
Yuyao Huang, Tingzhao Fu, Honghao Huang, Sigang Yang, Hongwei Chen, "Sophisticated deep learning with on-chip optical diffractive tensor processing," Photonics Res. 11, 1125 (2023)
- Photonics Research
- Vol. 11, Issue 6, 1125 (2023)
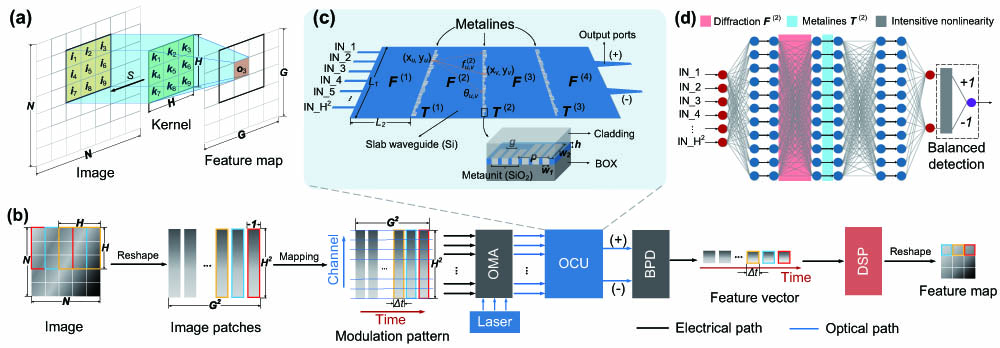
Fig. 1. Principle of optical image convolution based on OCU. (a) Operation principle of 2D convolution. A fixed kernel with size of H × H N × N S G × G G = ⌊ ( N − H ) / S + 1 ⌋ H 2 L 1 × L 2 L 2 w 1 × w 2 × h g p w 2 F T
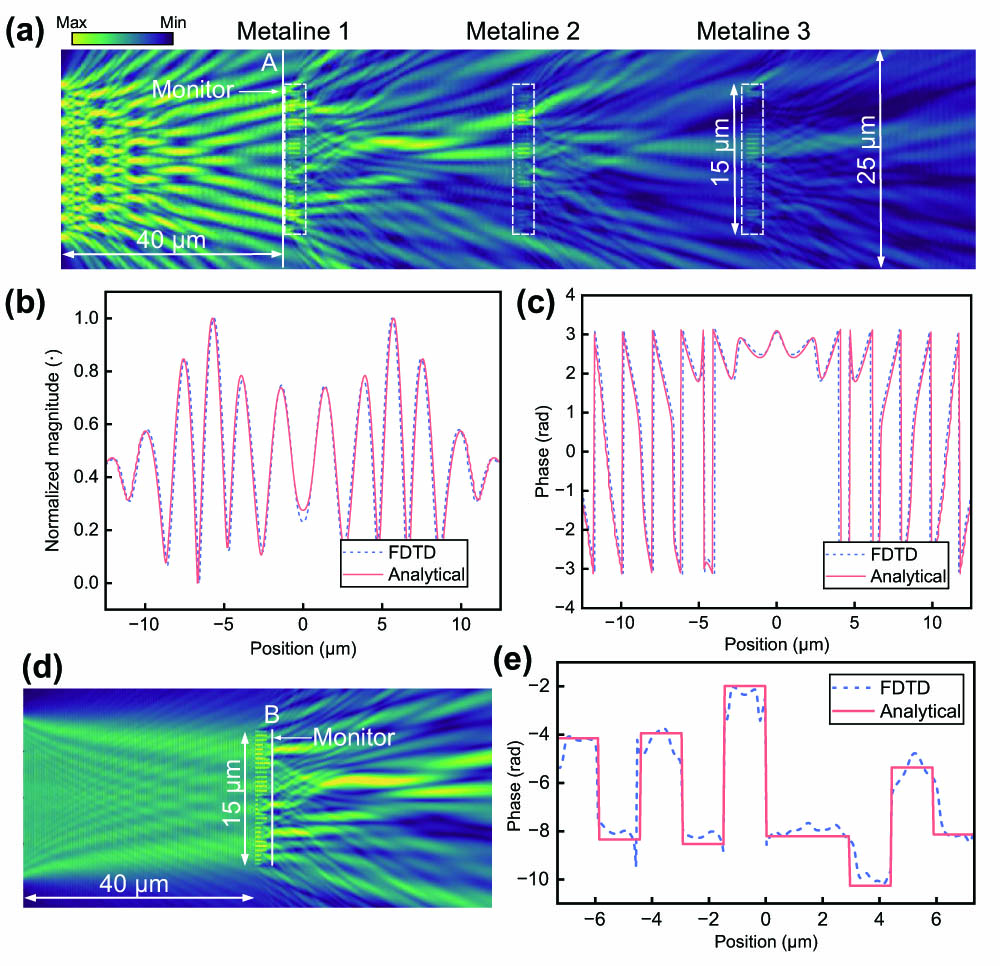
Fig. 2. (a) Optical field of the OCU evaluated by FDTD method. A monitor is set at Position A to receive the optical field of the incident light. (b) Magnitude and (c) phase response of the optical field at Position A (red solid curve) match well with the analytical model (purple dash curve) in Eq. (5 ). (d) Optical field of the metaline with incident light of a plane wave. A monitor is set behind the metaline at Position B to obtain its phase response. (e) The analytical model (purple dash curve) of Eq. (6 ) fits well with the FDTD calculation (red solid curve).
Fig. 3. Concept of structural reparameterization in deep learning. Network Structure 1 has a transfer function of F G y x
Fig. 4. Training and the inference phase of an OCU to perform real-valued optical convolution with the idea of SRP in deep learning. (a) A 128 × 128 256 × 256
Fig. 5. Well-agreed convolution results between the ground truths and the outputs of OCUs with eight unique real-valued convolution kernels, with average PSNR of 36.58 dB. GT, ground truth.
Fig. 6. Architecture of oCNN for image classification. Images with size of N × N × C C G 2 × C · H 2 H C · H 2 q C C
