
Yuezhi He, Jing Yao, Lina Liu, Yufeng Gao, Jia Yu, Shiwei Ye, Hui Li, Wei Zheng, "Self-supervised deep-learning two-photon microscopy," Photonics Res. 11, 1 (2023)
- Photonics Research
- Vol. 11, Issue 1, 1 (2023)
Abstract
1. INTRODUCTION
Two-photon excitation fluorescence microscopy (TPM) [1] is a powerful tool for 3D imaging of cellular and subcellular structures and functions deep in turbid tissues. Owing to its nonlinear excitation properties, TPM provides compelling performance of near-diffraction-limited spatial resolution in deep and scattered samples. However, conventional TPM captures volumetric images by serially scanning the focal point in a 3D space [2], which requires compromises among the imaging resolution, speed, and area [3]. A higher-resolution image requires a higher number of sequentially acquired pixels to ensure proper sampling, thus increasing the imaging time. Considerable effort has been devoted to speeding up the acquisition efficiency of imaging systems, such as multifocal scanning [4], temporal focusing [5], and multiplane imaging [6]. However, these methods modify the light path and require sophisticated hardware design. Developing a new method to effectively enhance undersampled point-scanning TPM images is of great practical interest for biological studies.
Deep learning [7], a method based on artificial neural networks (ANNs), has drawn wide-spread attention among the microscopy research community and has been used for segmentation and recognition in microscopy image analysis. In recent years, various new applications have emerged, including modality transformation [8], image denoising at a low photon budget [9], reducing light exposure for TPM [10], accelerating single-molecule localization [11], speeding up multicolor spectroscopic single-molecule localization microscopy [12], 3D virtual refocusing [13], and instantaneous fluorescence lifetime calculation [14,15]. Among numerous others [16–19], super-resolution imaging via a deep neural network [20], which transforms spatially undersampled images into super-sampled ones, is one of the hottest topics. It tackles this problem by training the network to learn the mapping between low-resolution images and their high-resolution counterparts [21]. When low-resolution images are presented, the network is expected to output or infer a high-resolution image with high fidelity. Using deep-learning-based image-enhancing techniques, high-resolution images can now be recovered from low-resolution images with reduced scan times and no hardware modifications.
The majority of deep neural networks used in microscopic imaging rely on training with hundreds of thousands of high-quality images [3,8,20,22]. For the image-resolution-enhancement task, high-resolution images are paired with corresponding low-resolution images for supervised network training. However, large-scale 3D online microscopic image databases are limited. Moreover, training with data generated from different systems may cause performance changes owing to data drift. Consequently, most research is based on self-collected image pairs. Low-resolution images can be acquired experimentally, followed by careful image registration [20], or by simply applying a degradation model to digitally downsample high-resolution images [3,23,24]. The long acquisition process inevitably incurs high costs. Recent research has shown the estimated cost of acquiring 240 h of high-resolution electron microscopic imaging data to be over $8000 [24]. The cost doubles if low-resolution images are measured experimentally. Acquiring 3D data worsens the situation, as the sample preparation is different, and imaging time significantly increases, not to mention the potential risks of photobleaching. In addition to the cost of data acquisition, the computational cost is non-negligible. The large neural networks routinely used in current deep learning microscopy not only require a large volume of data to fit but also require high-performance computing resources, such as high-end graphical processing units (GPUs) or cloud-based computing platforms, to train, which is an additional burden for many optical and biomedical laboratories.
