
Ruiqi Luo, Xiaolei Chen, Yajun Ha. A routing algorithm for FPGAs with time-multiplexed interconnects[J]. Journal of Semiconductors, 2020, 41(2): 022405
- Journal of Semiconductors
- Vol. 41, Issue 2, 022405 (2020)
Abstract
1. Introduction
Interconnect and logic resources can be seen as the two significant parts of FPGAs. Logic blocks are used to implement a user design. Interconnect resources are designed to achieve connections among logic blocks. In FPGAs, logic resources are always organized as arrays of blocks. Interconnect resources are routing switches and wires grouped into channels. FPGA interconnects (or interconnection network) can be thought of as a programmable network of signal paths among FPGA logic resource ports.
Both measurements and analyses indicate that the programmable interconnections contribute the most to the FPGA area, latency, and power consumption. In order to achieve high routability with reduced routing, FPGA vendors use the substantial on-chip area to route programmable switches and wires[
Previous work by Trimberger et al.[
FPGAs with time-multiplexed interconnects require specialized electric design automation (EDA) algorithms and tools to support them. Existing algorithms and tools cannot be reused in their present forms because they are not multiplexing-aware. In this paper, we propose a time-multiplexing-aware routing algorithm. This algorithm is similar to VPR routing algorithm[
We also validate our proposed routing algorithm experimentally. We evaluate our TM-ARCH FPGAs by using our TM-router to replace the conventional VPR router in a standard FPGA EDA flow. We also use the VPR 5 router[
The rest of this paper is as follows. Section 2 introduces existing FPGA architectures and their EDA algorithms. Section 3 briefly introduces TM-ARCH architecture. Section 4 proposes our time-multiplexing-aware routing algorithm. Section 5 introduces what we have done to validate this algorithm, and also presents experimental results. Finally, Section 6 concludes this paper.
2. Related work
Previous work on time-multiplexed FPGA[
Shen et al. present a serial-equivalent static and dynamic parallel router[
Vercruyce et al. propose CRoute[
3. Target FPGA architecture
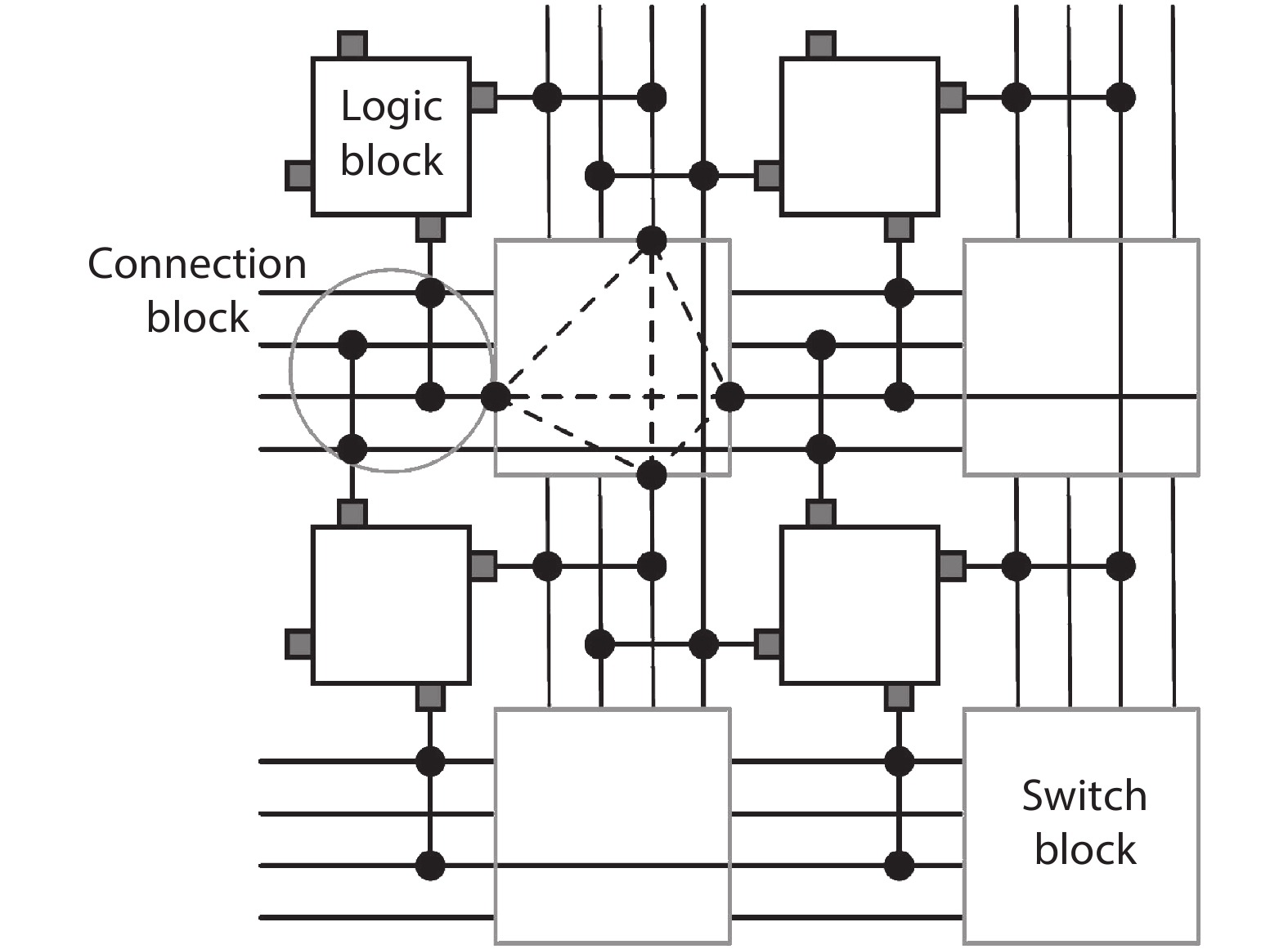
