
Kaiqiang Wang, Qian Kemao, Jianglei Di, Jianlin Zhao, "Deep learning spatial phase unwrapping: a comparative review," Adv. Photon. Nexus 1, 014001 (2022)
- Advanced Photonics Nexus
- Vol. 1, Issue 1, 014001 (2022)
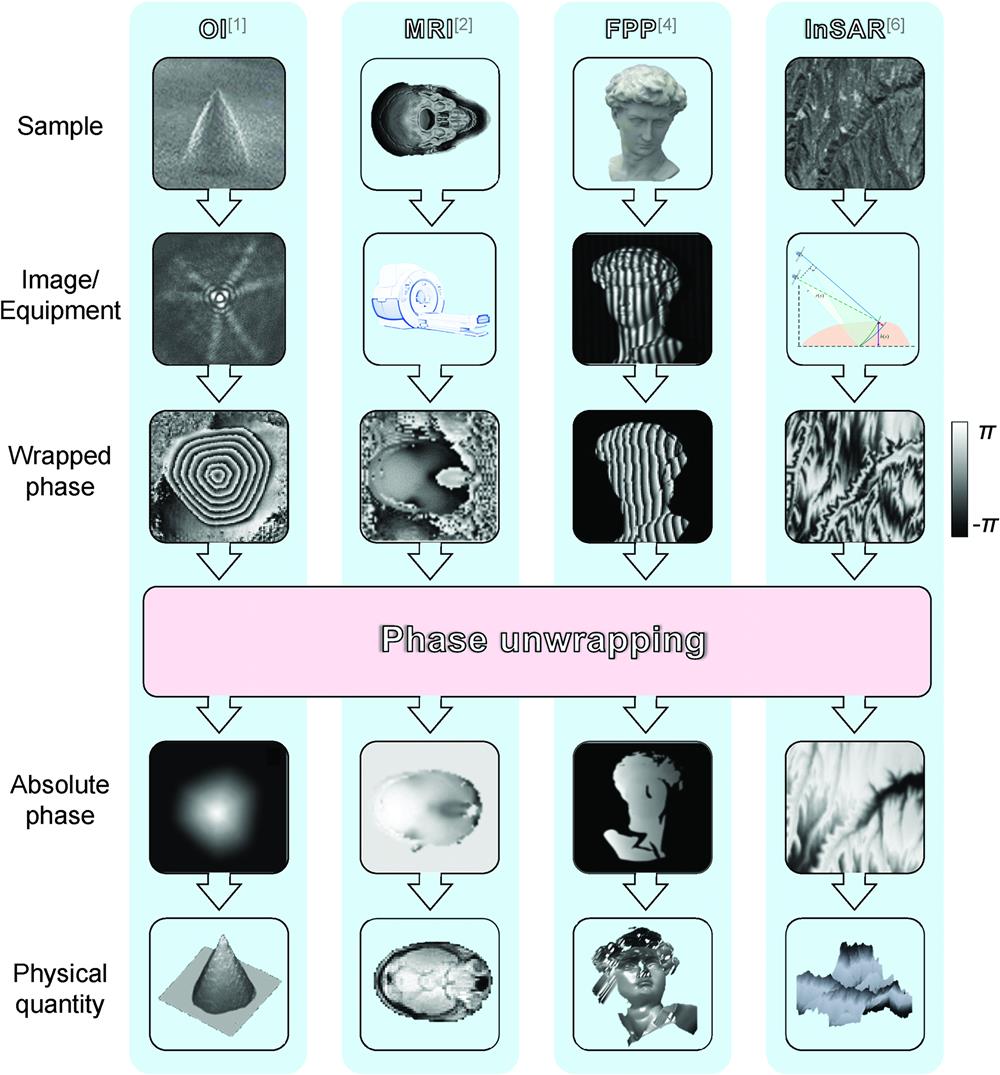
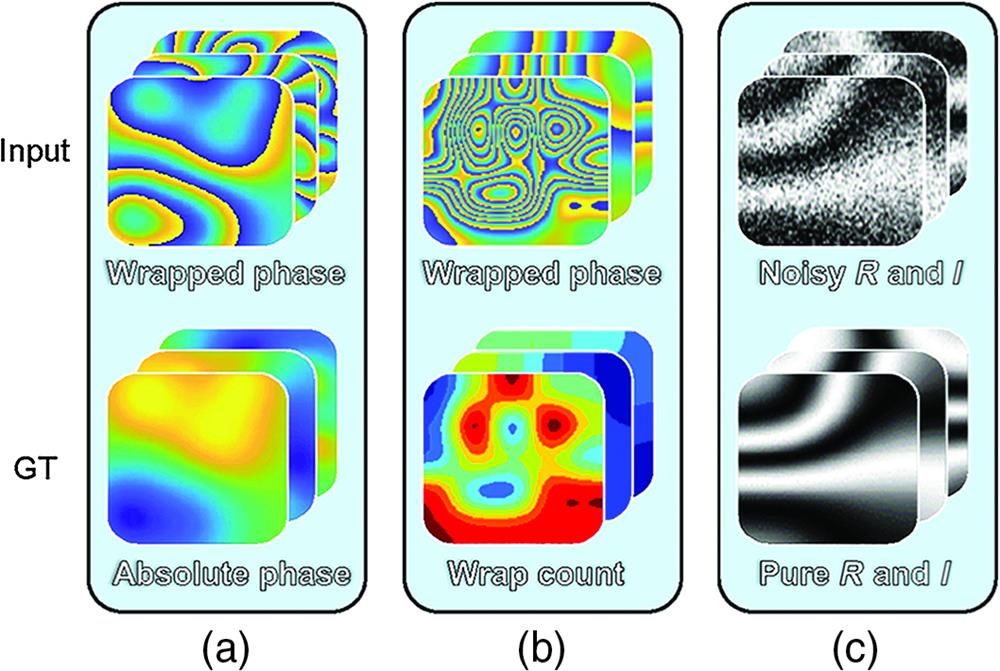
Fig. 2. Datasets of the deep-learning-involved phase unwrapping methods, for (a) dRG, (b) dWC, and (c) dDN. “
Fig. 3. Overall process of deep-learning-involved phase unwrapping methods.
Fig. 4. Illustration of the dRG method.
Fig. 5. Illustration of the dWC method.
Fig. 6. Illustration of the dDN method.
Fig. 7. An example of the RME method.
Fig. 8. An example of the GFS method.
Fig. 9. Entropy histogram of absolute phases from the D_RME, D_GFS, and D_ZPS.
Fig. 10. SAGD maps of different datasets. Red arrows and circles indicate low and high SAGD values, respectively.
Fig. 11. Mean error maps for each network. Red circles indicate high mean error value.
Fig. 12. (a) SAGD maps for D_RME and D_RME1, (b) mean error maps for RME-Net and RME1-Net. Red arrows indicate low SAGD value. Red circles indicate high mean error value and orange circles indicate the comparison part.
Fig. 13. Partial display of results from RME1-Net. “Max”, “Med,” and “Min” represent specific results with maximal, median, and minimal
Fig. 14. Results for the (a) dRG-I and (b) dWC-I in the ideal case. “Max,” “Med,” and “Min” represent specific results with maximal, median, and minimal
Fig. 15.
Fig. 16. Results for (a) dRG-N, (b) dWC-N, and (c) dDN-N in the noisy case. “GT” represents the pure GT (pure absolute phase), while “GT1” represents the noisy GT (noisy absolute phase). “Max,” “Med,” and “Min” represent specific results with maximal, median, and minimal