Fig. 7. Classification results of oCNNs for (a) fashion-MNIST and (b) CIFAR-4 data sets. Accuracies of 91.63% and 86.25% are obtained with oCNNs for the corresponding two data sets, which outperform their electrical counterparts with 1.14% and 1.75% respectively. (c) Classification performance evaluations on both data sets with respect to two main physical parameters of OCU: the number of metaunit per layer and the number of the exploited metaline layer. (d) 2D visualizations of the two applied data sets with t-distributed stochastic neighbor embedding (t-SNE) method.
Fig. 8. (a) Architecture of the proposed oDnCNN. A Gaussian noisy image with a known noise level is first flattened and modulated into a lightwave and then sent to oDnCNN, which is composed of three parts: input layer with OCL and ReLU; middle layer with an extra batch normalization between the two; and output layer with only an OCL. After the oDnCNN, a residual image is obtained, which is the extracted noise. By subtracting the noisy image with the extracted residual one, the clean image can be aquired. OCL, optical convolution layer; ReLU, rectified linear unit; BN, batch normalization. (b) The denoised result of Set12 data set leveraged by the proposed oDnCNN with noise level σ = 20
Fig. 9. Method of OCU’s scaling for computing multiple convolutions. (a) Computing with prototype OCU. N N N K = [ K 1 , K 2 , … , K N ] K i 1 × H 2 i = 1 , 2 , … , N
Fig. 10. Highly efficient optical deep learning framework with network rebranching and optical tensor core. Deep learning models are decomposed mathematically into two parts: trunk and branch, which carry the major and minor calculations of the model, respectively. The trunk part is computed by an optical tensor core with fixed weights, and the branch part is performed by a lightweight electrical network to reconfigure the model. OTC, optical tensor core; OTU, optical tensor unit.
|
Table 1. Performance Comparisons of the Proposed oDnCNN and E-net in Average PSNR, with Noise Level σ = 10
|
Table 2. Comparison of State-of-the-Art Integrated Photonic Computing Hardwarea


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20