Sign up for Photonics Research TOC. Get the latest issue of Photonics Research delivered right to you!Sign up now
In this study, we developed a lightweight model to enhance the resolution of 3D microscopic images. The model requires zero training data apart from the input volumetric image itself; therefore, it is fully self-supervised [25–27], i.e., Self-Vision. We demonstrated that Self-Vision could recover images, while the input was fourfold undersampled in both the lateral and axial dimensions, which in theory results in an over 60-fold (
2. RESULTS
A. Concept of Self-Supervised Resolution-Enhanced Volumetric Image
Figure 1 shows the concept of Self-Vision-based resolution-enhancement for volumetric images. The image pairs for training are generated by first cropping small patches from the input image (training data generation in Fig. 1) and then downsampling the patches along with their augmentations to synthesize low-resolution inputs (network training in Fig. 1). After the training stage, the input image is sent to the network for a high-resolution output. To avoid confusion with super-resolution techniques using optical methods, we use the term “resolution-enhancing” instead for deep-learning-based methods throughout the work. Some combinations (e.g., super-resolution network/model) are kept, which are consistent with the common expressions in the literature.
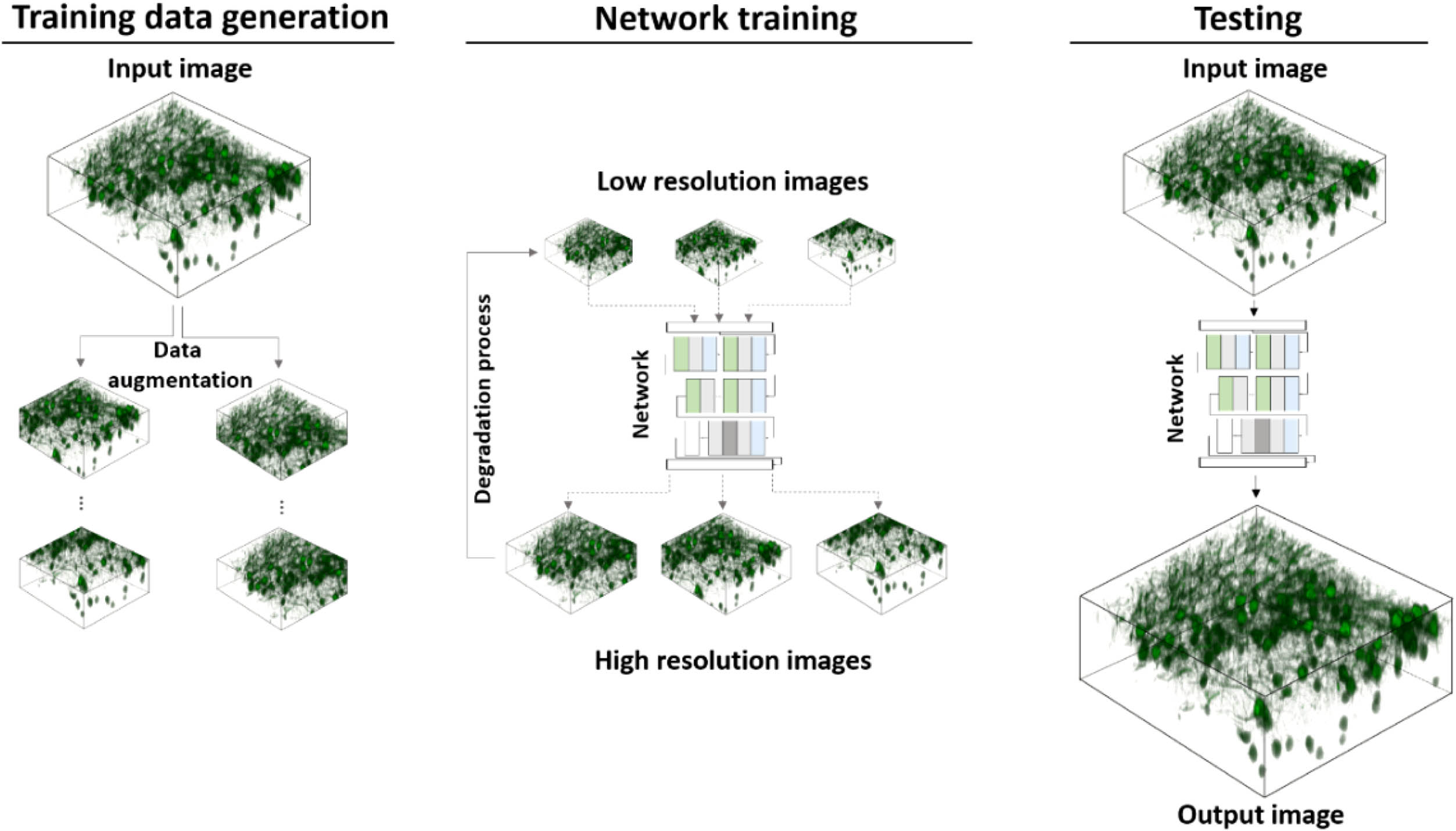
Figure 1.Overview of proposed framework. The input image is first cropped and augmented into patches. The downsampled version of the patches is then used as the input for training, where the original patches serve as the target output. At the test phase, the input image is fed to the trained network to produce high-resolution output.