Fig. 17. Results in different noise levels. Solid and dashed lines represent the deep-learning-involved and traditional methods, respectively.
Fig. 18. Results for (a) dRG-I, (b) dWC-I, (c) dRG-D, (d) dWC-D, (e) line-scanning, (f) LS, and (g) QG methods in the discontinuous case. “Max,” “Med,” and “Min” represent specific results with maximal, median, and minimal
Fig. 19. Results for (a) dRG-A, (b) dWC-A, (c) line-scanning, (d) LS, and (e) QG methods in the aliasing case. “Max,” “Med,” and “Min” represent specific results with maximal, median, and minimal
Fig. 20. Results for (a) dRG-M, (b) dWC-M, (c) line-scanning, (d) LS, and (e) QG methods in the mixed case. “Max,” “Med,” and “Min” represent specific results with maximal, median, and minimal
Fig. 21. Schematic diagram of pretraining and retraining.
Fig. 22. Loss plot of pretrained and initialized networks.
|
Table 1. Summary of deep-learning-involved phase unwrapping methods. “—” indicates “not available.”
|
Table 2. Summary of datasets. “—” indicates “not available.”
|
Table 3. RMSE m RMSE sd
|
Table 4. Summary of networks and corresponding datasets. The form of the dataset is {Input, GT}. The last letter of the network name is the case (“I N D A M
|
Table 5. RMSE m RMSE sd
|
Table 6. RMSE m RMSE sd
|
Table 7. RMSE m RMSE sd
|
Table 8. RMSE m RMSE sd
|
Table 9. RMSE m RMSE sd
|
Table 10. Performance statistics in the ideal, noisy, discontinuous, and aliasing cases. “✓” represents “capable.” “✓✓” represents “best and recommended.” “✗” represents “incapable.” “—” indicates “not applicable.”


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20