
Shijie Feng, Yile Xiao, Wei Yin, Yan Hu, Yixuan Li, Chao Zuo, Qian Chen. Fringe-pattern analysis with ensemble deep learning[J]. Advanced Photonics Nexus, 2023, 2(3): 036010
- Advanced Photonics Nexus
- Vol. 2, Issue 3, 036010 (2023)
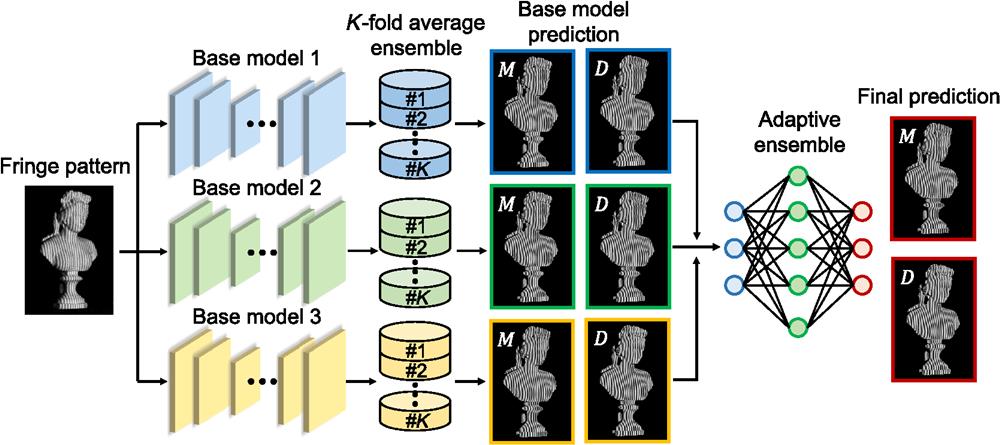
Fig. 1. Diagram of the fringe-pattern analysis using ensemble deep learning. The input fringe image is processed by three base models. In each base model, a
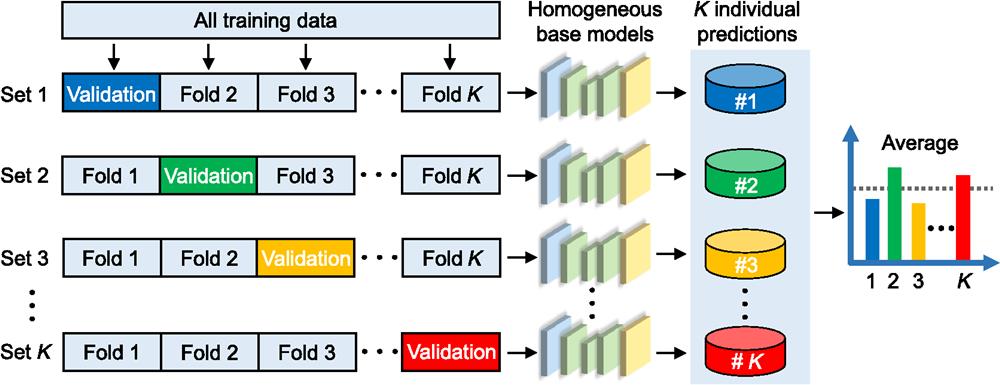
Fig. 2. Diagram of the
Fig. 3. Diagram of the proposed adaptive ensemble. (a) It trains a MultiResUNet to combine the predictions of base models. (b) Structure of the MultiRes block, where a series of
Fig. 4. Experimental results of several unseen scenarios that include a set of statues, an industrial part, and a desk fan. The input is a fringe pattern. It is then fed into the U-Net, MP DNN, and Swin-Unet, which are trained by the sevenfold average ensemble, respectively. By calculating the average, each base model outputs a pair of numerators and denominators. Then, the outputs of base models are processed by the adaptive ensemble, which combines the contribution of each base model and calculates the wrapped phase.
Fig. 5. Comparison of the proposed method with the U-Net. (a) and (b) The absolute phase error maps of the U-Net and our method, respectively. (c) Selected ROIs of the phase error for the two methods. (d) The performance of different
|
Table 1. Quantitative validation of the proposed approach.

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20