
Pengfei Xu, Zhiping Zhou, "Silicon-based optoelectronics for general-purpose matrix computation: a review," Adv. Photon. 4, 044001 (2022)
- Advanced Photonics
- Vol. 4, Issue 4, 044001 (2022)
Abstract
Keywords
1 Introduction
Silicon-based optoelectronics is a rapidly developing technology that aims to heterogeneously integrate photonic, optoelectronic, and electronic devices and circuits on a silicon substrate (photonic-electronic integration) to form a large-scale comprehensive on-chip system.1 Since the modulation bandwidth of silicon optical modulators exceeded 1 GHz in 2004,2 the data bitrate of transmission has been continuously increasing. Due to advantages in manufacturing cost and mass production, silicon-based optoelectronics are becoming one of the mainstream solutions in both high-speed telecommunications and data center interconnections.3
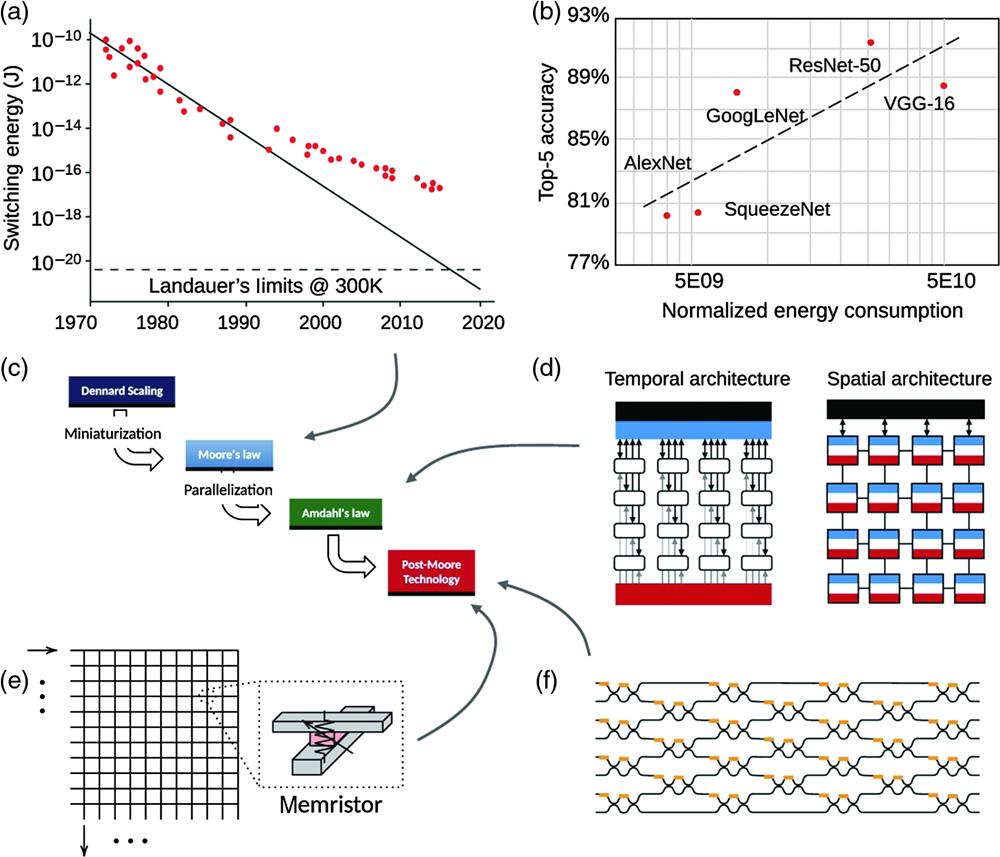
In past decades, artificial neural network (ANN) became a popular model for image classification, pattern recognition, and prediction in many disciplines. Unlike neuromorphic computing (build neural dynamics models, mimic natural neural networks, train the plasticity of synapses, and aim at lower energy consumption brain-like artificial intelligence), ANN adopts an aggressive accuracy-driven strategy in its software research and development. Innovative ANN models, like the convolution (CONV) neural network (ALEXNET,12 VGG,13 RESNET,14 etc.) and the recurrent neural network (long short-term memory15), are proposed to achieve more accurate results. Although ANN models made revolutionary progress in artificial intelligence, the overall floating-point operations (FLOPs) of ANN models have been increasing exponentially. The parameters of these high-accuracy models are generally more than billions (or even trillions) of model parameters. The ANN model training process also requires a lot of matrix computations, which usually take several weeks in cloud data centers with large amounts of data, thereby increasing the software development life cycle. Notably, due to the slowdown of complementary metal–oxide–semiconductor (CMOS) technology scaling, Moore’s law no longer seems to apply, and the switching energy of a single transistor deviates from the law’s expectations16 [in Fig. 1(a)]. It is becoming increasingly difficult to reduce the minimum feature size of transistors and improve the single-core performance, which is limited by clock speed and energy efficiency of digital logic circuits, whereas the accuracy-driven ANN models demand higher requirements of the computation performance of the processors. Figure 1(b) shows the model accuracy versus normalized energy consumption of typical ANN models. To further increase the model accuracy in classification, model training and execution often tend to consume exponentially more electricity.17
![]()
Figure 1.Development of processors for matrix computation. (a) Moore’s law no longer seems applicable.
