
Xianglei Liu, João Monteiro, Isabela Albuquerque, Yingming Lai, Cheng Jiang, Shian Zhang, Tiago H. Falk, Jinyang Liang, "Single-shot real-time compressed ultrahigh-speed imaging enabled by a snapshot-to-video autoencoder," Photonics Res. 9, 2464 (2021)
- Photonics Research
- Vol. 9, Issue 12, 2464 (2021)
Abstract
1. INTRODUCTION
2D optical visualization of transient phenomena in the actual time of the event’s occurrence plays a vital role in the understanding of many mechanisms in biology, physics, and chemistry [1–3]. To discern spatiotemporal details in these phenomena, high-speed optical imagers are indispensable. Imaging speeds of these systems, usually determined by the frame rates of deployed CCD or CMOS cameras, can be further increased using novel sensor designs [4–6], new readout interfaces [7,8], and advanced computational imaging methods [9–11].
Among existing approaches, compressed ultrafast photography (CUP) [12–20] is an innovative coded-aperture imaging scheme [21,22] that integrates video compressed sensing [23] into streak imaging [24]. In data acquisition, a spatiotemporal
Despite these hardware innovations, COSUP’s video reconstruction has ample room for improvement. Existing reconstruction frameworks can be generally grouped into analytical-modeling-based methods and machine-learning-based methods [30]. Using the prior knowledge of the sensing matrix and the sparsity in the transient scene, the analytical-modeling-based methods reconstruct videos by solving an optimization problem that synthetically considers the image fidelity and the sparsity-promoted regularization. However, demonstrated methods, such as the two-step iterative shrinkage/thresholding (TwIST) algorithm [31], augmented Lagrangian algorithm [32], and an alternating direction method of a multiplier (ADMM) algorithm [29], undergo time-consuming processing that uses tens to hundreds of iterations. The excessively long reconstruction time strains these analytical-modeling-based methods from real-time (i.e.,
Sign up for Photonics Research TOC. Get the latest issue of Photonics Research delivered right to you!Sign up now
To solve these problems, machine learning has become an increasingly popular choice. Instead of relying solely on prior knowledge, large amounts of training data are used for deep neural networks (DNNs) [35] to learn how to map an acquired snapshot back to a video. Upon the completion of training, DNNs can then execute non-iterative high-quality reconstruction during runtime. Thus far, DNNs that employ the architectures of the multilayer perceptrons (MLPs) [36,37] and the U-net [38–41] have shown promise for compressed video reconstruction. Nonetheless, MLPs, with fully connected structures, scale linearly with the dimensionality of input data [42]. Besides, the decomposition in the reconstruction process presumes that all information in the output video block is contained in a patch of the input image, which cannot always be satisfied [36,37]. As for the U-net, the reconstruction often starts with a pseudo-inverse operation to the input snapshot to accommodate the equality in dimensionality required by the original form of this network [43]. This initial step increases the reconstruction burden in computational time and memory. Moreover, akin to MPLs, U-net-based methods require slicing input data for reconstruction, which could cause the loss of spatial coherence [39]. Finally, inherent temporal coherence across video frames is often unconsidered in the U-net [44]. Because of these intrinsic limitations, videos reconstructed by the U-nets are often subject to spatiotemporal artifacts and a shallow sequence depth (i.e., the number of frames in the reconstructed video) [41].
Here, we propose a way to overcome these limitations using an autoencoder (AE), whose objective is to learn a mapping from high-dimensional input data to a lower-dimensional representation space, from which the original data is recovered [45]. The implementation of convolutional layers in AE’s architecture provides a parameter-sharing scheme that is more efficient than MLPs. Besides, without relying on locality presumptions, deep AEs with convolutional layers can preserve the intrinsic coherence in information content. Furthermore, recent advances in combining AE with adversarial formulations [46] have allowed replacing the loss functions based on pixel-wise error calculation to settings where perceptual features are accounted for, which have enabled a more accurate capture of data distribution and increased visual fidelity [47]. In the particular case of training generative models [e.g., generative adversarial networks (GANs)] for natural scenes, recent advances have improved the reconstructed imaging quality by dividing the overall task into sub-problems, such as independent modeling of the foreground and background [48], separated learning of motion and frame content [49], and conditioning generation on optical flows [50]. Despite these advances, with popular applications in audio signal enhancement [51] and pattern recognition [52], AEs have been mainly applied to 1D and 2D reconstruction problems [53,54]. Thus, existing architectures of AEs cannot be readily implemented for video reconstruction in compressed ultrahigh-speed imaging.