In the context of volumetric image enhancement, the patches can be extracted from a single input image scale of the order of
B. Self-Vision Improves Resolution of Undersampled Volumetric Images
Using a microscope, the process of sampling a volumetric image,
Our goal was to train a neural network,
To demonstrate the efficacy of our Self-Vision network, we first used simulated beads (see Supplementary Fig. S2 in Ref. [28] and Methods) with anisotropic profiles. The reference image,
We then verified whether Self-Vision could improve the resolution of undersampled volumetric images acquired from real biological samples and infer details that were undistinguishable in the degraded inputs using a commercially available microscope (Nikon A1R-MP). The networks were trained and tested using 3D images of green fluorescent protein (GFP) labelled Thy-1 brain slices from mice (see Section 4). The brain slices were placed on glass slides for two-photon microscopy using a
Figure 2 shows Self-Vision TPM imaging of neurons from the mouse brain tissue. The neuron bodies from the test specimens are magnified and shown, along with the intensity profiles drawn from a line across the image (marked by a white dash). In the lateral and axial dimensions, the network outputs have a similar profile to the original image (the contrast between the cells and the background also being enhanced). For example, the troughs between the two peaks, i.e., the blue line profile plots in Fig. 2, which show little contrast on the input profile, become distinguishable in the output profile. An unexpected feature of the network is that the output images appear less noisy than the original images, as the spatially undersampled inputs filter out any high-frequency noise (caused by system instability or background noise) and content present in the original images.
![]()
Figure 2.Zoomed-in images of neurons and their line profiles across the white dashed line. (a) Lateral images. (b) Axial images.
C. Comparison with Representative Deep-Learning-Based Super-Resolution Models
We chose three representative deep-learning-based super-resolution models with different designs for microscopic images for comparison (see Methods section Supplementary Note 2 in [28] for data preparation and network training), including a recent attention-based network (DFCAN) [29], which uses Fourier domain information and outperforms a number of classical super-resolution networks; a network designed for point-scanning microscopy (PSSR) [24], which trains on computationally degraded low-resolution images; further, it should be noted that our framework shares the same method of generating undersampled images; and a super-resolution model with a dual-stage processing architecture (DSP-Net) [23], which also supports 3D input like our method. These models require much more data than our network for training (see Supplementary Fig. S1 in [28], data-hungry training). Consequently, in addition to the test images, four extra regions of similar volume (size) were collected from the specimen using the same device to train the three representative models used for microscopic image resolution enhancement. The low-resolution input for training could be either experimentally acquired from the same regions or synthetically generated by downsampling. Experimentally, we found that it was difficult to register low-resolution–high-resolution image pairs at subpixel-level precision, which is generally required for super-resolution image training. In addition, sample instability and laser power fluctuations complicate postprocessing. Consequently, low-resolution images were synthetically generated by downsampling the reference images. In total, over 500 additional high-resolution images were acquired to train the models for comparison (see Section 4). By contrast, our framework used no additional training data, the only input being the volume to be inferred. Even so, our model exhibited excellent performance. Practically, our framework has a great advantage in that there is no need to image hundreds of high-quality images for training data, as the low-resolution input image can be directly fed to the network to obtain a high-resolution output. It should be noted that training with a larger data set may improve the performance of other networks, but this just proves that our training strategy is effective, especially when the sample is rare or the training data are limited.