In recent decades [in Fig. 1(c)], multicore parallel processing electronic processors,18 including temporal architectures [e.g., graphics processing unit (GPU) based on the single-instruction multiple-data execution model] and spatial architectures [e.g., tensor processing unit (TPU) based on systolic arrays21], became the mainstream solutions for accelerating large scale matrix computations in ANNs, combinatorial optimization, compressed sensing, and digital signal processing17 [in Fig. 1(d)]. However, as suggested by Amdahl’s law,22 the overall performance gain from multicore parallelization is limited by diminishing returns; electronic processors also suffer from the tremendous energy consumption of the digital transceiver circuits during high-capacity communication with memory, storage, and peripheral hardware. In Von Neumann architecture23 processors, during computation, data and instructions need to be sent to the processor via input/output (I/O) connections. The energy consumption of digital transmitter and receiver circuits is equivalent to or much greater than the energy consumption of transistors for computation in digital logic circuits. The data connections’ energy consumption reaches the
Sign up for Advanced Photonics TOC. Get the latest issue of Advanced Photonics delivered right to you!Sign up now
Since electronic processors are approaching their limits, in post-Moore’s law era, emerging potential analog computation paradigms, like in-memory computing25 and optical computing, are being considered to surpass the performance bottleneck of electronic processors.26 For example, memristor crossbar arrays [in Fig. 1(e)] are a typical example of the in-memory computing paradigm,19 and silicon-based optoelectronic matrix computation based on integrated waveguide meshes is a typical example of optical computing [in Fig. 1(f)]. Silicon-based optoelectronic matrix computation has the following distinct characteristics and is showing great capabilities and feasibilities, which we will detail in the up-coming sections.
2 Recent Progress in Silicon-Based Optoelectronic Matrix Computation
Electronic processors are the mainstream and almost invincible hardware for general-purpose computation. Most of the novel research in optical computing published recently can easily be defeated by digital logic circuits in terms of energy efficiency, manufacturing cost, and reliability. Even a smartphone can run complex artificial intelligence applications with extremely low power consumption.27 Unlike versatile and multi-purpose electronic processors, optical computing has difficulty achieving complex and diverse functionalities by simply arranging and combining basic logical units (just like digital logic circuits consisting of billions of transistors). Optical computing usually needs to take advantages or specific characteristics of light waves,28 such as optical field transformation and coherent detection. By combining electronic, photonic, and optoelectronic devices and circuits together on a silicon substrate, silicon-based optoelectronic matrix computation is one of the few general-purpose computations that have the potential to surpass the computation performance of the digital logic circuits in terms of energy efficiency, computational power, latency, and maintainability. In this section, we will review the recent studies in photonic matrix computation, including matrix-vector multiplication (MVM), CONV, and MAC operation. These computations are closely interrelated, e.g., both MVM and CONV can be achieved by a series of MAC operation; the CONV between filters and kernel can be deployed in an MVM processor (in Fig. 2).
![]()
Figure 2.Intuitive visualization showing energy-efficient models processing in the convolutional neural network. The CONV between the filters and kernel can be deployed into the MVM to improve efficiency.
