
Zhihong Zhang, Chao Deng, Yang Liu, Xin Yuan, Jinli Suo, Qionghai Dai. Ten-mega-pixel snapshot compressive imaging with a hybrid coded aperture[J]. Photonics Research, 2021, 9(11): 2277
- Photonics Research
- Vol. 9, Issue 11, 2277 (2021)
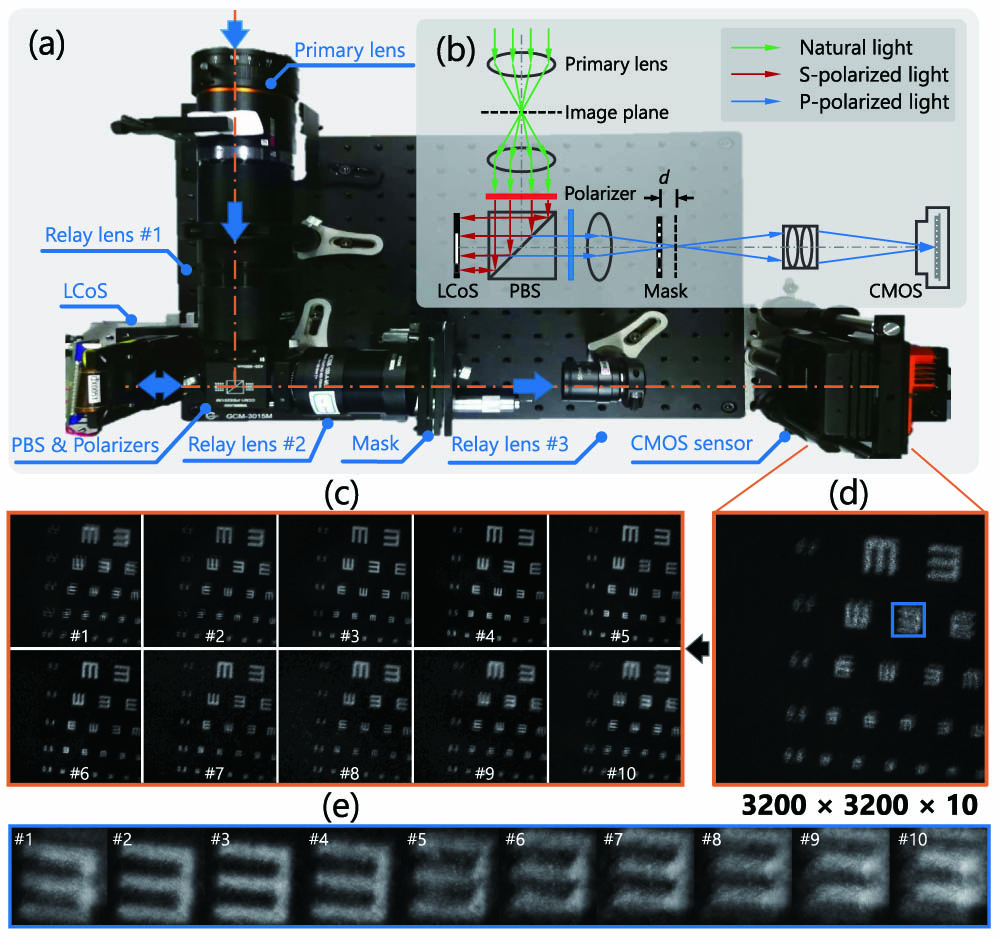
Fig. 1. Our 10-mega-pixel video SCI system (a) and the schematic (b). Ten high-speed (200 fps) high-resolution (3200 × 3200
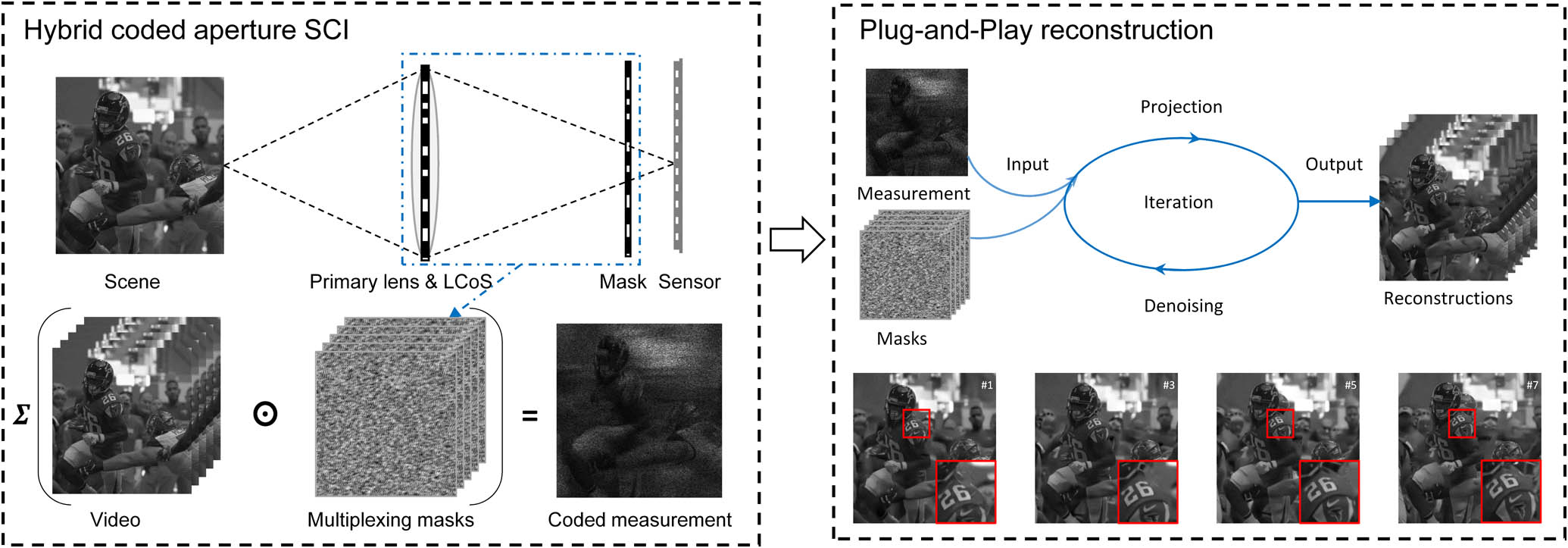
Fig. 2. Pipeline of the proposed large-scale HCA-SCI system (left) and the PnP reconstruction algorithms (right). Left: During the encoded photography stage, a dynamic low-resolution mask at the aperture plane and a static high-resolution mask close to the sensor plane work together to generate a sequence of high-resolution codes to encode the large-scale video into a snapshot. Right: In the decoding, the video is reconstructed under a PnP framework incorporating deep denoising prior and TV prior into a convex optimization (GAP), which leverages the good convergence of GAP and the high efficiency of the deep network.
Fig. 3. Illustration of the multiplexed mask generation. For the same scene point, its images generated by different sub-apertures (marked as blue, yellow, and red, respectively) intersect the mask plane with different regions and are thus encoded with corresponding (shifted) random masks before summation at the sensor. The multiplexing would raise the light flux for high SNR recording, while doing so only with slight performance degeneration.
