
Meihua Liao, Shanshan Zheng, Shuixin Pan, Dajiang Lu, Wenqi He, Guohai Situ, Xiang Peng. Deep-learning-based ciphertext-only attack on optical double random phase encryption[J]. Opto-Electronic Advances, 2021, 4(5): 200016-1
- Opto-Electronic Advances
- Vol. 4, Issue 5, 200016-1 (2021)
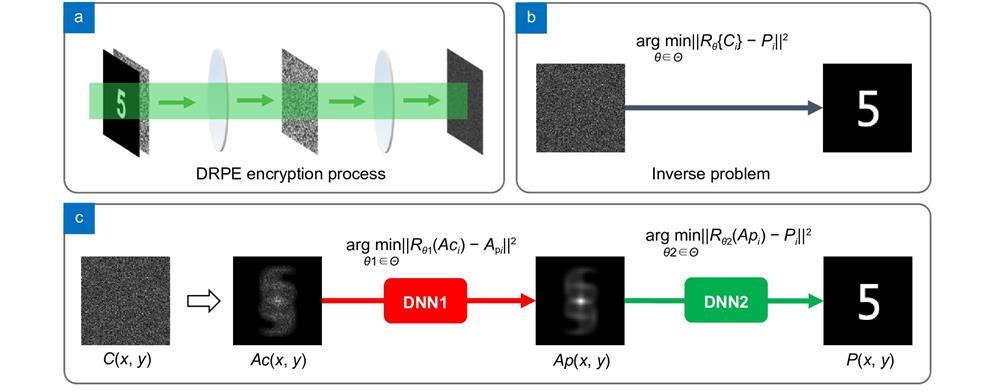
Fig. 1. Overview of learning-based COA on DRPE . (a ) The encryption process of DRPE is a forward propagation process. (b ) The COA is an inverse problem, aiming to obtain an optimized estimate of the plaintext from the ciphertext. (c ) Flowchart of the proposed COA method, where two DNNs (DNN1 and DNN2) are used in serial to respectively learn the removal of speckle noise from the autocorrelation of the ciphertext Ac and the prediction of the final plaintext P from its autocorrelation Ap .
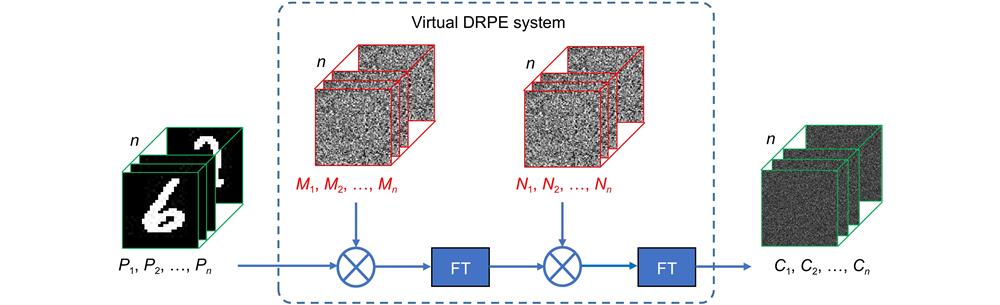
Fig. 2. Acquisition of the training data by designing a virtual DRPE system . A set of randomly generated RPMs (M 1, M 2,…,M n ) are placed at the spatial domain, and another set of randomly generated RPMs (N 1, N 2,…,N n ) are placed at the frequency domain. The ground truth plaintext images (P 1, P 2,…,P n ) are encrypted one-by-one and the corresponding ciphertext dataset (C 1, C 2,…,C n ) can be obtained.
Fig. 3. Structure of the employed DNNs . (a ) The architecture of DNN1, which takes the DnCNN structure. (b ) The architecture of DNN2, which takes the general encoder–decoder U-net structure. The encoder gradually condenses the lateral spatial information into high-level feature maps with growing depths; the decoder reverses the process by recombining the information into feature maps with gradually increased lateral details.
Fig. 4. Attack results by our proposed COA approach . (a ) The given ciphertexts. (b ) The autocorrelations of ciphertexts. (c ) Outputs of DNN1. (d ) Outputs of DNN2. (e ) The ground-truth plaintext images.
Fig. 5. Quantitative evaluation of the reliability of the proposed COA method . (a ) CC values to the number of tests. (b ) The example of the prediction rotated 180 degrees and the ground-truth, which have the similar autocorrelation.
Fig. 6. Robustness test against cropping and noise . (a ) Ciphertexts with cropping ratio 1/16 and 1/4, added zero-mean Gaussian noise with 0.01 and 0.02 variance, and added salt & pepper noise with 0.01 and 0.02 distribution density. ( b ) The corresponding autocorrelation distributions. (c ) The retrieved images by the proposed two-step learning-based COA method. (d ) The retrieved images by the one-step learning-based method.
Fig. 7. Experimental setup . SF: spatial filter, L1: collimating lens, L2: Fourier lens, P1 and P2: polarizers, RD: rotating diffuser, SLM: spatial light modulator.
Fig. 8. Experimental results . First column from left: the ground truth plaintext images “Apple” and “Banana”. Second column: the raw power spectrum images of the different types of diffusers. Third columns: the corresponding autocorrelation functions. Fourth and fifth columns: the recovered autocorrelation from DNN1 and the retrieved plaintext images from DNN2. Scale bar: 100 pixels in pictures of the second and third columns from left; 20 pixels in pictures of the first, fourth and fifth columns from left.
| |||||||||||||||||||||
Table 1. CC values between the retrieved plaintexts and the ground-truth

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20