 AI Video Guide
AI Video Guide  AI Picture Guide
AI Picture Guide AI One Sentence
AI One Sentence

Peng-Yu Jiang, Zheng-Ping Li, Wen-Long Ye, Ziheng Qiu, Da-Jian Cui, Feihu Xu, "High-resolution 3D imaging through dense camouflage nets using single-photon LiDAR," Adv. Imaging 1, 011003 (2024)
- Advanced Imaging
- Vol. 1, Issue 1, 011003 (2024)
Note: This section is automatically generated by AI . The website and platform operators shall not be liable for any commercial or legal consequences arising from your use of AI generated content on this website. Please be aware of this.
Abstract
Keywords
1. Introduction
The ability to produce multi-layered three-dimentional (3D) imagery is of utmost importance in various applications in remote sensing[1,2] and rescue operations in surveillance and reconnaissance[3,4]. The application scenarios include the viewing of partially obscured targets like camouflage nets through semitransparent materials such as windows, and through distributed reflective media like foliage. However, conventional two-dimentional (2D) optical imaging approaches exhibit poor performance in multi-layer scenarios with foreground clutter. This is primarily due to the lack of depth information, which prevents effective separation of the target from the foreground clutter. In recent years, active imaging methods have been proposed to tackle this challenge, including millimeter wave radar[5,6] and Wi-Fi imaging[7,8]. These methods leverage the inherent ability of mm-wave and Wi-Fi signals to penetrate the clutter in front of the target. Nevertheless, it is important to note that the resolution of these methods is relatively inferior compared to optical approaches. As a result, a combination of high-resolution optical imaging and active imaging methods has positioned light detection and ranging (LiDAR)[4,9] as a compelling technology for imaging partially concealed scenarios.
Single-photon LiDAR has witnessed rapid development because it can offer high temporal resolution and high sensitivity by using time-correlated single-photon counting (TCSPC) techniques[10–13]. The high temporal resolution permits excellent surface-to-surface resolution for 3D imaging of multi-depth scenarios[14]. The computational imaging algorithms have witnessed remarkable progress in processing the single photon data of complex scenes efficiently[15–17]. Moreover, photon-efficient imaging algorithms[18–22] have shown good performance in dealing with low return signals and high background noise, which has been successfully demonstrated in several challenging scenarios including imaging through clutter[14,23], long-range depth imaging[24–29], non-line-of-sight imaging[30–32], and imaging through high levels of scattering media[33–39].
Researchers have foreseen the potential of single-photon LiDAR in imaging of camouflaged scenarios and carried out experiments. For instance, the Jigsaw airborne system demonstrated the capability of detecting hidden objects using foliage-penetrating 3D imaging[4]. Wallace et al. reconstructed the depth profile of an object behind a wooden trellis fence using a scanning sensor[40]. Tobin et al. presented a scanning transceiver system for imaging targets through camouflaged nets[23]. These results employed a scanning-based single-photon LiDAR system, which requires a relatively long acquisition time. The emergence of single-photon avalanche diode (SPAD) detector arrays significantly decreases the acquisition time by collecting returned photons in a parallel way[41–44]. Tachella et al. utilized a SPAD array to show the remarkable real-time imaging through camouflage nets using plug-and-play point cloud denoisers[15]. However, due to technological constraints, SPAD array-based systems normally exhibit fewer pixels and lower time resolution compared to single-point scanning sensors, leading to reduced imaging resolution.
