
Meihua Liao, Shanshan Zheng, Shuixin Pan, Dajiang Lu, Wenqi He, Guohai Situ, Xiang Peng. Deep-learning-based ciphertext-only attack on optical double random phase encryption[J]. Opto-Electronic Advances, 2021, 4(5): 200016-1
- Opto-Electronic Advances
- Vol. 4, Issue 5, 200016-1 (2021)
Abstract
Introduction
Optical encryption has captured growing attentions in the past two decades owning to its inherent advantages such as parallel signal processing and high dimensional operation
Over the past few years, deep learning has attracted increasing attentions and found to be highly flexible in solving various types of ill-posed inverse problems in optical sensing and imaging
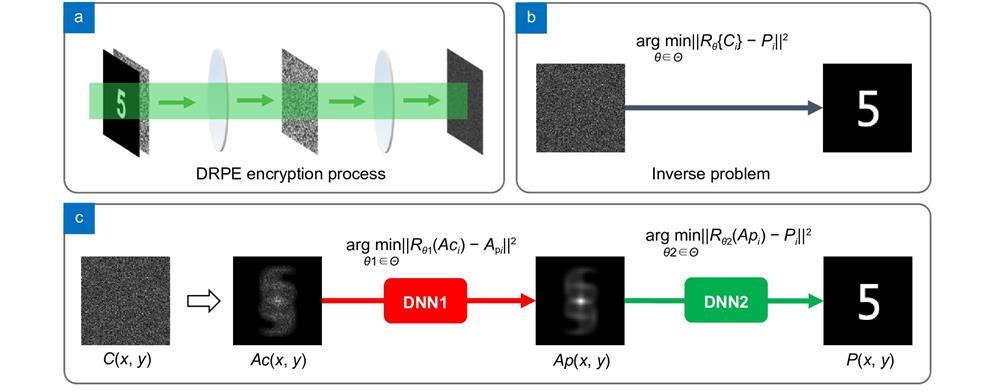
Here, we demonstrate methodologically, numerically and experimentally for the first time, to our knowledge, that the use of deep learning can solve the inverse problems in COA against the classical DRPE. To be specific, we develop a two-step deep learning framework that retrieves the plaintext from an intercepted unknown ciphertext alone. For acquiring the training data, we construct a virtual DRPE system that includes different random phase keys to provide the statistically ergodic property of the speckle pattern. We note that the autocorrelation of the ciphertext in DRPE contains the information of the autocorrelation of the plaintext, only that the former one is with some additive speckle noise. Inspired by the principle of speckle correlations, we divide the inverse problem in COA into two inverse problems: one is the removal of the speckle noise from the autocorrelation of the ciphertext, and the other is the retrieval of the plaintext from the noise-free autocorrelation. Accordingly, two cascaded deep neural networks (DNNs) are employed to respectively solve the two specific inverse problems. With appropriate training, the two trained DNNs can be easily used to predict the plaintext image from the unknown ciphertext without knowing the phase keys.
Principle and method
Learning-based COA approach
In DRPE, a plaintext can be encrypted into a white noise-like distribution by employing an optical 4f system, where two RPMs serving as the keys are placed at the input plane and Fourier plane, respectively. The optical structure of DRPE is shown in Fig. 1(a). The encryption process can be mathematically expressed as
![]()
Figure 1.
where
The encryption process of the DRPE can be considered as the forward propagation process (see Fig .1(a)), and it is defined as
where
Nevertheless, for COA, according to Kerchhoff’s principle
We have noted that the DRPE cryptosystem is essentially a coherent imaging system and the encryption formulation (Eq. (1)) can be rewritten as
where the symbol “
where the symbol “
where
Therefore, the problem to be addressed in COA on DRPE can be reformulated as two inverse problems: one is the removal of the speckle noise from the autocorrelation of the ciphertext while the other is the retrieval of the plaintext from the noise-free autocorrelation. Inspired by the aforementioned analysis while aiming at achieving a better performance with limited training data, we propose a two-step deep learning strategy for solving the problems of the COA on DRPE (see Fig. 1(c)). Specifically, the autocorrelation functions of the ciphertext and the plaintext should be calculated first as the feature to be trained. Then two cascaded DNNs are built to solve the two corresponding inverse problems, DNN1 takes the autocorrelation of the ciphertext
where
Data acquisition
For training the DNNs mentioned above, the training data should be prepared. The objective of DNN1 is to remove the speckle noise from the autocorrelation functions of ciphertexts. In the COA scenario, the intercepted ciphertext might be encrypted with any unknown RPMs. To get the better de-noising performance, the de-noising model should sufficiently encompass the statistical variations across as many RPMs as possible. Usually, different realizations of the speckle patterns can be obtained by coherently illuminating the plaintext with different random phases. This requires the use of many different random phase keys to encrypt the plaintext images to achieve the statistical ergodic property of the speckle pattern. Therefore, a virtual DRPE system (not the real one) should be designed to gather the training data. As illustrated in Fig. 2, a set of randomly generated RPMs are placed at the spatial and frequency domains in this virtual DRPE system to encrypt the plaintext images and obtain the corresponding ciphertext images, which can be expressed as
![]()
Figure 2.