Figure 3(a) shows the low-resolution input, network outputs, and original high-resolution reference from a lateral slice of the test sample. It should be noted that DFCAN and PSSR are 2D super-resolution networks; therefore, the volumetric images were fed to the network slice by slice. Our framework and DSP-Net support 3D images. The input slice shown in Fig. 3(a) is
![]()
Figure 3.Evaluation of four super-resolution models. Lateral and axial images of low-resolution input, original reference, and network outputs of neuron cells. Our proposed model shows low error. (a) Representative lateral images inferred from low-resolution input. The absolute error images with respect to the original are shown below. (b) Representative axial images inferred from low-resolution input.
Figure 3(b) shows the inferred results from the axial slice of the test sample. Because both our network and DSP-Net allow volumetric inputs and utilize 3D information, the axial output error is much smaller than that of the 2D networks DFCAN and PSSR. Another error source of a 2D network is the improper normalization of deeper slices. As a deeper slice receives fewer photons, the image brightness tends to decrease. Inferring the output in a slice-by-slice manner using a 2D network can overamplify the overall brightness in the deeper layers and cause noticeable errors. Consequently, we statistically measured the performance of the networks using the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). The box plots shown in Fig. 4 were calculated using 32 sets of samples. Our network outperforms the others in both metrics, thereby confirming the effectiveness of the proposed framework.
![]()
Figure 4.PSNR and SSIM evaluation between the four models.
D. Large-Image Inferencing Using Self-Vision
Having seen the potential of using a self-supervised Self-Vision network to enhance spatially undersampled images (see Fig. 2), we next exploited an important feature of our lightweight framework, i.e., inferring large input images.
In many well-known super-resolution models for microscopic images, a common problem is that the input image size is limited; for example, for a typical input size
Benefitting from the lightweight design, our framework supports
![]()
Figure 5.Large image inference using a high-resolution input. High-resolution image (
On the left-hand side of the inset image, a low-resolution image generated from downsampling is enhanced. This is a typical application of most deep-learning-based networks (see
Figure 6 shows the results from a volumetric input (
![]()
Figure 6.Volumetric image inference using a high-resolution input. Top left: input lateral slice; top right: corresponding output slice; bottom left: input axial slice; bottom right: corresponding output slice.
E. Large Field-of-View TPM Imaging Based on Self-Vision
To demonstrate how Self-Vision enhances undersampled images (which we believe is the most useful case of the network), we developed a home-built large-FOV system (see Section 4 for the system configuration). Generally, a large-FOV system suffers from a slow imaging process. This can be detrimental to the sample because of phototoxicity or photobleaching. Moreover, slow acquisition decreases the temporal resolution, making transient phenomena difficult to observe. Consequently, we applied our framework to images acquired using a large-FOV system. The image size was
Figure 7 shows the power of Self-Vision in large-image inference. Using only a small training FOV (bounded by the yellow border in Fig. 7), the network can infer the full FOV (bounded by the blue border in Fig. 7) in a single forward pass. No cropping of the input or stitching of the outputs is required; thus, data processing for images captured from a large-FOV system can be greatly simplified.
![]()
Figure 7.Large image inference of Self-Vision (image brightness adjusted for visualization). Despite being trained on a small FOV (indicated by yellow border), Self-Vision can infer the entire FOV for the system, saving both training and acquisition time.