Sign up for Advanced Imaging TOC. Get the latest issue of Advanced Imaging delivered right to you!Sign up now
Here, we present a single-photon LiDAR system based on an InGaAs/InP SPAD detector array to capture high-resolution 3D profiles of static and moving targets concealed by double-layer camouflage nets. For static targets, we reported a sub-voxel scanning approach[45,46] combined with a 3D deconvolution algorithm to realize high-resolution imaging. Using this approach, we experimentally demonstrated 3D imaging through camouflage netting with a
2. Static Target: 3D Sub-Voxel Scanning Approach
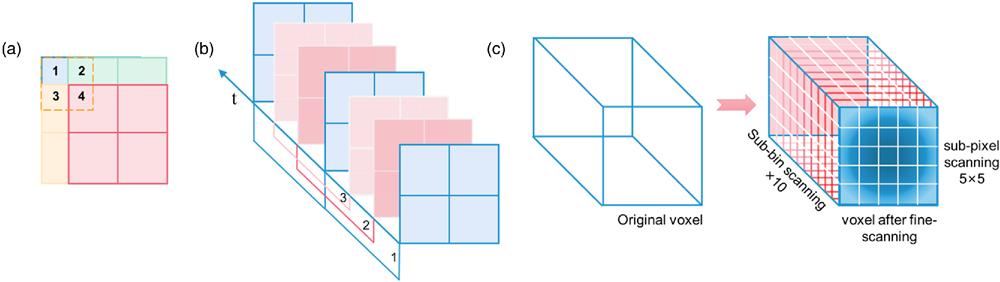
Constrained by factors such as material uniformity, circuit fabrication technology, data transmission, and cost, the format and time resolution of SPAD detector arrays are currently limited, preventing them from achieving high-resolution imaging in multi-depth scenarios. To improve the depth resolution, Rapp et al. introduced subtractive dither to the temporal quantization of TCSPC[47], while Raghuram et al. achieved super-resolving transients by oversampled measurements[48]. Inspired by these works, we proposed the 3D sub-voxel scanning approach and a tailored spatial-temporal photon-efficient deconvolution algorithm (see Fig. 1), which can alleviate the block effect of the foreground clutter and achieve super-resolution image reconstruction with about 1 PPP. The sub-pixel scanning method, initially employed in conventional cameras, captures a series of low-resolution images during the sub-pixel displacement process, which can be reconstructed to obtain a high-resolution image[49]. This method has also been applied in single-photon imaging in recent years[50]. For instance, Li et al. utilized the sub-pixel scanning approach to achieve super-resolution imaging beyond the diffraction limit over long distances[45,46].
![]()
Figure 1.Schematic of the 3D sub-voxel scanning method. (a) An illustration of sub-pixel scanning using the SPAD array with 2 pixel × 2 pixel and an inter-pixel spacing of 1/2 FoV. (b) A scheme of sub-bin scanning in time domain with 3 steps. (c) One original voxel in the measurement matrix can be expanded to
To achieve 3D sub-voxel scanning, we employed a piezo tip/tilt platform with a mirror and an arbitrary function generator (AFG) for sub-pixel scanning in the spatial domain and sub-bin scanning in the temporal domain, respectively. To realize sub-pixel scanning, we set the inter-pixel scanning space smaller than the size of the field of view (FoV) of one pixel. As shown in Fig. 1(a), we illustrate an inter-pixel spacing of 1/2 FoV as an example. The inter-pixel shift was performed in both the
2.1. Spatial-temporal photon-efficient deconvolution algorithm
To cooperate with our 3D sub-voxel scanning approach, we develop a spatial-temporal photon-efficient deconvolutional algorithm to compute the high-resolution image from the sub-voxel scanning data with low signal levels at
In a single-photon LiDAR system, the laser emits pulses to periodically illuminate the target scene in either a raster-scanned manner or a flood-illuminated way. Using the technique of TCSPC, we measure the time-of-flight of each received photon and form a histogram, which can be seen as the measured matrix. Taking the sub-voxel scanning process into consideration, the measured histogram in our experiment is spliced with all the histograms with low resolution in three dimensions according to their relative displacement. The integrated histogram is denoted as
To obtain the estimation of
Here, the constraint
2.2. Numerical simulation
The numerical simulations are provided here to evaluate our sub-voxel scanning scheme. As shown in Fig. 2, we chose a typical scene from the Middlebury dataset of size 370 pixel × 463 pixel as our target scene and simulated the practical low-light conditions by setting the signal-to-background ratio (SBR) ratio to 0.2, and the inter-pixel spacing to 1/5 FoV, which means a
![]()
Figure 2.Numerical simulation of the proposed algorithm. The ground truth is a typical scene from the Middlebury dataset. In our simulation, the SBR is set to 0.2, and the average number of detected signal photons is set to 10, 5, and 1 PPP, respectively. The first column shows the results without fine scanning. The second column shows the results with only 2D sub-pixel scanning and conventional pixel-wise ML processing. The third column shows the results with 3D sub-voxel scanning and pixel-wise ML processing. The last column shows the results with 3D sub-voxel scanning and our photon-efficient 3D deconvolutional algorithm. Quantitative results in terms of the RMSE are shown at the bottom of each figure. Clearly, our 3D sub-voxel method combined with the proposed algorithm has a smaller RMSE and superior performance to exhibit the details of the images.
