
Jianhui Ma, Zun Piao, Shuang Huang, Xiaoman Duan, Genggeng Qin, Linghong Zhou, Yuan Xu. Monte Carlo simulation fused with target distribution modeling via deep reinforcement learning for automatic high-efficiency photon distribution estimation[J]. Photonics Research, 2021, 9(3): B45
- Photonics Research
- Vol. 9, Issue 3, B45 (2021)
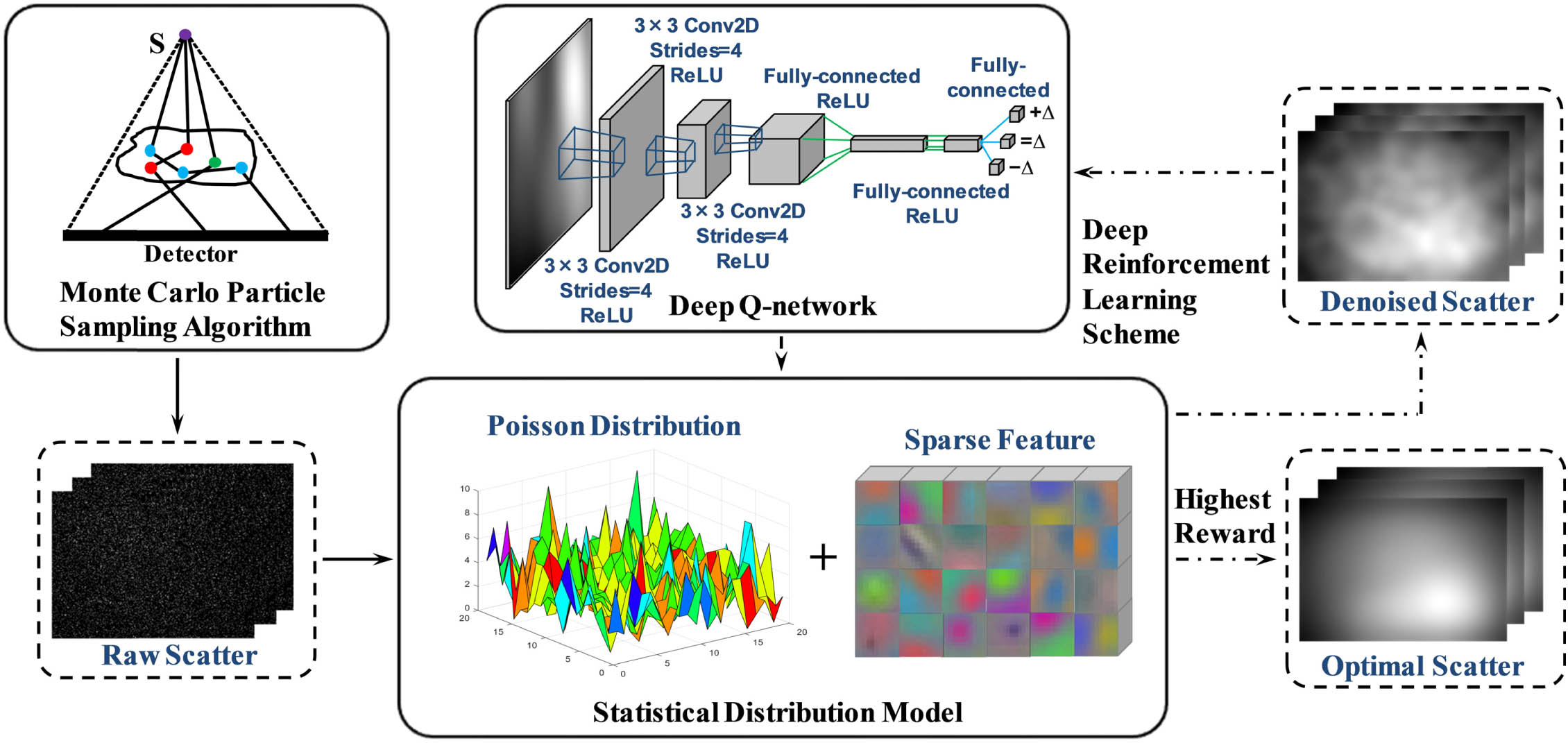
Fig. 1. Automatic scatter estimation framework. The MC algorithm generates raw scatter signals in terms of the X-ray source energy spectrum and system geometry configuration. The DRL scheme (denoted by the dashed black arrow) employs a deep Q
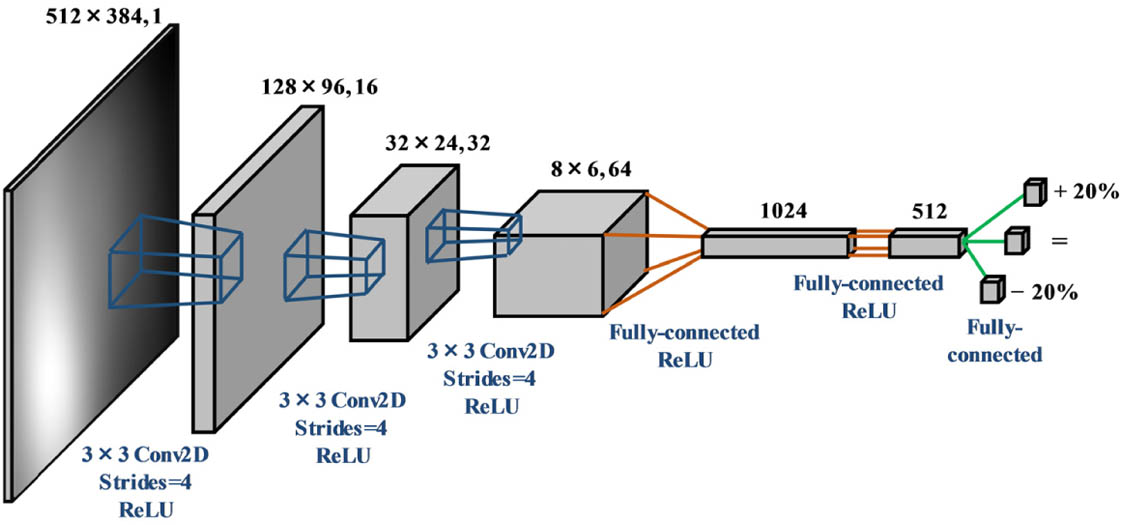
Fig. 2. Network architecture in the DDQN. The network takes a scatter image as input and predicts three possible actions for parameter adjustment. The number at the top denotes the feature map size and channel number, and the operations for each layer are presented at the bottom. For instance, the first hidden layer convolves 16 filters of 3 × 3
Fig. 3. (a) is the primary projection of the head and neck (H&N) patient; (b)–(i) represent raw scatter projections that are separately calculated by the MC particle sampling algorithm with source photons of 5 × 10 5 1 × 10 6 5 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9 1 × 10 10 1 × 10 12
Fig. 4. (a)–(g) are the scatter images of Figs. 3 (b)–3 (h) smoothed by the over-relaxation smoothing algorithm; (h) corresponds to Fig. 3 (i), which is considered a noise free scatter image and utilized as the ground truth.
Fig. 5. Intensity profiles of Fig. 4 along the (a) horizontal and (b) vertical directions as denoted by the orange lines in Fig. 4 (h).