To surmount these problems, we have developed a snapshot-to-video autoencoder (S2V-AE)—a new DNN that directly maps a compressively recorded 2D
2. PRINCIPLE OF SMART-COSUP
The schematic of the SMART-COSUP system is shown in Fig. 1(a). Its operating principle contains single-shot data acquisition and real-time video reconstruction [Fig. 1(b)]. A dynamic scene,
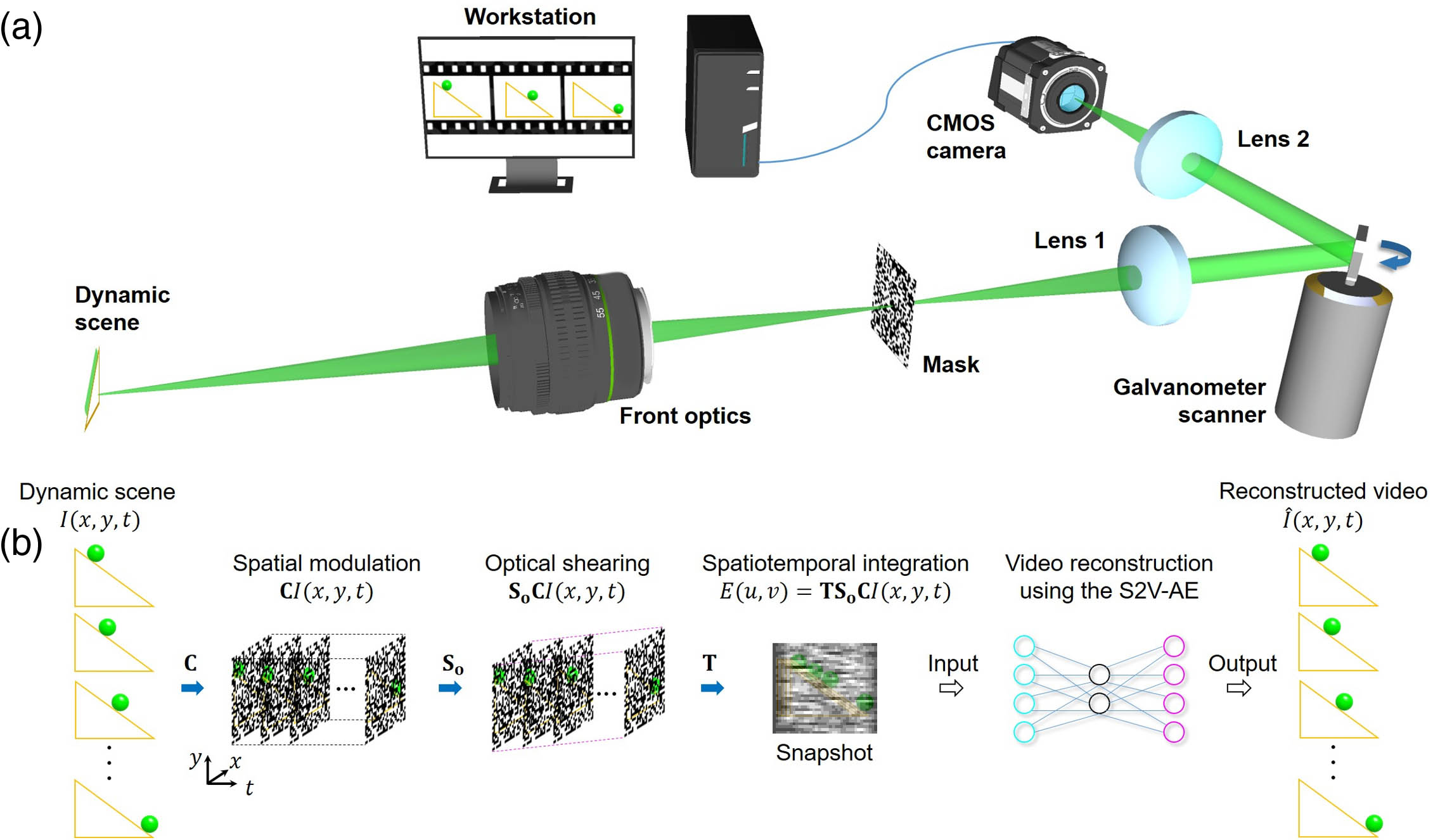
Figure 1.Single-shot machine-learning assisted real-time (SMART) compressed optical-streaking ultrahigh-speed photography (COSUP). (a) System schematic. (b) Operating principle. S2V-AE, snapshot-to-video autoencoder.