We conducted simulations using different numbers of detected signal PPP, specifically 10, 5, and 1 PPP. We compared the reconstruction results with four different methods: no scanning, only 2D spatial scanning, 3D sub-voxel scanning using the maximum likelihood (ML) algorithm, and our proposed method. Quantitative results in terms of root mean square error (RMSE) are presented at the bottom of each figure. As Fig. 2 shows, our algorithm outperforms the other methods in terms of imaging quality at 10, 5, and 1 average photon counts and exhibits the smallest RMSE.
3. Experimental Setup
The experimental setup, depicted in Fig. 3, is compactly constructed on an aluminum breadboard and organized in a bistatic optical configuration. On the transmitting end, a pulsed fiber laser operating at 1550 nm is employed as the light source. The laser beam is transmitted through a fiber to provide flood illumination on the target scene. The laser operates at a repetition rate of 25 kHz, delivering an average power of 50 mW and a pulse width of 500 ps. The system exhibits a total jitter of approximately 1 ns. It is important to clarify that our method would have better outcomes when the system jitter is lower than the resolution of the TDC. Limited by the jitter of our laser, the jitter of our system is slightly wider than the TDC resolution. However, compared with the approach of histogram interpolation, our method would still surpass it in results since the interpolated histogram will suffer from severe distortion when the number of sample points is too small here. The utilization of a 1550 nm laser offers the advantage of being eye-safe, ensuring a safe distance for all ranges.
![]()
Figure 3.Schematic diagram of the experimental setup. (a) The schematic diagram of our experimental setup. The complex scenario is hidden behind a double-layer camouflage net, which is imaged by a visible-light camera, a MWIR camera, and our single-photon LiDAR system. (b) The photograph of the hidden scene. (c) The photograph of our experimental setup. (d) The photograph during the experiment with the glass door closed as an obstruction in the imaging path.
At the receiving end, a 64 pixel × 64 pixel InGaAs/InP single-photon detector array is utilized for receiving returned photons parallel. The pixel pitch is 50 µm, and each pixel is equipped with a TDC providing a time resolution of 1 ns, corresponding to a distance resolution of 15 cm. The TDC modules integrated into the array measure the time difference between the start signal and photon events at each pixel. These measurements are then transferred to the computer via a CameraLink cable. The dark count rate of the detector is 2 kilocounts per second, and the width of the detection gate can be adjusted from 0 to 4000 ns. For the receiving optics, a commercially available camera lens (Thorlabs, MVL7000) is employed in the experiment. The chosen focal length is 25 mm, combined with the single-photon detector arrays, resulting in a field of view of 2 mrad per pixel. This field of view corresponds to a resolution of 6 cm at a distance of 30 m, and the overall field of view of the system is 3.8 m. To eliminate solar noise and ensure continuous operation throughout the day, two filters are placed in front of the lens. One filter is a 1300 nm long-pass filter, and the other is a band-pass filter with a center wavelength of 1550.6 nm and a bandwidth of 1.8 nm.
An aluminum-coated mirror affixed to the piezo tip/tilt platform is adopted to achieve 2D sub-pixel scanning of the target. The tip/tilt platform has a scanning range of 10 mrad and achieves a closed-loop accuracy as high as 1 μrad, meeting the requirements for our fine scanning accuracy. Both the laser and SPAD detector arrays operate in external trigger mode, and an AFG is employed in the system to provide a 25 kHz trigger signal for time synchronization. Sub-bin scanning in the temporal domain is achieved by scanning the delay between these two trigger signals.
In the experiment, a visible-light camera and an infrared camera were employed for imaging as a comparison among the three modalities. The visible-light camera (ASI294MC) has a resolution of 4144 pixel × 2822 pixel, with a pixel pitch of 4.63 µm, and is equipped with a lens (Thorlabs, MVL25M23), which has a focal length of 25 mm. The infrared camera utilized is a cooled MWIR camera, which employs HgCdTe as the detector material. It possesses a resolution of 640 pixel ×512 pixel, with a pixel size of 15 µm. During the experiment, the focal length of the infrared camera was set to 80 mm.
The experiment was conducted in an outdoor corridor where two layers of camouflage nets were placed 30 m away from the imaging system to achieve a dense occlusion of objects behind the nets. As shown in Fig. 3, the complex scene behind the net consists of letters, mannequins, sculptures, and other elements. The farthest point in the scene was approximately 2.3 m away from the net. Additionally, to assess the penetration capability of different cameras through complex occlusions, a glass door was also used as an obstruction in the imaging path [shown in Fig. 3(d)].