Fig. 1 illustrates an island-style FPGA, which is the base of our target time-multiplexed FPGA architecture. The only difference between this island-style architecture and ours is that all wires in our design can be time-multiplexed. In the conventional island-style FPGAs, vertical and horizontal routing channels surround logic blocks from all four sides containing multiple tracks. We define channel width as the total number of tracks in a channel. Every track has multiple wire segments. A switch block is arranged at every intersection of a vertical channel and a horizontal channel. Programmable switches are placed in switch blocks and connection blocks to implement configurable routing. Logic block pins are connected to routing channels through connection blocks.
![]()
Figure 1.Island-style architecture, which is the base of TM-ARCH with the time-multiplexed interconnects.
3.1. Clock cycle and microcycle
In our new architecture, we divide a clock cycle into multiple microcycles. Different signals can occupy the same wire if this wire is multiplexable, and they can use the same wire at different microcycles in a clock cycle. We use a similar definition of microcycle and clock cycle as in Trimberger et al.’s work[
3.2. Time-multiplexed wires
A route of nets is usually made up of many segments of wires. One segment of a wire can only be occupied between the time that the signal arrives and leaves in one clock cycle. In the TM-ARCH FPGAs, different signals can occupy the same segment of wires at different time if this wire segment can be multiplexed. Fig. 2(a) illustrates this. We first define that one clock cycle consists of two microcycles in this TM-ARCH architecture device.
![]()
Figure 2.(a) Signals
3.3. TM switch
A time-multiplexing switch (TM switch) is the key to implement time-multiplexing at the hardware level. Compared with conventional FPGAs, a TM switch has two more features: latching data and associating with multiple contexts.
3.3.1. Multiple contexts
In TM-ARCH, a TM switch can have at most
3.3.2. Latching capability
A TM switch can latch the current logic value when it switches from on to off state. Fig. 2 illustrates the necessity of latching data. In the first microcycle, the state of TM switches S
Francis’ architecture[
4. Time-multiplexing-aware timing-driven-routing algorithm
4.1. Problem formulation
![]()
Figure 3.Routing resource graph of TM-ARCH architecture.
For a signal
The router of TM-ARCH is designed for optimizing the circuit delay and routing all the nets at the same time. The router should identify and then schedule multiple qualified nets to a time-multiplex wire because the wire is time-multiplexed in TM-ARCH architecture.
4.2. Occupation bitmap
Our algorithm can identify a net (or a signal) that can be multiplexed to a wire with other signals. We record the time when a signal arrives and leaves. This helps us to get the signal’s occupation bitmap, which shows at which microcycle this signal may occupy this wire.