3. DISCUSSION
Despite the tremendous success of the deep-learning-based method used in the microscope imaging community, the high cost of computational resources and the demand for large-scale training data remain practical challenges. Our deep learning-based approach improves the resolution of spatially undersampled microscopic images with zero training data (apart from the input image itself), which can be useful in a data-limited scenario, such as investigating pathological sections from rare diseases. In such cases, gathering hundreds of training data points from similar specimens is a luxury that medical practitioners cannot afford. By exploiting the internal information present in a single low-resolution image, we can achieve performance on par with that of multiple state-of-the-art models trained using hundreds of additional paired data. Another advantage of the Self-Vision framework is that it facilitates large-FOV imaging. Despite being trained with only a small portion of the image from the entire view, Self-Vision can infer a high-resolution image for the entire FOV. This can substantially reduce the acquisition time for large-FOV systems, as high-resolution images that would otherwise require a long time to sample can be inferred from a spatially undersampled version. Moreover, the lightweight model allows large images to be inferred with less image cropping/stitching, easing the processing of high-dimensional images.
Nevertheless, it is important to keep in mind that deep-learning-based super-resolution is naturally ill-posed. Consequently, the output represents only a statistical estimation of the training data. In practice, the following points must be considered. First, hallucinations or artefacts become overwhelming when the upsampling factor goes beyond
It is worth noting that the size of the input image can affect the network performance because the only source of training data is the input image itself. For instance, if the input image is too small, even with data augmentation, the patches generated may still be limited, and the model is likely to be overfitted. However, if the input image is too large, our small-sized model may struggle to further improve the input, owing to the limited model parameters. To determine the appropriate input size, we trained the model using images of different input sizes and examined its performance. Seven volumes of different voxel numbers were cropped from the center of the test image [Fig. 8(a)].
![]()
Figure 8.Network performance improves as the training FOV increases. At the top left corner, the boxes with small, medium, and large sizes indicate different input training volumes (not drawn to scale). The plot at the top right shows that network performance improves as the voxel number increases. The bottom images [(c)–(j) lateral, (k)–(p) axial] illustrate the change of the output when the training FOV increases from a small volume to a large volume.
The smallest input was
Future work should focus on the following aspects. Our current design improves spatial resolution; however, the time dimension remains unexplored. The proposed framework could increase the frame rate of sparsely sampled 3D video data by adding additional dimensions to the network. Another effort could be to integrate a sophisticated downsampling method into the data augmentation process. As only the naïve downsampling method is used to synthesize low-resolution images, the system noise and point spread function are ignored. Adding an accurate estimation of these factors to the downsampling process could further improve the network performance. Moreover, designing a network that could be trained without a modern GPU would be of great practical interest because the majority of microscopes are not equipped with high computing power.
Taken together, the lightweight design, data-saving training strategy, and high-throughput capability of the Self-Vision framework represent an important step for computational super-resolution imaging. Our ability to bridge the gap between neural network training and microscopic image acquisition is key to democratizing deep-learning-based super-resolution imaging. We expect the framework to continue to develop, not only in the modalities used in this work but also in various imaging modalities for different tasks, as the barriers to applying deep learning in microscopy are continually lowered.
4. METHODS
A. Simulation of Bead Images
All the reference bead images were generated using MATLAB. First, a 3D matrix of size
B. Mouse Brain Slices Preparation
A six-week-old mouse (The Jackson Laboratory, stock number 007788) labelled with the Thy1-GFP-M transgene, which is intensely expressed in mossy fibers in the cerebellum, was first anaesthetized by intraperitoneal injection with a mixture of 2%
C. Microscope Setup and Imaging Parameters
Two microscopes were used for the imaging experiments. One was a commercially available two-photon microscope (Nikon A1R), and the other was a home-built large FOV two-photon microscope. The light source of the system in the Nikon A1R is a Ti:sapphire laser (MaiTai eHP DeepSee, Spectra Physics), which can generate an excitation wavelength of 920 nm for two-photon imaging. The laser power was set to 2.8 with a gain of 110. A
To acquire additional training data for the other networks, four extra volumes of similar sizes were imaged. The lateral image size was still
For the home-built large-FOV two-photon microscopy, the detailed implementation of the large-FOV TPM used can be found in Ref. [30]. In short, we applied an adaptive-optics method to extend the FOV, resulting in an increased FOV diameter of 3.46 mm using a commercial objective with a nominal FOV diameter of 1.8 mm.