Subsequently, the autocorrelations of ciphertexts
Meanwhile, the autocorrelations of plaintexts
In this way, the dataset of the autocorrelations of ciphertexts
Network model
To perform the task of de-noising, the popular DnCNN model
![]()
Figure 3.
However, for the task of de-correlation, a modified U-net architecture
where the bracket [·] denotes the concatenation of the feature-maps extracted from layers
Results and discussion
Simulations and analysis
Numerical simulations have been carried out to demonstrate the validity of the proposed learning-based COA approach. In the following numerical simulations, the size of all the images is set as 64 pixels ×64 pixels. For the training process, a total of 10000 images (5000 digits and 5000 letters) from the MNITS handwritten digit dataset
where
With the two trained DNNs at hand, now we can perform the COA test. The numerical simulation results are shown in Fig. 4, where the three columns on the left indicate the digits while another three columns on the right show letters. Figure 4(a) shows the given ciphertexts, which are generated with the testing plaintext images (different from the training dataset) in a testing DRPE system (RPMs generated by setting the random seeds as 20001−21000 for RPM1 and 21001−22000 for RPM2). With the given ciphertexts, we can calculate their autocorrelation functions, which are presented inFig. 4(b). We have removed the peaked function
![]()
Figure 4.
It should be pointed out that zero-padding of images was applied before the encryption to introduce frequency redundancy. Zero-padding operation actually has been extensively exploited and discussed in signal processing literature
To quantitatively analyze the reliability of the proposed COA method, we introduce the correlation coefficient (CC) to quantitatively evaluate the quality of the retrieved plaintext images. The CC between image A and image B are defined as follows
where
![]()
Figure 5.
Moreover, we have also investigated the robustness of the proposed method against the cropping and the noise. The results are illustrated in Fig. 6. The two images on the left side of Fig. 6(a) respectively present the cropped ciphertexts with cropping ratio 1/16 and 1/4; the two images in the middle of Fig. 6(a) present the ciphertexts added zero-mean Gaussian noise with 0.01 and 0.02 variance; the two images on the right side of Fig. 6(a) present the ciphertexts added salt & pepper noise with 0.01 and 0.02 distribution density. The calculated autocorrelation functions of the corrupted ciphertexts are displayed in Fig. 6(b). The reconstructed plaintext images by the proposed two-step deep-learning-based COA method are shown in Fig. 6(c). For comparison, the reconstructed images by the one-step “end-to-end” method (from the autocorrelation of ciphertext to the plaintext directly) are shown in Fig. 6(d). Obviously, the images shown in Fig. 6(c) can be visualized and recognized while the images shown in Fig. 6(d) are completely different from the ground-truth. To quantitatively evaluate the robust capability, we have calculated the CC between the retrieved images (Figs. 6(c) and 6(d)) and the ground-truth image (the first image from the left of Fig. 4(e)), the CC values are shown in Table 1. More data on CC values under various levels of cropping and noise were presented in Fig. S3. These results indicate that the proposed method has the better robustness against the cropping and the noise than the one-step method.
![]()
Figure 6.
| Methods | Cropping | Gaussian noise | Salt & pepper noise | |||
| Two-step method | 0.9464 | 0.7522 | 0.8958 | 0.7610 | 0.9284 | 0.8038 |
| One-step method | 0.4517 | 0.3351 | 0.3751 | 0.2914 | 0.4116 | 0.3290 |
Table 1.