Fig. 4. Multiplexing pattern schemes used in our experiments (taking Cr = 6 512 × 512
Fig. 5. Reconstruction results and comparison with state-of-the-art algorithms on simulated data at different resolutions (left: 256 × 256 512 × 512 1024 × 1024 Cr = 10 Cr = 20 512 × 512 1024 × 1024 Visualization 1 , Visualization 2 , Visualization 3 , Visualization 4 , Visualization 5 , and Visualization 6 for the reconstructed videos.
Fig. 6. Noise robustness comparison between multiplexed and non-multiplexed masks.
Fig. 7. Reconstruction results of the PnP–TV–FastDVDNet on real data captured by our HCA-SCI system (Cr = 6 3200 × 3200 400 × 400
Fig. 8. Reconstruction comparison between the GAP–TV, PnP–FFDNet, and PnP–TV–FastDVDNet on real data captured by our HCA-SCI system (Cr = 6 3200 × 3200 512 × 512 Visualization 7 for the reconstructed videos.
|
Table 1. Average Results of PSNR in dB (left entry in each cell) and SSIM (right entry in each cell) by Different Algorithms (Cr = 10 a
|
Table 2. Average Results of PSNR in dB (left entry in each cell) and SSIM (right entry in each cell) by Different Algorithms (Cr = 20 a
|
Table 3. PnP–TV–FastDVDNet for HCA-SCI

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20