
Rui Sun, Xiaoquan Shan, Qijing Sun, Chunjun Han, Xudong Zhang. NIR-VIS face image translation method with dual contrastive learning framework[J]. Opto-Electronic Engineering, 2022, 49(4): 210317
- Opto-Electronic Engineering
- Vol. 49, Issue 4, 210317 (2022)
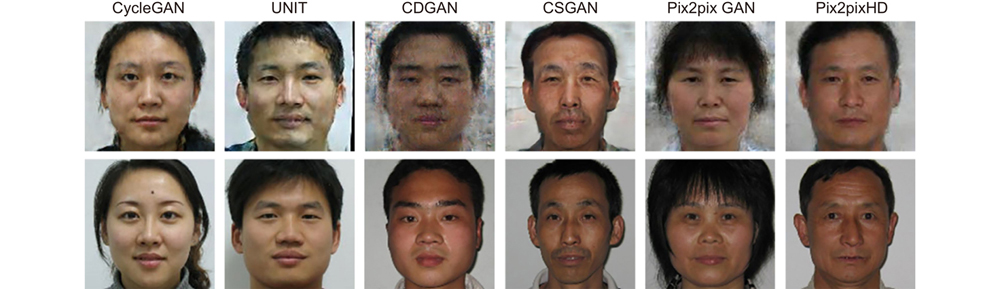
Fig. 1. Comparison of the VIS image (the first row) generated by some algorithms from NIR domain with the real visible image (the last row)
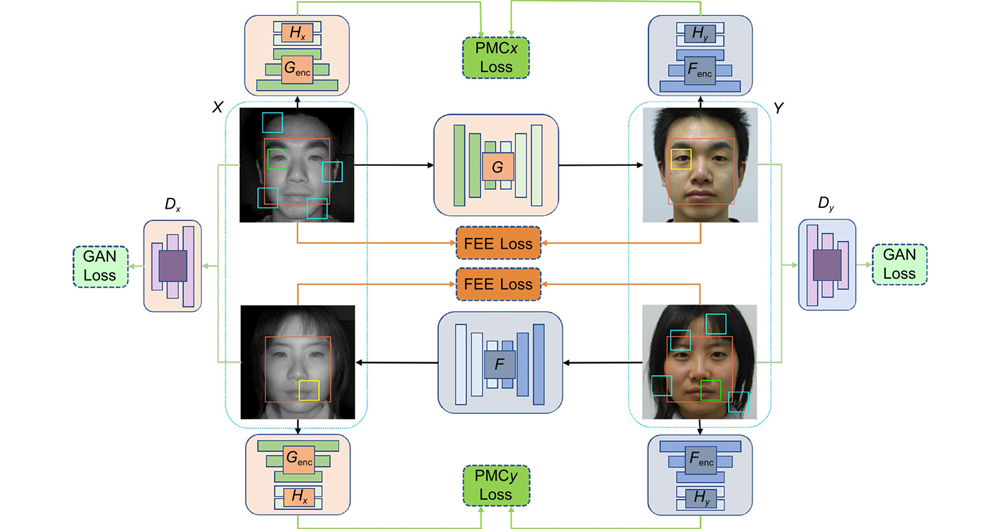
Fig. 2. The structure diagram of the proposed method. To simplify the network structure, the identity loss is not indicated in the figure, see Section 2.4.4 for details
Fig. 3. The structure diagram of generator in the proposed method
Fig. 4. Crop out facial regions and extract edges from face images in NIR and VIS conditions respectively
Fig. 5. The comparison experimental results on two datasets. From left to right: input NIR face image, CycleGAN, CSGAN, CDGAN, UNIT, Pix2pixHD, the proposed method, and real VIS face image. Where rows Ⅰ~Ⅲ are from NIR-VIS Sx1 dataset, and rows Ⅳ~Ⅶ are from NIR-VIS Sx2 dataset
Fig. 6. Results of the ablation experiments on two datasets. From left to right: input NIR face image, Baseline method, the proposed method without StyleGAN2、
Fig. 7. Comparison of edge images obtained by using each edge extraction method separately. From left to right: real face image, Roberts operator, Prewitt operator, Sobel operator, Laplacian operator, Canny operator
Fig. 8. The effect of different values of
|
Table 1. Performance comparison of image translation networks on the NIR-VIS Sx1 dataset
|
Table 2. Performance comparison of image translation networks on the NIR-VIS Sx2 dataset
|
Table 3. Comparison of FID performance and average single test time of each image translation network on different datasets
|
Table 4. Performance comparison of ablation methods on the NIR-VIS Sx1 dataset
|
Table 5. Performance comparison of applying the Prewitt operator and Sobel operator respectively on the NIR-VIS Sx1 dataset

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20