Optical experiments
To further experimentally verify the effectiveness and practicability of the proposed learning-based COA approach, we designed and set up an experiment configuration that is schematically shown in Fig. 7. A continuous-wave laser (MW-SL-532/50mW) served as the illumination source. A spatial filter and a collimating lens were placed behind the laser. A spatial light modulator (SLM) (Holoeye LC2002, transmission) was placed at the input plane to display the plaintext images. Two orthogonally oriented polarizers were placed before and after the SLM to ensure that the SLM worked in amplitude mode. A thin diffuser served as the RPM was placed next to the SLM. A high dynamic range CMOS camera (PCO edge 4.2, 2160 pixels ×2160 pixels with a pixel size of 6.5 μm × 6.5 μm, dynamic range of 16 bits) was placed on the back focal plane of the Fourier lens (f = 150 mm) to capture the power spectrum. Considering the effect of the RPM2 could be removed by the autocorrelation operation, we do not set the second RPM2 at frequency plane in the following experiments.
![]()
Figure 7.
In the training process, 1000 images (28 pixels ×28 pixels) from the Quickdraw dataset
![]()
Figure 8.
Conclusions
In summary, we have developed a two-step deep learning strategy and demonstrated numerically and experimentally that it is capable of achieving COA on the classical DRPE system. By incorporating the deep learning method with the speckle correlation technique, the proposed learning-based COA scheme employs two DNNs to respectively learn the removal of speckle noise in the autocorrelation domain and the de-correlation operation for deciphering plaintext images. Compared with existing learning-based attack methods, the proposed method has a unique character that the mapping relationships of autocorrelation features are trained, instead of the random phase keys of DRPE system so that our approach allows to retrieve the plaintext from the only ciphertext without any other resources. Furthermore, the proposed COA method can be very efficient because the plaintext can be retrieved from the intercepted ciphertext in real-time with use of the trained DNNs. One of limitations of the proposed method is that the capacity of the generalization of de-correlation DNN model is limited, and this COA approach works well only when the test images are similar to those in the training dataset. Therefore, it should be better if the training dataset includes more types of plaintext images since the training process of two DNNs can be done before the real COA process.
References
[1] B Javidi, A Carnicer, M Yamaguchi, T Nomura, E Pérez-Cabré et al. Roadmap on optical security. J Opt, 18, 083001(2016).
[2] A Carnicer, B Javidi. Optical security and authentication using nanoscale and thin-film structures. Adv Opt Photonics, 9, 218(2017).
[3] P Refregier, B Javidi. Optical image encryption based on input plane and Fourier plane random encoding. Opt Lett, 20, 767-769(1995).
[4] G Unnikrishnan, J Joseph, K Singh. Optical encryption by double-random phase encoding in the fractional Fourier domain. Opt Lett, 25, 887-889(2000).
[5] BH Zhu, ST Liu, QW Ran. Optical image encryption based on multifractional Fourier transforms. Opt Lett, 25, 1159-1161(2000).
[6] GH Situ, JJ Zhang. Double random-phase encoding in the Fresnel domain. Opt Lett, 29, 1584-1586(2004).
[7] I Mehra, NK Nishchal. Image fusion using wavelet transform and its application to asymmetric cryptosystem and hiding. Opt Express, 22, 5474-5482(2014).
[8] B Javidi, T Nomura. Securing information by use of digital holography. Opt Lett, 25, 28-30(2000).
[9] DZ Kong, LC Cao, XJ Shen, H Zhang, GF Jin. Image encryption based on interleaved computer-generated holograms. IEEE Trans Ind Inform, 14, 673-678(2018).
[10] T Nomura, B Javidi. Optical encryption using a joint transform correlator architecture. Opt Eng, 39, 2031-2035(2000).
[11] Y Zhang, B Wang. Optical image encryption based on interference. Opt Lett, 33, 2443-2445(2008).
[12] W Chen, XD Chen, CJR Sheppard. Optical image encryption based on diffractive imaging. Opt Lett, 35, 3817-3819(2010).
[13] P Clemente, V Durán, V Torres-Company, E Tajahuerce, J Lancis. Optical encryption based on computational ghost imaging. Opt Lett, 35, 2391-2393(2010).
[14] YS Shi, T Li, YL Wang, QK Gao, SG Zhang et al. Optical image encryption via ptychography. Opt Lett, 38, 1425-1427(2013).
[15] Applied Cryptography: Protocols, Algorithms, and Source Code in C 2nd ed (Wiley, New York, 1996).
