1(2019).
[97] et alA parallel RRAM synaptic array architecture for energy-efficient recurrent neural networks. 2018 IEEE International Workshop on Signal Processing Systems (SiPS), 13(2018).
[99]
[102]
[104] et alIn-memory eigenvector computation in time O (1). Adv Intell Syst, 2, 2000042(2020).
[105]
[107] et alMemristive and CMOS devices for neuromorphic computing. Materials, 13, 166(2020).
[109] et alFerroelectric FET analog synapse for acceleration of deep neural network training. 2017 IEEE International Electron Devices Meeting (IEDM), 6.2.1(2017).
[110] et alFast, energy-efficient, robust, and reproducible mixed-signal neuromorphic classifier based on embedded NOR flash memory technology. 2017 IEEE International Electron Devices Meeting (IEDM), 6.5.1(2017).
[112] et alPhase change memory as synapse for ultra-dense neuromorphic systems: Application to complex visual pattern extraction. 2011 International Electron Devices Meeting, 4.4.1(2011).
[115] et alAccelerating deep neural networks with analog memory devices. 2020 IEEE International Memory Workshop (IMW), 1(2020).
[118]
[119] et alExploiting hybrid precision for training and inference: A 2T-1FeFET based analog synaptic weight cell. 2018 IEEE International Electron Devices Meeting (IEDM), 3.1.1(2018).
[120] et alHigh-density and highly-reliable binary neural networks using NAND flash memory cells as synaptic devices. 2019 IEEE International Electron Devices Meeting (IEDM), 38.4.1(2019).
[121]
[123] et alStorage reliability of multi-bit flash oriented to deep neural network. 2019 IEEE International Electron Devices Meeting (IEDM), 38.2.1(2019).

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20