Here,
Subsequently, the spatially modulated scene is relayed by a
Finally, the dynamic scene is spatiotemporally integrated by a CMOS camera (GS3-U3-23S6M-C, Teledyne FLIR LLC, Wilsonville, OR, USA) to a 2D snapshot, denoted by the operator
Here,
In the ensuing real-time video reconstruction, the captured data is transferred to a workstation equipped with a graphic processing unit (RTX Titan, NVIDIA, Santa Clara, CA, USA). The S2V-AE retrieves the datacube of the dynamic scene in 60 ms. The frame rate of the SMART-COSUP system is derived from
In this work, the reconstructed video has a frame rate of up to
Compared to the previous hardware configuration [25], SMART-COSUP replaces the digital micromirror device (DMD), which functions as a 2D programmable blazed grating [55], with the transmissive mask for spatial modulation. This arrangement avoids generating a large number of unused diffraction orders, preventing a limited modulation efficiency to unblazed wavelengths, and eliminating intensity loss from the reflection from its cover glass as well as by its interpixel gap. In addition, the printed mask is illuminated at normal incidence, making it fully conjugated with both the object and the camera. Thus, the SMART-COSUP system presents a simpler, economical, and compact design with improved light throughput of the system and image quality of the captured snapshot.
3. STRUCTURE OF S2V-AE
The architecture of S2V-AE consists of an encoder and a generator [Fig. 2(a)]. The encoder (denoted as
![]()
Figure 2.Snapshot-to-video autoencoder (S2V-AE). (a) General architecture. FI, frame index. (b) Architecture of encoder showing the generation of latent vectors from a compressively recorded snapshot. Bi-LSTM, bidirectional long short-term memory; BN, batch normalization; ReLU, rectified linear unit;
The training of the encoder and the generator in the S2V-AE is executed sequentially. Training data are generated on the fly. The details of the training data collection and the training procedure are described in our open source code (see the link in Disclosure). Additional data, not included in its training phase, are used for evaluation. The generator is first trained under the setting of a GAN with multiple discriminators to ensure sufficient diversity. In brief, a random noise vector
Here,
As the second step, the encoder is trained with the parameters of the generator fixed. The mean square error (MSE) between the recovered video
By minimizing
In the training of both the generator and the encoder, the Adam optimization algorithm [61] was employed with a fixed learning rate, set to
4. VALIDATION OF S2V-AE’s RECONSTRUCTION
To test the feasibility of S2V-AE, we simulated video reconstruction of flying handwritten digits [62]. Each dynamic scene had a size of
![]()
Figure 3.Simulation of video reconstruction using the S2V-AE. (a) Six representative frames of the ground truth (GT, top row) and the reconstructed result (bottom row) of the handwritten digit “3.” The snapshot is shown in the far right column. (b), (c) As (a), but showing handwritten digits 5 and 7. (d), (e) Peak SNR and the structural similarity index measure (SSIM) of each reconstructed frame for the three handwritten digits.