2.1 Integrated Waveguide Meshes for MVM
Although nowadays it is possible to achieve quantum information processing (QIP) up to tens of qubits, there are still some inconveniences (e.g., a large amount of space required, need a lot of discrete optics, work at low temperatures) in achieving large scale unitary transformation to the quantum states (i.e., programming). In 2007, the first photonic integrated two-qubit control-NOT (CNOT) gate [in Fig. 3(b)] for QIP was demonstrated on a silicon chip.30 Compared with the bulk-optical setup [in Fig. 3(a)],29 integrated waveguide meshes are more robust for practical applications. The photonic QIP chips have made great progress and are widely employed in quantum encrypted communication,41 quantum teleportation, and quantum computing.42,43 For example, Fig. 3(c) is the photonic integrated circuits chip by cascaded Mach–Zehnder interferometers (MZIs) for programmable QIP;31,44Fig. 3(d) is the large-scale chip comprising more than 200 photonic components for 98 different two-qubit operations; Fig. 3(e) is a large scale quantum circuit with more than 550 photonic components on a single chip for multidimensional quantum entanglement.
![]()
Figure 3.Integrated waveguide meshes: from QIP to MVM. (a) Bulk-optical CNOT gate in 2004.
Meanwhile, with the development of silicon-based optoelectronics technology, programmable linear processors were developed to meet more applications, such as tunable filter, microwave photonics, and all-optical switching.45 For example, optical switching networks [in Fig. 3(f)] can be realized with different kinds of network topologies programmable linear processors in data centers.34 Besides, a hexagonal cell chip [in Fig. 3(g)] for implementing arbitrary unitary transformations and signal processing,35,46 microwave photonic signal processor [in Fig. 3(h)] for continuous radiofrequency filtering and processing, and self-configuring linear processor [in Fig. 3(i)] with in-circuit optical power monitors feedback47
Theoretically, the transfer matrix of lossless integrated waveguide meshes is a unitary matrix,51,52 then the unitary MVM can be performed.53 In recent years, integrated waveguide meshes became a feasible architecture for large-scale general purpose MVM computation in post-Moore’s law era. The first ANN proof-of-concept experiment was performed on 56 cascaded programmable MZIs meshes in 2017 [in Fig. 3(j)], and a simple vowel recognition task was demonstrated due to the limited hardware capability. In 2020, large scale
2.2 Multiple Light Source MVM
In addition to single light source schemes with a single coherent laser light source, multiple light source schemes (implemented with optical frequency comb or multiple wavelength laser arrays) are proposed in recent published studies. These are emerging methods for improving the signal-to-noise ratio of light energy and avoiding the influence of laser signal phase jitter. For example in Fig. 4(a), a microring modulators MVM scheme with
![]()
Figure 4.Multiple laser source MVM. (a) MVM based on microring modulators.
2.3 Fourier Transform-based CONV
CONV can be achieved indirectly by using Fourier transform (FT) and inverse Fourier transform (IFT) [in Fig. 5(a)]: first, pad the input sequences with zeros to the output length and then perform the FT; second, element-wisely multiply the transformed sequence in the Fourier domain; finally, perform IFT to derive the CONV results. FT can be implemented by passive photonic devices with the free-space propagation region without consuming energy, like star coupler [in Fig. 5(b)] and phase-compensated multimode interferometer (MMI) [in Fig. 5(c)]. The plasmonic structure [in Fig. 5(d)] can offer four to five orders of magnitude of enhanced processing speed due to the minuscule footprint of the device.61 Moreover, Fig. 5(e) is the on-chip Cooley-Turkey method FT executing the CONV on the order of tens of picoseconds short.62 Once the FT device is realized, then the “4f” CONV system can be realized by using a cascade of two photonic FT devices with a phase and amplitude filter mask in between. The limitation of FT-based CONV is that FT devices typically take up large on-chip space due to the need for free-space propagation. Furthermore, the insertion loss of the FT-based CONV also leads to restrictions in the matrix configuration and overall energy efficiency.
![]()
Figure 5.FT-based CONV. (a) Flowchart of CONV using FT. (b) FT based on MMI coupler and compensating phase shifter arrays.