[16] XC Cheng, LZ Cai, YR Wang, XF Meng, H Zhang et al. Security enhancement of double-random phase encryption by amplitude modulation. Opt Lett, 33, 1575-1577(2008).
[17] MH Liao, WQ He, DJ Lu, JC Wu, X Peng. Security enhancement of the phase-shifting interferometry-based cryptosystem by independent random phase modulation in each exposure. Opt Lasers Eng, 89, 34-39(2017).
[18] SK Sahoo, DL Tang, C Dang. Enhancing security of incoherent optical cryptosystem by a simple position-multiplexing technique and ultra-broadband illumination. Sci Rep, 7, 17895(2017).
[19] X Peng, HZ Wei, P Zhang. Chosen-plaintext attack on lensless double-random phase encoding in the Fresnel domain. Opt Lett, 31, 3261-3263(2006).
[20] MH Liao, DJ Lu, WQ He, X Peng. Optical cryptanalysis method using wavefront shaping. IEEE Photonics J, 9, 2200513(2017).
[21] X Peng, P Zhang, HZ Wei, B Yu. Known-plaintext attack on optical encryption based on double random phase keys. Opt Lett, 31, 1044-1046(2006).
[22] U Gopinathan, DS Monaghan, TJ Naughton, JT Sheridan. A known-plaintext heuristic attack on the Fourier plane encryption algorithm. Opt Express, 14, 3181-3186(2006).
[23] X Peng, HQ Tang, JD Tian. Ciphertext-only attack on double random phase encoding optical encryption system. Acta Phys Sin, 56, 2629-2636(2007).
[24] CG Zhang, MH Liao, WQ He, X Peng. Ciphertext-only attack on a joint transform correlator encryption system. Opt Express, 21, 28523-28530(2013).
[25] XL Liu, JC Wu, WQ He, MH Liao, CG Zhang et al. Vulnerability to ciphertext-only attack of optical encryption scheme based on double random phase encoding. Opt Express, 23, 18955-18968(2015).
[26] JR Fienup. Reconstruction of an object from the modulus of its Fourier transform. Opt Lett, 3, 27-29(1978).
[27] JR Fienup. Phase retrieval algorithms: a comparison. Appl Opt, 21, 2758-2769(1982).
[28] M Hayes, J Lim, A Oppenheim. Signal reconstruction from phase or magnitude. IEEE Trans Acoust Speech Signal Process, 28, 672-680(1980).
[29] Proceedings of the 8th IEEE International Conference on Electronics, Circuits and Systems 1403–1406 (IEEE, 2001). https://doi.org/10.1109/ICECS.2001.957477.
[30] Proceedings of 2006 International Conference on Computational Inteligence for Modelling Control and Automation and International Conference on Intelligent Agents Web Technologies and International Commerce 56–56 (IEEE, 2006). http://doi.org/10.1109/CIMCA.2006.172.
[31] T Isernia, V Pascazio, R Pierri, G Schirinzi. Image reconstruction from Fourier transform magnitude with applications to synthetic aperture radar imaging. J Opt Soc Am A, 13, 922-934(1996).
[32] RW Gerchberg, WO Saxton. A practical algorithm for the determination of phase from image and diffraction plane pictures. Optik, 35, 237-246(1972).
[33] D Griffin, J Lim. Signal estimation from modified short-time Fourier transform. IEEE Trans Acoust Speech Signal Process, 32, 236-243(1984).
[34] Y Shechtman, YC Eldar, O Cohen, HN Chapman, JW Miao et al. Phase retrieval with application to optical imaging: a contemporary overview. IEEE Signal Process Mag, 32, 87-109(2015).
[35] MH Liao, WQ He, DJ Lu, X Peng. Ciphertext-only attack on optical cryptosystem with spatially incoherent illumination: from the view of imaging through scattering medium. Sci Rep, 7, 41789(2017).
[36] MH Liao, DJ Lu, WQ He, X Peng. Speckle-correlation-based ciphertext-only attack on the double random phase encoding scheme. Proc SPIE, 10250, 102502i(2017).
[37] GW Li, WQ Yang, DY Li, GH Situ. Cyphertext-only attack on the double random-phase encryption: experimental demonstration. Opt Express, 25, 8690-8697(2017).
[38] G Barbastathis, A Ozcan, GH Situ. On the use of deep learning for computational imaging. Optica, 6, 921-943(2019).