Furthermore, to show that the S2V-AE possesses a more powerful ability in high-quality video reconstruction, we compared its performance to U-net, which is most popularly used in video compressed sensing [38]. In particular, this U-net featured a convolutional encoder–decoder architecture with residual connection and used the same loss function in Ref. [38]. To implement the optimal specifications of this U-net based technique, we used an approximate inverse operator
5. DEMONSTRATION OF SMART-COSUP
The proof-of-concept experiments of SMART-COSUP were conducted by imaging an animation of three bouncing balls, whose starting positions and moving directions were randomly chosen (see
![]()
Figure 4.SMART-COSUP of animation of bouncing balls at 5 kfps. (a) Experimental setup. DMD, digital micromirror device. Inset: an experimentally acquired snapshot. (b) Five representative frames with 4 ms intervals in the ground truth (GT) and the videos reconstructed by TwIST, PnP-ADMM, and S2V-AE, respectively. Centroids of the three balls are used as vertices to build a triangle (delineated by cyan dashed lines), whose geometric center is marked with a green asterisk. (c), (d) PSNR and SSIM at each reconstructed frame. (e) Comparison of the positions of the geometric center between the GT and the reconstructed results in the
Furthermore, the three centroids in each frame were used as vertices to build a triangle. Figures 4(e) and 4(f) show the time histories of the geometric center of this triangle generated from the results of the three reconstruction methods. The standard deviations in the
6. APPLICATION OF SMART-COSUP TO MULTIPLE-PARTICLE TRACKING
To show the broad utility of SMART-COSUP, we applied it to tracking multiple fast-moving particles. In the setup, white microspheres were scattered on a surface that rotated at 6800 revolutions per minute [Fig. 5(a)]. The 640 nm continuous-wave laser was used to illuminate the rotating microspheres at an incident angle of
![]()
Figure 5.SMART-COSUP of multiple-particle tracking at 20 kfps. (a) Experimental setup. (b) Static image of three microspheres (labeled as
To quantitatively analyze these images, we calculated the time histories of
Here,
Based on the above analysis, we used single sinusoidal functions to fit the measured velocities. The fitted maximum velocities in the
7. DISCUSSION AND CONCLUSIONS
The S2V-AE offers a new real-time reconstruction paradigm to compressed ultrahigh-speed imaging, as shown in Fig. 2(a). The new architecture of the encoder allows mapping a compressively recorded snapshot into a set of low-dimensional latent vectors. After that, the GAN-trained generator maps such latent vectors into frames of the reconstructed video. Using this scheme, the training procedure is divided into two distinct phases: to train a generative model of static frames and to train an encoding model aiming to sample from the generator. By doing so, unlike direct reconstruction approaches, high quality in frame-wise reconstruction can be ensured by the initially trained generator, while the encoding model needs to learn only how to query coherently across time. This scheme brings in benefits to the reconstructed videos in terms of both quality and flexibility. The encoder in S2V-AE preserves coherence in both space and time. Different from previous works [36,37,39], no artificial segmentation is conducted in the S2V-AE, which avoids generating artifacts due to the loss of spatial coherence. The S2V-AE also explicitly models temporal coherence across frames with the Bi-LSTM. Both innovations ensure artifact-free and high-contrast video reconstruction of sophisticated moving trajectories. Meanwhile, the S2V-AE presents a flexible structure with a higher tolerance for input data. In particular, the generator, used in a PnP setting [66], is independent of the system’s data acquisition, which is important for adaptive compressed sensing applications.
The multiple-discriminator framework implemented in the S2V-AE improves training diversity. While able to generate high-quality, natural-looking samples, generators trained under the framework of the GAN have known drawbacks that have to be accounted for at training time. Namely, mode collapse refers to cases where trained generators can generate only a small fraction of the data support [67]. Standard GAN settings do not account for the diversity of the generated data, but instead, the generator is usually rewarded if its outputs are individually close to the real data instances. As such, a large body of recent literature has tackled the mode collapse using different approaches to improve the diversity of the GAN generators [67,68]. Mode collapse is especially critical in the application we consider here. The generator in the S2V-AE must be able to generate any possible frame, which means being able to output images containing any objects (e.g., balls or digits) in any position. To ensure that the generator is sufficiently diverse, the S2V-AE implements the multiple-discriminator framework [69,70]. Moreover, each such discriminator is augmented with a random projection layer at its input. More random views of the data distribution aid the generator in producing results that are approximate to the real data distribution.
The S2V-AE enables the development of SMART-COSUP. This new technique has demonstrated the largest sequence depth (i.e., 100 frames) in existing DNNs-based compressed ultrahigh-speed imaging methods [36–41]. The sequence depth, as a tunable parameter, could certainly exceed 100 frames. In this aspect, the performance of the S2V-AE mainly depends on the encoder [Fig. 2(b)] since it needs to extract the same number of latent vectors as the sequence depth. Although a large sequence depth may bring in training instabilities due to vanishing/exploding gradients, our choice of the Bi-LSTM architecture in the S2V-AE could alleviate gradient-conditioning issues relative to standard recurrent neural networks [71]. Thus, we expect the limit of sequence depth to be up to 1000 frames in the current setup. Moreover, although we only experimentally demonstrated the 20 kfps imaging speed in this work, the S2V-AE could be extended to reconstruct videos with much higher imaging speeds. As shown in Eq. (5), SMART-COSUP’s imaging speed is determined completely by the hardware. Regardless of the imaging speed, the operation of the S2V-AE—reconstruction of a 3D datacube from a 2D snapshot—remains the same. Moreover, considering the link between imaging speeds and SNRs, the successful reconstruction of snapshots with different SNRs during the training procedure, as discussed in Section 5, indicates S2V-AE’s applicability to reconstruct videos with a wide range of imaging speeds. Furthermore, SMART-COSUP replaces the DMD with a printed transmissive mask. Despite being inflexible, the implemented pseudo-random binary pattern has better compatibility with diverse dynamic scenes, improves light throughput and image quality, as well as offers a simpler, more compact system arrangement. Along with its real-time image reconstruction, the SMART-COSUP system is advancing toward real-world applications.