2.4 Element-wise MAC
Theoretically, both MVM and CONV can be realized by a series of element-wise MAC operations. For example, a basic
![]()
Figure 6.Element-wise MAC operations. (a) Basic
Element-wise MAC operations can be realized by balanced homodyne detection, microring modulators, and cascaded modulators arrays. For balanced homodyne detection [in Fig. 6(b)], input data are optically fanned out to channels, and each detector functions as a photoelectric multiplier, calculating the homodyne product and accumulating the multiplication results. The theoretical equivalent energy consumption of analog MAC can break through Landauer’s limits in the digital paradigm (
2.5 Dispersion-based MAC
The photonic matrix computation can be achieved by dispersion-based MAC, in which the dispersion manipulation is usually conducted with linearly dispersive photonic waveguides (or optical fibers) and broad-spectrum laser source (or ultrashort laser pulses). For example, the reconfigurable time-wavelength plane manipulation scheme [in Fig. 7(a)] was proposed by employing a 1.1-km long dispersion fiber and 18-GHz FSR optical frequency comb to realize the
![]()
Figure 7.MAC based on dispersion. (a) The 118 GigaMAC/s matrix operation is realized by 1.1-km long linear dispersion fiber.
3 Discussions and Perspectives
3.1 Optical Interconnections in Computation Hardware
In Von Neumann architecture processors, the memory-processor interconnections are one of the major factors influencing the overall performance [in Fig. 8(a)], especially in data-intensive applications. For example, large scale matrix multiplication (such as
![]()
Figure 8.Interconnections in processors, memory, and peripheral hardware. (a) The memory-processor interconnections are one of the major factors influencing the overall performance and the memory wall problem that has hindered high-performance computing.
Electronic processors are also suffering from the tremendous energy consumption of digital transceiver circuits during massive data I/O connections. Increasing the memory-processor bandwidth and energy efficiency in interconnections is an effective way to diminish the data movement problem.74 For example, in cloud data centers where GPUs are the mainstream hardware for ANN acceleration, Nvidia developed NVlink connections for increasing the interface bandwidth of GPU interconnections (up to Tb/s).75 However, when the bandwidth exceeds
Instead of power-hungry electronic transceiver circuits, on-chip optical transceivers are good alternatives for low-energy-budget interconnections and boosting the data movement among the processors, memory, and peripheral hardware72 [in Fig. 8(c)]. Therefore, it is necessary to heterogeneously integrate photonic, optoelectronic, and electronic devices and circuits on the silicon substrate. Recently many studies have been performed to realize optical interconnections on a photonic-electronic integrated platform. For example, in 2015, photonic-electronic integration was demonstrated on a silicon chip, which integrated over 70 million transistors and 850 photonic components that work together to demonstrate aggregated
3.2 Photonic-Electronic Integration
Optical computing has a history of nearly 70 years,81 and the optical computing products and studies with bulk optical systems have showed great potential in matrix computations. For example, Fig. 9(a) is an MVM processor released in 2003 with a
![]()
Figure 9.Optical computing from bulk-optics to photonic-electronic integration. (a) SLM-based MVM processor released by Enlight in 2003.
Silicon-based optoelectronics is a photonic-electronic integrated platform that avoids the inconvenience of discrete optics; mature CMOS manufacturing processing and packaging can achieve mass production, which is an advantage that conventional optical computing does not have. Photonic-electronic copackaging [in Fig. 9(d)] is an emerging technology for comprehensive computation hardware system and enhancing the interaction between photonic core and electronic application-specific integrated circuits (ASICs).34 For example, a large-scale
3.3 Larger Scale General Purpose Matrix Computation
When encountering a computation problem, before considering optical computing, it should be considered whether it will be faster, more economical, more energy-efficient, or more reliable than using existing electronic processors or designing new specific digital logic circuits. Silicon-based optoelectronic matrix computation processors should directly compete with its rivals, such as multicore electronic processors (such as the existing GPU, TPU, and ASIC).85,86 By combining electronic, photonic, and optoelectronic devices and circuits together, silicon-based optoelectronic matrix computation is one of the few general-purpose computations that have the potential to surpass the computation performance of the electronic processors. In digital electronic MVM processors, with larger matrix configuration, energy consumption increased proportionally to the area of the matrix (i.e., total number of elements in a matrix), and the energy consumption per MAC with FP16 or bfloat16 precision is about
![]()
Figure 10.Energy efficiency of silicon-based optoelectronic matrix computation processor (consider all the photonic, optoelectronic, and electronic devices and circuits). (a) The equivalent energy efficiency (energy consumption per MAC operation) linearly decreases as the side-length of the matrix increases.