D. Self-Supervised Volumetric Image Super-Resolution Network
The design of our Self-Vision network follows two principles. First, the network needs to be trained using only a single volumetric input instance. Second, the model supports large-image inference. To fulfil these requirements, a small neural network was devised. Figure 9 shows the network architecture of the proposed design. The network is composed of four modules, i.e., extraction, shrinking, grouped convolution, and expansion. It begins with feature extraction for the input with 3D convolution using a filter size of 5 and a parametric rectified linear unit (PReLU) activation layer. Formally, PReLU can be expressed as follows:
![]()
Figure 9.Architecture of Self-Vision. Some grouped convolution layers were omitted in the figure for simplicity.
The output of the extraction module can be expressed as follows:
Consequently, the shrinking module reduces the number of filters from 16 to 6 using filters of size 3. The output of the shrinking module can be expressed as follows:
Subsequently, multiple layers of grouped convolution, followed by PReLU activation, can be used to further extract high-level features. This can be expressed as follows:
The expansion module then upsamples the output from the previous layer to the desired resolution. In this step, subpixel convolution is used as the upsampling operation in conjunction with 3D convolution to create a high-resolution image. Finally, multiple images are fused using backprojection techniques to create a monochromatic network output. Consequently, the output of the neural network can be expressed as follows:
Several designs are critical for the network to work well, and the shrinking and grouped convolution modules substantially reduce the total number of network parameters, making single-input data training feasible. The super-resolution network employs a post-super-resolution upsampling framework, where the computation-intensive feature extraction process takes place in the low-dimensional space, greatly lowering the space and computational complexity. The subpixel convolution used for upsampling and the backprojection technique further reduces the output error.
Learning the end-to-end mapping network,
E. Self-Vision Implementation
The network was written in Python using the PyTorch software (the source code is publicly available at https://github.com/frankheyz/s-vision). The three networks were also trained for comparison using their open-source code, which can be found in the references. Table 1 summarizes the key parameters related to network training. All networks were trained on a PC of the following specifications: Intel Xeon E5-2678 W CPU, 256 GB RAM, and a single NVIDIA TITAN X GPU. Our network used a minimum amount of training data (see Supplementary Note 1 in Ref. [28] for data augmentation and training) and achieved excellent quantitative performance. The training time of a single volumetric input was just 6 min, which is substantially shorter than that of the other methods. 2D and 3D images could be inferred by our network, demonstrating a clear advantage over 2D super-resolution networks. Moreover, the 3D inference speed was fast because the small-sized network could infer large input images quickly with fewer stitches.
Summary of Parameters Related to Network Training for Performance Comparison
| Methods | Modality | Training Image Size | Training | Training | 2D Inference | 3D Inference |
|---|---|---|---|---|---|---|
| DFCAN | Nikon A1R-MP | 0.6 GB | 2.5 h | 0.2 s | N/A | |
| PSSR | 1.2 h | 0.6 s | N/A | |||
| DSP-Net | 11.2 h | N/A | 120 s | |||
| Ours | N/A | 6 min | 0.5 s | 62 s |
Acknowledgment
Acknowledgment. We thank Dr. H. Zhang, Dr. S. Wang, and Dr. S. He for assistance and discussion with algorithm development and evaluation.
References
[7] Y. Lecun, Y. Bengio, G. Hinton. Deep learning. Nature, 521, 436-444(2015).
[21] C. Dong, C. C. Loy, X. Tang. Accelerating the super-resolution convolutional neural network. European Conference on Computer Vision, 391-407(2016).
[25] M. Zontak, M. Irani. Internal statistics of a single natural image. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 977-984(2011).
[26] A. Shocher, N. Cohen, M. Irani. Zero-shot super-resolution using deep internal learning. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 3118-3126(2018).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20