In summary, we have developed the S2V-AE for fast, high-quality video reconstruction from a single compressively acquired snapshot. This new DNN has facilitated the development of the SMART-COSUP system, which has demonstrated single-shot ultrahigh-speed imaging of transient events in both macroscopic and microscopic imaging at up to 20 kfps with a real-time reconstructed video size of
Acknowledgment
Acknowledgment. The authors thank Patrick Kilcullen for experimental assistance.
References
[1] M. Kannan, G. Vasan, C. Huang, S. Haziza, J. Z. Li, H. Inan, M. J. Schnitzer, V. A. Pieribone. Fast,
[2] M. Sasaki, A. Matsunaka, T. Inoue, K. Nishio, Y. Awatsuji. Motion-picture recording of ultrafast behavior of polarized light incident at Brewster’s angle. Sci. Rep., 10, 7638(2020).
[3] P. R. Poulin, K. A. Nelson. Irreversible organic crystalline chemistry monitored in real time. Science, 313, 1756-1760(2006).
[4] K. Toru, T. Yoshiaki, K. Kenji, T. Mitsuhiro, T. Naohiro, K. Hideki, S. Shunsuke, A. Jun, S. Haruhisa, G. Yuichi, M. Seisuke, T. Yoshitaka. A 3D stacked CMOS image sensor with 16 Mpixel global-shutter mode and 2 Mpixel 10000 fps mode using 4 million interconnections. IEEE Symposium on VLSI Circuits, C90-C91(2015).
[5] T. Etoh, V. Dao, K. Shimonomura, E. Charbon, C. Zhang, Y. Kamakura, T. Matsuoka. Toward 1Gfps: evolution of ultra-high-speed image sensors-ISIS, BSI, multi-collection gates, and 3D-stacking. IEEE IEDM, 11-14(2014).
[6] T. York, S. B. Powell, S. Gao, L. Kahan, T. Charanya, D. Saha, N. Roberts, T. Cronin, N. Marshall, S. Achilefu, S. Lake, B. Raman, V. Gruev. Bioinspired polarization imaging sensors: from circuits and optics to signal processing algorithms and biomedical applications. Proc. IEEE, 102, 1450-1469(2014).
[7] D. Calvet. A new interface technique for the acquisition of multiple multi-channel high speed ADCs. IEEE Trans. Nucl. Sci., 55, 2592-2597(2008).
[8] M. Hejtmánek, G. Neue, P. Voleš. Software interface for high-speed readout of particle detectors based on the CoaXPress communication standard. J. Instrum., 10, C06011(2015).
[9] G. Barbastathis, A. Ozcan, G. Situ. On the use of deep learning for computational imaging. Optica, 6, 921-943(2019).
[10] A. Ehn, J. Bood, Z. Li, E. Berrocal, M. Aldén, E. Kristensson. FRAME: femtosecond videography for atomic and molecular dynamics. Light Sci. Appl., 6, e17045(2017).
[11] Z. Li, R. Zgadzaj, X. Wang, Y.-Y. Chang, M. C. Downer. Single-shot tomographic movies of evolving light-velocity objects. Nat. Commun., 5, 3085(2014).
[12] D. Qi, S. Zhang, C. Yang, Y. He, F. Cao, J. Yao, P. Ding, L. Gao, T. Jia, J. Liang, Z. Sun, L. V. Wang. Single-shot compressed ultrafast photography: a review. Adv. Photon., 2, 014003(2020).
[13] P. Wang, J. Liang, L. V. Wang. Single-shot ultrafast imaging attaining 70 trillion frames per second. Nat. Commun., 11, 2091(2020).
[14] J. Liang, L. Zhu, L. V. Wang. Single-shot real-time femtosecond imaging of temporal focusing. Light Sci. Appl., 7, 42(2018).