With larger matrix configuration, the advantages in total computational power, energy efficiency, and latency will be further enhanced; although thermally maintaining the static photonic matrix will consume additional energy, this static energy consumption problem can be well solved, e.g., silicon substrate removal is doable to improve the thermal modulation efficiency and reduce the static energy consumption. Considering the entire computation systems including photonic, optoelectronic, and electronic devices and circuits, some empirical evaluation results indicate that silicon-based optoelectronic matrix computation will outperform digital logic circuits in terms of energy efficiency when the matrix configuration exceeds
3.4 Improve Computation Density and Computation Precision
In silicon-based optoelectronic matrix computation processors, increasing the modulation bandwidth is an intuitive way to further improve computational power density per unit area. Although on-chip optoelectronic devices can reach modulation speeds of tens of gigahertz, passive components have limited dynamic response (
Furthermore, integrated waveguide meshes are mostly constructed from individual MZI devices, and the footprint of the MZI is commonly about
Computation precision plays an important role in analog computation. With a larger scale matrix configuration (e.g., from
3.5 Matrix Computation for Lower-Precision-Requirement Applications
Hardware development (processor design and production) and software development (algorithm and applications) are generally carried out separately, and matrix computation processors usually have a standard application programming interface to be utilized for software development. Higher precision is a long-standing pursuit for computation hardware. It is convenient for an electronic processor to achieve 64-bit double-precision arithmetic. However, it is impossible to achieve such high precision in analog processors. At the current stage precision problems remain in silicon-based optoelectronic matrix computation processors, as computation errors are inevitable in analog computation paradigms. We need to find some applications with lower precision requirements that can run on the general-purpose processors. Although it is difficult for silicon-based optoelectronic matrix computation processors to solve high-precision arithmetic or global optimization problems, heuristic algorithms can be developed to effectively search a near-optimal solution at a reasonable compute cost in a lower-precision processor. Silicon-based optoelectronic matrix computation processors are feasible for solving some difficult problems and reducing their time-complexity, like nondeterministic polynomial (NP) time decidable/solvable problems. A certain degree of computation errors can be tolerated in the heuristic algorithms, and the slight computation inaccuracy does not affect the result.
For example, Ising models are NP-complete problems in combinatorial optimization, and finding a minimal energy state of the Ising model (i.e., annealing) is NP-hard. Commonly, the minimal energy state of Ising models can be solved in digital processors (with heuristic algorithms) or quantum computers (with quantum annealing). Bulk-optical computing systems (such as optical fiber loops92 and spatial light modulators93) have been invented and developed to accelerate the annealing of the Ising model. A Hopfield neural network is a recurrent neural network, in which the MVM (between the binary state vector and weight matrix) can be effectively accelerated in an MVM processor with lower time complexity. By parametrically designing the evolution dynamics of the Hopfield neural network and mimicking the interactions within the nodes [in Fig. 11(a)],94 the Ising model can spontaneously evolve to an acceptable low-energy state.