4. Results for the Static Target
According to our forward model mentioned in Section 2.1, we first calibrated the 3D
![]()
Figure 4.Calibration results of our imaging system. (a) The calibration result of the
After calibrating the system’s IRF, we validated the 3D super-resolution imaging capability of our system by conducting measurements on a self-made 3D resolution chart. The photograph and dimensions of the resolution chart are illustrated in the figure below. We performed
Subsequently, we employed our system to perform measurements of the complex scene behind the camouflage nets under different conditions and compared the imaging results with those captured by the visible-light camera and MWIR camera. During all the experiments, the laser power was set to 50 mW, and the acquisition time for each frame of fine scanning was 10 ms, resulting in a total imaging time of 2.5 s. We first did the experiment in daylight by imaging through the double-layer camouflage nets, and the results of different modalities are illustrated in Fig. 5. The four images stand for the results of the visible-light camera, MWIR camera, single-photon LiDAR without fine scanning, and our proposed method. In Figs. 5(a) and 5(b), most of the details of the scenario behind the nets are missing since these two passive modalities lack the depth information to separate the nets from the camouflaged scenarios. In Fig. 5(d), it can be seen that our method exhibits superior capabilities to achieve high-quality imaging through the camouflage nets. The average photon count per pixel was 2.36 PPP, which demonstrated the photon-efficient capability of our algorithm.
![]()
Figure 5.Experimental results of the static scenario behind the camouflage nets in daylight. The results of the (a) visible-light camera, (b) MWIR camera, (c) single-photon LiDAR without fine scanning, (d) single-photon LiDAR with 3D sub-voxel scanning, and (e) timing histogram of the data in (d).
We further carried out the experiment in daylight with a glass door closed as another obstruction. The results are shown in Fig. 6. Compared with Fig. 5, it shows that the visible-light camera and single-photon LiDAR are almost unaffected while the MWIR camera failed to penetrate the glass, which means that the application of the MWIR camera would be restricted when there are glasses involved in the path. With the same PPP as low as 1.73, the reconstructed result of our method in Fig. 6(d) is much better than the results without fine scanning shown in Fig. 6(c), which demonstrates that our method is efficient for dealing with the obstruction of the camouflage nets.
![]()
Figure 6.Experimental results of the static scenario behind the camouflage nets in daylight with a glass door. The results of the (a) visible-light camera, (b) MWIR camera, (c) single-photon LiDAR without fine scanning, and (d) single-photon LiDAR with 3D sub-voxel scanning. (a) and (b) are applied with contrast enhancement for better visual effects.
In Fig. 7, we show the results of the experiment at night to demonstrate the system’s ability to operate effectively throughout the whole day. It can be seen that the imaging quality of the visible-light camera and the MWIR camera significantly degrades at night, while the reconstructed result of our method is not affected. By comparing the three experiments, we demonstrate 3D imaging for complex scenes in various outdoor scenarios throughout the whole day and evaluate the advanced features of single-photon LiDAR over both the visible-light camera and MWIR camera.
![]()
Figure 7.Experimental results of the static scenario behind the camouflage nets at night. The results of the (a) visible-light camera, (b) MWIR camera, (c) single-photon LiDAR without fine scanning, and (d) single-photon LiDAR with 3D sub-voxel scanning. (a) and (b) are applied with contrast enhancement for better visual effects.
5. Moving Target: Motion Compensation Method
For moving targets, sub-voxel scanning can result in image blurring and distortion due to the object’s movement. If the SPAD detector array with 64 pixel × 64 pixel is directly used for imaging dynamic targets through camouflage nets, each frame will have a portion of the object blocked by the grid, and the limited number of pixels can lead to poor results. However, when the target is in motion, the blocked portion changes with each frame. If it is possible to detect the moving targets (rigid bodies) and their positions in each frame[52], the impact of grid obstruction can be eliminated by using information collected from multiple frames. Moreover, due to the high frame rate requirements for imaging the moving target, the number of signal photons in a single frame is limited, which means that the results are easily affected by noise. The signal-to-noise ratio (SNR) of single-photon LiDAR can be obtained as
5.1. Motion compensation algorithm
For each bin in the pixel, if the threshold
The framework of the motion compensation algorithm is described in Algorithm 1.
| 1: Input: |
| 2: Histogram of current frame |
| 3: Pre-processing step: |
| 4: Denoise with the threshold |
| 5: Estimate |
| 6: Object segmentation: |
| 7: Segment each object in depth and reflectivity map then project to the histogram |
| 8: Motion estimation: |
| 9: Conduct cross-correlation between |
| 10: Image reconstruction: |
| 11: Obtain the histogram after motion compensation |
| 12: Compute |
| 13: Super-resolution step: |
| 14: Compute |
| 15: Output: |
| 16: |
Table 1. Motion compensation algorithm
5.2. Experiments and results
The experimental setup remains consistent, as illustrated in Fig. 3. For moving targets, we employed the motion compensation algorithm, which was discussed in the previous section. The scene behind the camouflage nets included a mannequin moving from right to left, which was positioned approximately 1.5 m away from the net, as well as a person bouncing a basketball at a distance of about 3 m. During the experiment, we collected data over a period of 10 s, which amounted to 250,000 frames for the SPAD detector array. A total of 1250 frames of data were processed to generate a single processed image, resulting in an imaging frame rate of 20 frame/s.