[15] Y. Lai, Y. Xue, C. Y. Côté, X. Liu, A. Laramée, N. Jaouen, F. Légaré, L. Tian, J. Liang. Single-shot ultraviolet compressed ultrafast photography. Laser Photon. Rev., 14, 2000122(2020).
[16] J. Liang, P. Wang, L. Zhu, L. V. Wang. Single-shot stereo-polarimetric compressed ultrafast photography for light-speed observation of high-dimensional optical transients with picosecond resolution. Nat. Commun., 11, 5252(2020).
[17] C. Yang, F. Cao, D. Qi, Y. He, P. Ding, J. Yao, T. Jia, Z. Sun, S. Zhang. Hyperspectrally compressed ultrafast photography. Phys. Rev. Lett., 124, 023902(2020).
[18] J. Liang, C. Ma, L. Zhu, Y. Chen, L. Gao, L. V. Wang. Single-shot real-time video recording of a photonic Mach cone induced by a scattered light pulse. Sci. Adv., 3, e1601814(2017).
[19] X. Liu, S. Zhang, A. Yurtsever, J. Liang. Single-shot real-time sub-nanosecond electron imaging aided by compressed sensing: analytical modeling and simulation. Micron, 117, 47-54(2019).
[20] L. Gao, J. Liang, C. Li, L. V. Wang. Single-shot compressed ultrafast photography at one hundred billion frames per second. Nature, 516, 74-77(2014).
[21] J. Liang, L. V. Wang. Single-shot ultrafast optical imaging. Optica, 5, 1113-1127(2018).
[22] J. Liang. Punching holes in light: recent progress in single-shot coded-aperture optical imaging. Rep. Prog. Phys., 83, 116101(2020).
[23] J. Yang, X. Yuan, X. Liao, P. Llull, D. J. Brady, G. Sapiro, L. Carin. Video compressive sensing using Gaussian mixture models. IEEE Trans. Image Process., 23, 4863-4878(2014).
[24] C. Wang, Z. Cheng, W. Gan, M. Cui. Line scanning mechanical streak camera for phosphorescence lifetime imaging. Opt. Express, 28, 26717-26723(2020).
[25] X. Liu, J. Liu, C. Jiang, F. Vetrone, J. Liang. Single-shot compressed optical-streaking ultra-high-speed photography. Opt. Lett., 44, 1387-1390(2019).
[26] P. Llull, X. Liao, X. Yuan, J. Yang, D. Kittle, L. Carin, G. Sapiro, D. J. Brady. Coded aperture compressive temporal imaging. Opt. Express, 21, 10526-10545(2013).
[27] R. Koller, L. Schmid, N. Matsuda, T. Niederberger, L. Spinoulas, O. Cossairt, G. Schuster, A. K. Katsaggelos. High spatio-temporal resolution video with compressed sensing. Opt. Express, 23, 15992-16007(2015).
[28] D. Reddy, A. Veeraraghavan, R. Chellappa. P2C2: programmable pixel compressive camera for high speed imaging. IEEE CVPR, 329-336(2011).
[29] Y. Liu, X. Yuan, J. Suo, D. J. Brady, Q. Dai. Rank minimization for snapshot compressive imaging. IEEE Trans. Pattern Anal. Mach. Intell., 41, 2990-3006(2018).
[30] A. Lucas, M. Iliadis, R. Molina, A. K. Katsaggelos. Using deep neural networks for inverse problems in imaging beyond analytical methods. IEEE Signal Process. Mag., 35, 20-36(2018).
[31] J. M. Bioucas-Dias, M. A. Figueiredo. A new TwIST: two-step iterative shrinkage/thresholding algorithms for image restoration. IEEE Trans. Image Process., 16, 2992-3004(2007).
[32] C. Yang, D. Qi, F. Cao, Y. He, X. Wang, W. Wen, J. Tian, T. Jia, Z. Sun, S. Zhang. Improving the image reconstruction quality of compressed ultrafast photography via an augmented Lagrangian algorithm. J. Opt., 21, 035703(2019).
[33] J. Hui, Y. Cao, Y. Zhang, A. Kole, P. Wang, G. Yu, G. Eakins, M. Sturek, W. Chen, J.-X. Cheng. Real-time intravascular photoacoustic-ultrasound imaging of lipid-laden plaque in human coronary artery at 16 frames per second. Sci. Rep., 7, 1417(2017).
