
Davide Pierangeli, Giulia Marcucci, Claudio Conti, "Photonic extreme learning machine by free-space optical propagation," Photonics Res. 9, 1446 (2021)
- Photonics Research
- Vol. 9, Issue 8, 1446 (2021)
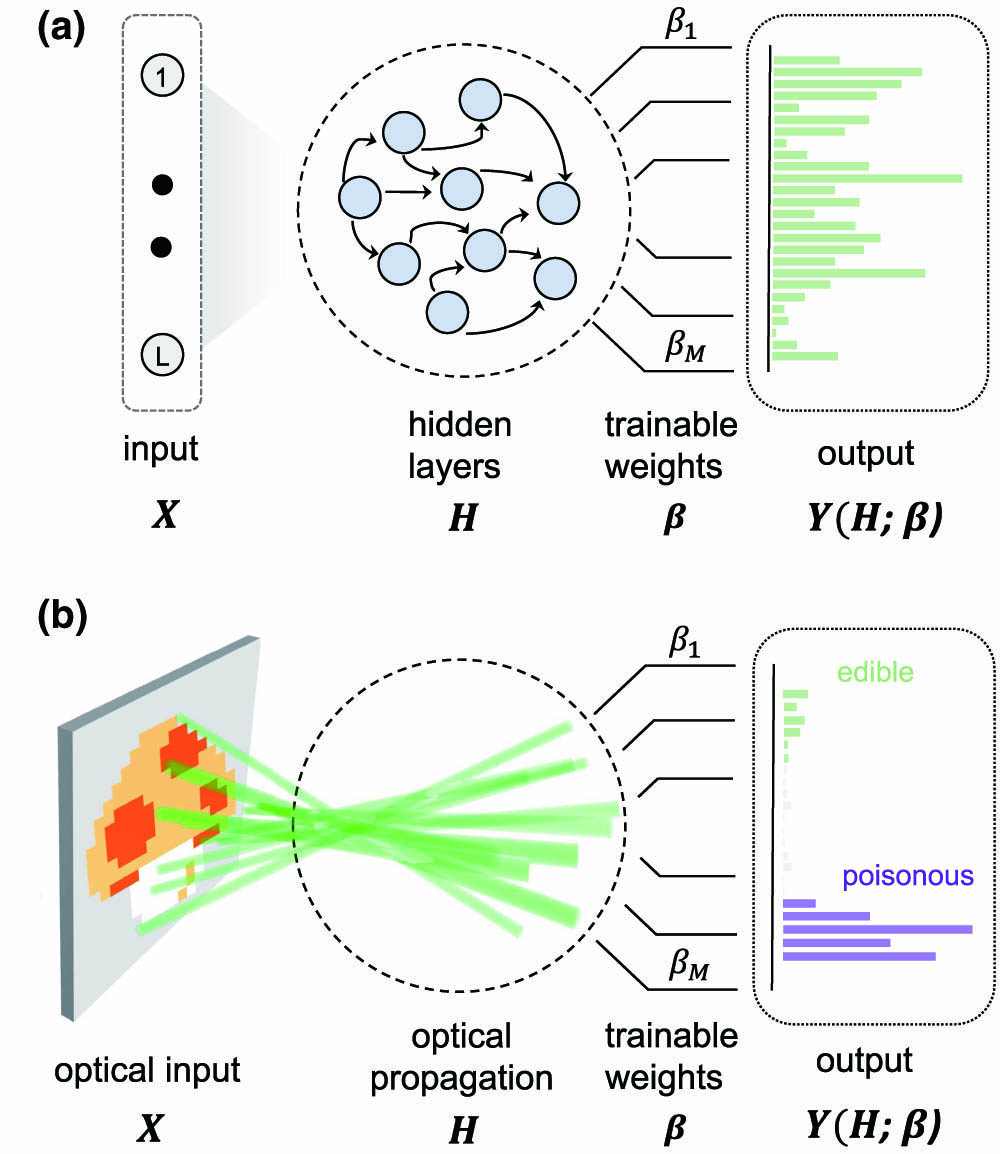
Fig. 1. Schematic architecture of the photonic extreme learning machine (PELM). (a) General ELM scheme with the input data set X H β i Y = Y ( H ; β ) M
![Learning ability of the PELM architecture. The optical computing scheme is evaluated on the MNIST data set by varying the encoding properties and feature space. (a) Input digit and 2D phase mask showing its encoding by noise embedding: the input signal overlaps with a disordered matrix. PELM training and testing error for noise embedding when varying the (b) noise amplitude and (c) its correlation length, for M=1600. (d) Input vector encoded over a carrier signal (Fourier embedding). (e) Classification error versus the number of frequencies of the embedding signal. (f) Minimum testing error with the increasing number of features M. The indicated accuracies are the best ones reported with random ELM (rELM) [47], random projections (RP) [41], and kernel ELM (kELM) [47] on the same task.](/richHtml/prj/2021/9/8/08001446/img_002.jpg)
Fig. 2. Learning ability of the PELM architecture. The optical computing scheme is evaluated on the MNIST data set by varying the encoding properties and feature space. (a) Input digit and 2D phase mask showing its encoding by noise embedding: the input signal overlaps with a disordered matrix. PELM training and testing error for noise embedding when varying the (b) noise amplitude and (c) its correlation length, for M = 1600 M
Fig. 3. Experimental implementation. (a) Sketch of the optical setup. A phase-only spatial light modulator (SLM) encodes data on the wavefront of a 532 nm continuous-wave laser. The far field in the lens focal plane is imaged on a camera. Insets show a false-color embedding matrix and training data encoded as phase blocks, respectively. (b) Detected spatial intensity distribution for a given input sample. White-colored areas reveal camera saturation in high-intensity regions, which provides the network nonlinear function. Pink boxes show some of the M M = 256
Fig. 4. Experimental performance of the PELM on classification and regression tasks. Confusion matrices on the MNIST data set for a free-space PELM, which makes use of (a) Fourier and (b) random embedding (92.18% and 92.06% accuracy, M = 4096


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20