The existence of the double-layer camouflage nets severely limited the number of signal photons in each frame of the image, particularly in regions with low reflectivity where the signal was substantially attenuated. Directly applying the Poisson maximum likelihood estimation algorithm to each frame of image data would result in poor image reconstruction quality. Therefore, we employed the motion compensation algorithm described in the previous section to process the data. Specifically, we first performed a pre-processing step on the current frame and conducted target segmentation of the scene using the processed image and the signal histogram. This allowed us to isolate and extract targets such as the mannequin, body, arms, and ball. Then we calculated the displacement of each target relative to the previous
We extracted four frames from the processed video (please refer to Video 1) for presentation, as depicted in Fig. 8. The first column displays images extracted from the video captured by a visible-light camera, the second column shows images from the MWIR camera, and the third column presents the reconstructed 3D profile acquired from the SPAD array. From the results, we can see that the visible-light camera exhibits poor performance in imaging the human body with low reflectivity, while the MWIR camera performs poorly in capturing the mannequin with low temperatures. However, our approach using single-photon LiDAR achieves high-resolution 3D imaging of all targets behind the net, providing significant advantages compared to the previous two cameras, which verifies the effectiveness of our motion compensation algorithm for single-photon imaging through the camouflage nets.
![]()
Figure 8.Experimental results of the moving scenario behind the camouflage nets. (a) The photographs of the scene behind the camouflage nets taken from the back. (b) The photographs are captured by a MWIR camera. (c) The photographs are captured by a visible-light camera. (d) The reconstructed 3D profile of the multi-layer scenario. The movement of the mannequin and the basketball can be seen in the image sequences. The boxes of different colors indicate the segmented objects in our experiment.
As shown in Fig. 9, we also compared our algorithm with the cross-correlation method and the real-time plug-and-play denoiser[15]. Due to the obstruction of the dense camouflaged nets, many of the pixels contain few photon signals especially in the region with low reflectivity (the legs of the man wearing black pants), which leads to the loss of information in the reconstructed results shown in Figs. 8(a) and 8(b). Our proposed motion compensation algorithm mitigates the net’s obstructive effect using spatio-temporal correlation between frames. The reconstruction result of our algorithm is more complete and continuous, which also captures additional details in the contours of the 3D target.
![]()
Figure 9.Comparison of 3D reconstruction methods for moving targets behind the camouflage nets. The data are the same as the first frame displayed in Fig. 8. Reconstruction results of the (a) cross-correlation, (b) real-time plug-and-play denoiser[
6. Conclusion
This study presents reconstructions of high-resolution 3D profiles for both static and moving targets that are obscured by camouflage nets. For static targets, we developed a sub-voxel scanning approach combined with a photon-efficient 3D deconvolution algorithm, which was demonstrated through numerical and experimental analysis. In our experiments, we achieved a
References
[7] F. Adib, D. Katabi. See through walls with WiFi!, 75(2013).
[8] C. R. Karanam, Y. Mostofi. 3D through-wall imaging with unmanned aerial vehicles using WiFi, 131(2017).
[18] A. Kirmani, D. Venkatraman, D. Shin et al. First-photon imaging. Science, 343, 58(2014).
[28] Z.-P. Li, J.-T. Ye, X. Huang et al. Single-photon imaging over 200 km. Optica, 8, 344(2021).
[33] G. Satat, M. Tancik, R. Raskar. Towards photography through realistic fog, 1(2018).
[47] J. Rapp, R. M. Dawson, V. K. Goyal. Improving lidar depth resolution with dither, 1553(2018).
[48] A. Raghuram, A. Pediredla, S. G. Narasimhan et al. Storm: super-resolving transients by oversampled measurements, 1(2019).
[52] G. M. Martín, A. Halimi, R. K. Henderson et al. High-ambient, super-resolution depth imaging with a spad imager via frame re-alignment(2021).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20