[34] M. Kreizer, D. Ratner, A. Liberzon. Real-time image processing for particle tracking velocimetry. Exp. Fluids, 48, 105-110(2010).
[35] Y. LeCun, Y. Bengio, G. Hinton. Deep learning. Nature, 521, 436-444(2015).
[36] M. Iliadis, L. Spinoulas, A. K. Katsaggelos. Deep fully-connected networks for video compressive sensing. Digit. Signal Process., 72, 9-18(2018).
[37] M. Yoshida, A. Torii, M. Okutomi, K. Endo, Y. Sugiyama, R.-I. Taniguchi, H. Nagahara. Joint optimization for compressive video sensing and reconstruction under hardware constraints. Proceedings of the European Conference on Computer Vision (ECCV), 634-649(2018).
[38] M. Qiao, Z. Meng, J. Ma, X. Yuan. Deep learning for video compressive sensing. APL Photon., 5, 030801(2020).
[39] Y. Ma, X. Feng, L. Gao. Deep-learning-based image reconstruction for compressed ultrafast photography. Opt. Lett., 45, 4400-4403(2020).
[40] C. Yang, Y. Yao, C. Jin, D. Qi, F. Cao, Y. He, J. Yao, P. Ding, L. Gao, T. Jia. High-fidelity image reconstruction for compressed ultrafast photography via an augmented-Lagrangian and deep-learning hybrid algorithm. Photon. Res., 9, B30-B37(2021).
[41] A. Zhang, J. Wu, J. Suo, L. Fang, H. Qiao, D. D.-U. Li, S. Zhang, J. Fan, D. Qi, Q. Dai. Single-shot compressed ultrafast photography based on U-net network. Opt. Express, 28, 39299-39310(2020).
[42] M. W. Gardner, S. Dorling. Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences. Atmos. Environ., 32, 2627-2636(1998).
[43] O. Ronneberger, P. Fischer, T. Brox. U-net: Convolutional Networks for Biomedical Image Segmentation, 234-241(2015).
[44] Z. Cheng, R. Lu, Z. Wang, H. Zhang, B. Chen, Z. Meng, X. Yuan. BIRNAT: bidirectional recurrent neural networks with adversarial training for video snapshot compressive imaging. ECCV, 258-275(2020).
[45] M. Tschannen, O. Bachem, M. Lucic. Recent advances in autoencoder-based representation learning(2018).
[46] A. Nguyen, J. Clune, Y. Bengio, A. Dosovitskiy, J. Yosinski. Plug & play generative networks: conditional iterative generation of images in latent space. IEEE CVPR, 4467-4477(2017).
[47] A. B. L. Larsen, S. K. Sønderby, H. Larochelle, O. Winther. Autoencoding beyond pixels using a learned similarity metric. PMLR International Conference on Machine Learning, 1558-1566(2016).
[48] C. Vondrick, H. Pirsiavash, A. Torralba. Generating videos with scene dynamics. Adv. Neural Inf. Process Syst., 29, 613-621(2016).
[49] S. Tulyakov, M.-Y. Liu, X. Yang, J. Kautz. Mocogan: decomposing motion and content for video generation. IEEE CVPR, 1526-1535(2018).
[50] K. Ohnishi, S. Yamamoto, Y. Ushiku, T. Harada. Hierarchical video generation from orthogonal information: optical flow and texture(2017).
[51] O. Plchot, L. Burget, H. Aronowitz, P. Matejka. Audio enhancing with DNN autoencoder for speaker recognition. IEEE ICASSP, 5090-5094(2016).
[52] J. Yu, X. Zheng, S. Wang. A deep autoencoder feature learning method for process pattern recognition. J. Process Control, 79, 1-15(2019).
[53] M. A. Ranzato, C. Poultney, S. Chopra, Y. L. Cun. Efficient learning of sparse representations with an energy-based model. Advances in Neural Information Processing Systems, 1137-1144(2007).
[54] P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, P.-A. Manzagol, L. Bottou. Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res., 11, 3371-3408(2010).
[55] J. Liang, M. F. Becker, R. N. Kohn, D. J. Heinzen. Homogeneous one-dimensional optical lattice generation using a digital micromirror device-based high-precision beam shaper. J. Micro/Nanolithogr. MEMS MOEMS, 11, 023002(2012).
