
Xianglei Liu, João Monteiro, Isabela Albuquerque, Yingming Lai, Cheng Jiang, Shian Zhang, Tiago H. Falk, Jinyang Liang. Single-shot real-time compressed ultrahigh-speed imaging enabled by a snapshot-to-video autoencoder[J]. Photonics Research, 2021, 9(12): 2464
- Photonics Research
- Vol. 9, Issue 12, 2464 (2021)
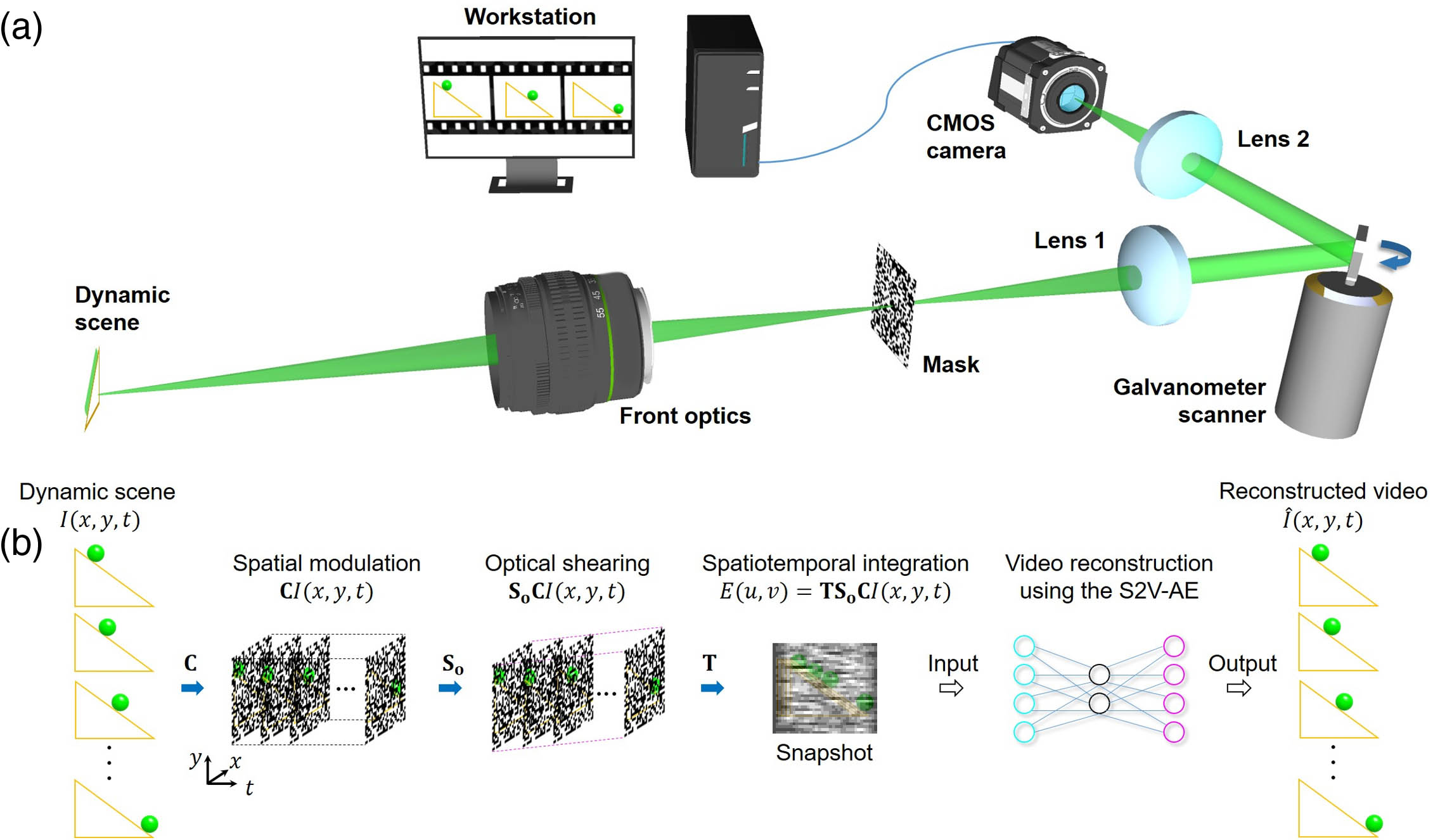
Fig. 1. Single-shot machine-learning assisted real-time (SMART) compressed optical-streaking ultrahigh-speed photography (COSUP). (a) System schematic. (b) Operating principle. S2V-AE, snapshot-to-video autoencoder.
![Snapshot-to-video autoencoder (S2V-AE). (a) General architecture. FI, frame index. (b) Architecture of encoder showing the generation of latent vectors from a compressively recorded snapshot. Bi-LSTM, bidirectional long short-term memory; BN, batch normalization; ReLU, rectified linear unit; W, H, and N, output dimensions; Win, Hin, and Nin, input dimensions. (c) Architecture of the generator showing the reconstruction of a single frame from one latent vector. (d) Generative adversarial networks (GANs) with multiple discriminators {Dk}. LDk, the loss function of each discriminator; LG, the loss function of the generator; and {pk}, random projection with a kernel size of [8,8] and a stride of [2,2]. (e) Architecture of each discriminator.](/richHtml/prj/2021/9/12/12002464/img_002.jpg)
Fig. 2. Snapshot-to-video autoencoder (S2V-AE). (a) General architecture. FI, frame index. (b) Architecture of encoder showing the generation of latent vectors from a compressively recorded snapshot. Bi-LSTM, bidirectional long short-term memory; BN, batch normalization; ReLU, rectified linear unit; W H N W in H in N in { D k } L D k L G { p k }
Fig. 3. Simulation of video reconstruction using the S2V-AE. (a) Six representative frames of the ground truth (GT, top row) and the reconstructed result (bottom row) of the handwritten digit “3.” The snapshot is shown in the far right column. (b), (c) As (a), but showing handwritten digits 5 and 7. (d), (e) Peak SNR and the structural similarity index measure (SSIM) of each reconstructed frame for the three handwritten digits.
Fig. 4. SMART-COSUP of animation of bouncing balls at 5 kfps. (a) Experimental setup. DMD, digital micromirror device. Inset: an experimentally acquired snapshot. (b) Five representative frames with 4 ms intervals in the ground truth (GT) and the videos reconstructed by TwIST, PnP-ADMM, and S2V-AE, respectively. Centroids of the three balls are used as vertices to build a triangle (delineated by cyan dashed lines), whose geometric center is marked with a green asterisk. (c), (d) PSNR and SSIM at each reconstructed frame. (e) Comparison of the positions of the geometric center between the GT and the reconstructed results in the x y
Fig. 5. SMART-COSUP of multiple-particle tracking at 20 kfps. (a) Experimental setup. (b) Static image of three microspheres (labeled as M 1 − M 3 r M 1 r M 3
| |||||||||||||||||||||||||||||||||||||||
Table 1. Standard Deviations of Reconstructed Centroids of Each Ball Averaged over Time (Unit: μm)

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20