[39] LW Chen, YM Yin, Y Li, MH Hong. Multifunctional inverse sensing by spatial distribution characterization of scattering photons. Opto-Electron Adv, 2, 190019(2019).
[40] AV Saetchnikov, EA Tcherniavskaia, VA Saetchnikov, A Ostendorf. Deep-learning powered whispering gallery mode sensor based on multiplexed imaging at fixed frequency. Opto-Electron Adv, 3, 200048(2020).
[41] US Kamilov, IN Papadopoulos, MH Shoreh, A Goy, C Vonesch et al. Learning approach to optical tomography. Optica, 2, 517-522(2015).
[42] M Lyu, W Wang, H Wang, HC Wang, GW Li et al. Deep-learning-based ghost imaging. Sci Rep, 7, 17865(2017).
[43] F Wang, H Wang, HC Wang, GW Li, GH Situ. Learning from simulation: an end-to-end deep-learning approach for computational ghost imaging. Opt Express, 27, 25560-25572(2019).
[44] HR Zuo, ZY Xu, JL Zhang, G Jia. Visual tracking based on transfer learning of deep salience information. Opto-Electron Adv, 3, 190018(2020).
[45] Y Rivenson, YB Zhang, H Günaydın, D Teng, A Ozcan. Phase recovery and holographic image reconstruction using deep learning in neural networks. Light Sci Appl, 7, 17141(2018).
[46] H Wang, M Lyu, GH Situ. eHoloNet: a learning-based end-to-end approach for in-line digital holographic reconstruction. Opt Express, 26, 22603-22614(2018).
[47] A Sinha, J Lee, S Li, G Barbastathis. Lensless computational imaging through deep learning. Optica, 4, 1117-1125(2017).
[48] MJ Cherukara, YSG Nashed, RJ Harder. Real-time coherent diffraction inversion using deep generative networks. Sci Rep, 8, 16520(2018).
[49] F Wang, YM Bian, HC Wang, M Lyu, G Pedrini et al. Phase imaging with an untrained neural network. Light Sci Appl, 9, 77(2020).
[50] S Li, M Deng, J Lee, A Sinha, G Barbastathis. Imaging through glass diffusers using densely connected convolutional networks. Optica, 5, 803-813(2018).
[51] YZ Li, YJ Xue, L Tian. Deep speckle correlation: a deep learning approach toward scalable imaging through scattering media. Optica, 5, 1181-1190(2018).
[52] CA Metzler, F Heide, P Rangarajan, MM Balaji, A Viswanath et al. Deep-inverse correlography: towards real-time high-resolution non-line-of-sight imaging. Optica, 7, 63-71(2020).
[53] M Lyu, H Wang, GW Li, SS Zheng, GH Situ. Learning-based lensless imaging through optically thick scattering media. Adv Photonics, 1, 036002(2019).
[54] H Hai, SX Pan, MH Liao, DJ Lu, WQ He et al. Cryptanalysis of random-phase-encoding-based optical cryptosystem via deep learning. Opt Express, 27, 21204-21213(2019).
[55] LN Zhou, Y Xiao, W Chen. Machine-learning attacks on interference-based optical encryption: experimental demonstration. Opt Express, 27, 26143-26154(2019).
[56] LN Zhou, Y Xiao, W Chen. Vulnerability to machine learning attacks of optical encryption based on diffractive imaging. Opt Lasers Eng, 125, 105858(2020).
[57] Y Qin, YH Wan, Q Gong. Learning-based chosen-plaintext attack on diffractive-imaging-based encryption scheme. Opt Lasers Eng, 127, 105979(2020).
[58] LN Zhou, Y Xiao, W Chen. Learning-based attacks for detecting the vulnerability of computer-generated hologram based optical encryption. Opt Express, 28, 2499-2510(2020).
[59] Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention 234–241 (Springer, 2015). http://doi.org/10.1007/978-3-319-24574-4_28.
[60] K Zhang, WM Zuo, YJ Chen, DY Meng, L Zhang. Beyond a Gaussian denoiser: residual learning of deep CNN for image denoising. IEEE Trans Image Process, 26, 3142-3155(2017).
[61] Y LeCun, L Bottou, Y Bengio, P Haffner. Gradient-based learning applied to document recognition. Proc IEEE, 86, 2278-2324(1998).
[62]
[63] arXiv: 1704.03477 (2017).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20