[56] X. Ma, E. Hovy. End-to-end sequence labeling via bi-directional LSTM-CNNS-CRF(2016).
[57] S. Ioffe, C. Szegedy. Batch normalization: accelerating deep network training by reducing internal covariate shift. Proceedings of the 32nd International Conference on Machine Learning, 448-456(2015).
[58] V. Nair, G. E. Hinton. Rectified linear units improve restricted boltzmann machines. Proceedings of the 27th International Conference on Machine Learning, 807-814(2010).
[59] Z. Zhang, M. Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. Advances in Neural Information Processing Systems, 8778-8788(2018).
[60] A. Krogh, J. A. Hertz. A simple weight decay can improve generalization. Advances in Neural Information Processing Systems, 950-957(1992).
[61] D. P. Kingma, J. Ba. Adam: a method for stochastic optimization(2014).
[62] L. Deng. The MNIST database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag., 29, 141-142(2012).
[63] Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process., 13, 600-612(2004).
[64] . Register images using registration estimator app.
[65] C. Jiang, P. Kilcullen, Y. Lai, T. Ozaki, J. Liang. High-speed dual-view band-limited illumination profilometry using temporally interlaced acquisition. Photon. Res., 8, 1808-1817(2020).
[66] X. Yuan, Y. Liu, J. Suo, Q. Dai. Plug-and-play algorithms for large-scale snapshot compressive imaging. CVPR, 1447-1457(2020).
[67] Z. Lin, A. Khetan, G. Fanti, S. Oh. PACGAN: the power of two samples in generative adversarial networks. Advances in Neural Information Processing Systems, 1498-1507(2018).
[68] A. Jolicoeur-Martineau. The relativistic discriminator: a key element missing from standard GAN(2018).
[69] B. Neyshabur, S. Bhojanapalli, A. Chakrabarti. Stabilizing GAN training with multiple random projections(2017).
[70] I. Albuquerque, J. Monteiro, T. Doan, B. Considine, T. Falk, I. Mitliagkas. Multi-objective training of generative adversarial networks with multiple discriminators. Proceedings of the 36th International Conference on Machine Learning, 202-211(2019).
[71] P. Razvan, T. Mikolov, Y. Bengio. On the difficulty of training recurrent neural networks. Proceedings of the 30th International Conference on Machine Learning, 1310-1318(2013).
[72] P. Ding, Y. Yao, D. Qi, C. Yang, F. Cao, Y. He, J. Yao, C. Jin, Z. Huang, L. Deng, L. Deng, T. Jia, J. Liang, Z. Sun, S. Zhang. Single-shot spectral-volumetric compressed ultrafast photography. Adv. Photon., 3, 045001(2021).
[73] Z. Meng, X. Yuan. Perception inspired deep neural networks for spectral snapshot compressive imaging. ICIP, 2813-2817(2021).
[74] Y. Pu, Z. Gan, R. Henao, X. Yuan, C. Li, A. Stevens, L. Carin. Variational autoencoder for deep learning of images, labels and captions. Advances in Neural Information Processing Systems, 2352-2360(2016).
[75] A. Ten Cate, C. H. Nieuwstad, J. J. Derksen, H. E. A. Van den Akker. Particle imaging velocimetry experiments and lattice-Boltzmann simulations on a single sphere settling under gravity. Phys. Fluids, 14, 4012-4025(2002).
[76] N. Nitta, T. Sugimura, A. Isozaki, H. Mikami, K. Hiraki, S. Sakuma, T. Iino, F. Arai, T. Endo, Y. Fujiwaki, H. Fukuzawa, M. Hase, T. Hayakawa, K. Hiramatsu, Y. Hoshino, M. Inaba, T. Ito, H. Karakawa, Y. Kasai, K. Koizumi, S. Lee, C. Lei, M. Li, T. Maeno, S. Matsusaka, D. Murakami, A. Nakagawa, Y. Oguchi, M. Oikawa, T. Ota, K. Shiba, H. Shintaku, Y. Shirasaki, K. Suga, Y. Suzuki, N. Suzuki, Y. Tanaka, H. Tezuka, C. Toyokawa, Y. Yalikun, M. Yamada, M. Yamagishi, T. Yamano, A. Yasumoto, Y. Yatomi, M. Yazawa, D. Di Carlo, Y. Hosokawa, S. Uemura, Y. Ozeki, K. Goda. Intelligent image-activated cell sorting. Cell, 175, 266-276(2018).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20