![]()
Figure 11.Photonic matrix computation can be used for solving some difficult problems and reducing their time complexity. (a) Heuristic recurrent algorithm for the annealing of Ising models. (b) Reconstruction of
In compressed sensing [in Fig. 11(b)] applications, with known measurement value
Similarly, discrete FT (DFT) [in Fig. 11(c)] is a frequently-used operation in digital signal processing and speech recognition.96 Normally, the time complexity of the DFT algorithm by unitary matrix multiplication is
4 Summary
We reviewed the recent research on silicon-based optoelectronic matrix computations, including MVM, CONV, and MAC operations. Conventional electronic processors are still the mainstream and almost invincible hardware that is based on digital logic circuits for computation. When designing new optical computing processors (or coprocessors) for computation, the computation performance needs to outperform the digital logic circuits in terms of computational power, energy efficiency, I/O connections, and latency. Although computation errors are inevitable in analog computation paradigms, lower-precision-requirement applications (e.g., ANN, combinatorial optimization, compressed sensing, digital signal processing, and quantum information processing) can be run on the general-purpose matrix computation processors. Looking forward to the future of large-scale matrix computation in specific applications, the silicon-based optoelectronic platform can not only heterogeneously integrate photonic (e.g., integrated waveguide mesh, free space propagation region, and dispersive waveguides), optoelectronic (e.g., high-speed modulators and photodetectors), and electronic (e.g., memory circuits, driver circuits, TIAs, serial-parallel converters, and analog-digital converters) devices and circuits on a silicon substrate to fulfill the requirements of large scale matrix computation, but can also boost the low-energy-budget data movement among the processors, memories, and peripheral hardware. We believe that silicon-based optoelectronics is a promising and comprehensive platform for general-purpose matrix computation in the post-Moore’s law era.
Pengfei Xu received his PhD from Sun Yat-Sen University, China in 2019, and was a postdoctoral fellow in School of Electronics, Peking University, China. He is now a R&D engineer at Interuniversity Micro-electronics Center (IMEC), Belgium.
Zhiping Zhou received his PhD in Electrical Engineering from Georgia Institute of Technology, USA in 1993. He is now a distinguished professor at Peking University, China, and a distinguished principal investigator in Shanghai Institute of Optics and Fine Mechanics, Chinese Academy of Sciences, China, focusing on silicon-based optoelectronics and microsystems research and development.
References
[1] Z. Zhou. Silicon Based Optoelectronics(2021).
[3] E. Mounier, J. Malinge. Silicon photonics report—Yole Développement.
[5] D. Thomson et al. Roadmap on silicon photonics. J. Opt., 18, 073003(2016).
[7] IEEE P802.3bs 200 Gb/s and 400 Gb/s Ethernet Task Force 2017.
[10] E. Luan et al. Silicon photonic biosensors using label-free detection. Sensors, 19, 1161(2019).
[13] K. Simonyan, A. Zisserman. Very deep convolutional networks for large scale image recognition(2015).
[14] K. He et al. Deep residual learning for image recognition(2016).
[15] S. Hochreiter, J. Schmidhuber. Long short-term memory. Neural Comput., 9, 1735-1780(1997).
[16] K. Rupp. 42 years of microprocessor trend data(2018).
[22] G. M. Amdahl. Validity of the single processor approach to achieving large scale computing capabilities. AFIPS Conf. Proc., 483-485(1967).
[27] N. G. Karthikeyan et al. Mobile Artificial Intelligence Projects(2019).
[30] A. Politi et al. Silica-on-silicon waveguide quantum circuits. Science, 320, 646-649(2008).
[38] N. C. Harris et al. Accelerating artificial intelligence with silicon photonics, 1-4(2020).
[41] N. Gisin, R. Thew. Quantum communication. Nat. Photonics, 1, 165-171(2007).
[42] J. L. O’Brien. Optical quantum computing. Science, 318, 1567-1570(2007).
[44] N. C. Harris et al. Linear programmable nanophotonic processors. Optica, 5, 1623-1631(2018).
[45] J. Carolan et al. Universal linear optics. Science, 349, 711-716(2015).
[55] L. de Marinis et al. Photonic neural networks: a survey. IEEE Access, 7, 175827-175841(2019).
[63] R. Hamerly et al. Large scale optical neural networks based on photoelectric multiplication. Phys. Rev. X, 9, 021032(2019).
[70] D. Patterson et al. A case for intelligent RAM. IEEE Micro, 17, 34-44(1997).
[71] M. Forsythe. Matrix processing with nanophotonics(2019).
[74] K. Keeton. Memory-driven computing(2017).
[76] G. Keeler. Photonics in the package for extreme scalability (PIPES)(2020).
[81] P. Ambs. Optical computing: a 60-year adventure. Adv. Opt. Technol., 2010, 372652(2010).
[95] S. Foucart, H. Rauhut. A Mathematical Introduction to Compressive Sensing(2013).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20