Fig. 6. From top to bottom: six testing results with 5 × 10 5 1 × 10 6 5 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9
Fig. 7. (a)–(d) Intensity profiles of the first, second, third, and last rows in Fig. 6 . The locations of the profiles (a)–(d) are denoted by orange lines at the last column of Fig. 6 .
Fig. 8. (a)–(c) indicate boxplots of the metric difference of SSIM, PSNR, and RAE between Empirical and ASEF for all testing cases. metric diff = metric Empirical − metric ASEF Empirical and ASEF .
Fig. 9. Automatic scatter estimation process for a testing case. (a)–(c) are smoothed scatter images at Steps 1, 7, and 13, respectively. (d) and (e) separately plot the SSIM and RAE over steps.
Fig. 10. Different scatter images. From left to right: scatter projection input, the ground truth of the scatter image at the first column, and Grad-CAM heatmaps of three subnetworks { W k , W ω , W β }
Fig. 11. From top to bottom: four prostate cases with 5 × 10 5 1 × 10 6 5 × 10 6 1 × 10 7
Fig. 12. (a)–(d) Intensity profiles of the four prostate cases presented in Fig. 11 . Profile locations are outlined by orange lines in the last column of Fig. 11 .
|
Table 1. DDQN Training Process
|
Table 2. Parameters in the DDQN Training Phase
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 3. SSIM, PSNR, and RAE Statistics (a
| ||||||||||||||||||||||||||||||||||||||||||||
Table 4. Computation Time for One Scatter Image of a Prostate Patient across Different Photon Numbers

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20