4.2.1. Arrival and leave time
A Maze router[
We compute two timing values:
In Eq. (1), the first item on the right side indicates the time needed from the source of net
4.2.2. Occupation bitmap
We can compute the occupation bitmap by using all the
Each element in the bitmap array can be 0 or 1. “1” means that the net uses the wire at the corresponding microcycle. “0” means that the net does not occupy.
We use the following function to calculate each element in the array,
We also use
Fig. 4 gives the pseudo code for computing bitmaps. We first set all bitmap array elements to zero. Next, we compute which microcycle signal will arrive and give it to variable
![]()
Figure 4.Pseudo code for computing the occupation bitmaps.
We also record the bitmap array for every wire in net
4.3. Congestion penalties at microcycles
Because wires in our architecture can be multiplexed by nets, our algorithm can record how many nets are currently using this wire at every microcycle by using the micro occupancy. This micro occupancy illustrates the degree of congestion at each microcycle for a wire. Our algorithm can compute the congestion penalties of wire at each microcycle based on its micro occupancy values when the wavefront arrives at the wire. Larger micro occupancy will cause larger congestion penalty.
4.3.1. Micro occupancy
Micro occupancy is a matrix that consists of
Firstly we set all micro occupancy elements to zero. When wire
where
When a net
where
4.3.2. Historical and present congestion penalty
With the records of micro occupancy, we can calculate the historical and present congestion penalties of a wire in each microcycle. The functions we use are shown as follows:
where
The routing schedule shows what
4.4. Multiplexing-aware congestion cost
Cost calculation of multiplexing-aware congestion is an innovation of this algorithm. We do not consider it as congestion if a wire in our architecture is used by two more signals and they occupy the wire at different time.
Fig. 5 shows the pseudo code for computing congestion cost of wire in the wave expansion process. In this pseudo code, we should have already computed the bitmap array and the newest historical and present congestion penalties for every microcycle.
![]()
Figure 5.Pseudo code for computing the congestion cost.
Lines 1–4 look for the largest historical congestion penalty. Lines 5–10 look for the position where the first “1” value is occurred in a bitmap, and save it to begin index. This means from which microcycle the wire starts to be occupied. Lines 11–16 saves the end index in a similar way, which means at which microcycle the wire occupation ends. Lines 17–20 record the largest present congestion penalty between the begin microcycle and end microcycle. Line 21 computes the overall congestion cost by multiplying the largest historical and present congestion penalties and the base cost of wire.
Eq. (9) is used after the VPR router obtains the new congestion cost. We use the largest historical congestion penalty in all microcycles as
4.5. Overall cost function
The overcall cost function is the sum of two factors as in a VPR router. The first factor is the congestion sensitive cost, which is computed in Section 4.5. The second factor is the delay sensitive cost. We use the wire’s intrinsic delay as the delay cost and weighs the two parts based on timing criticality. Eq. (10) shows the overall cost function in our algorithm.
4.6. Legal routing solution
Our routing algorithm will check whether the current routing is effective after each iteration. If it is, our router iteration ends and keeps this solution. But if not, the router will start a new turn iteration.
A valid routing solution should not contain any overused routing resources. Although a wire can be multiplexed to be used by multiple nets, it is not overused as long as it is occupied by at most one net in any microcycle. Our router checks if Eq. (11) are met in every microcycle.
4.7. Pseudo code
Fig. 6 is the pseudo code of time-multiplexing-aware routing algorithm. For each signal in a net, we firstly use the maze router to route one signal from its source to sink over the routing-resource graph and record the path it has expanded. For each wire being expanded, we also record the arrival time and leave time to calculate the occupation bitmap. We use the bitmap to compute and update congestion penalties on this wire and then evaluates this wire's overall cost. We aim to decrease the criticality of the connection while doing the wave expansion. For all nodes in each net, we update its occupied time and Elmore delay after this net has been completely routed. After finishing routing all nets, we compute propagate timing in circuit timing graph and calculate critical path delay. If there is no more overused resources or reach the maximum number of iterations, the program will stop and return the final results.
![]()
Figure 6.Pseudo code for computing the congestion cost.
Lines 6 and 20 show that this algorithm can compute the present congestion penalties at each microcycle for wires. Lines 14, 23, 27, 32 illustrate the fact that our algorithm can compute and update the occupation bitmap on wires. Lines 13, 22, and 26 are where our algorithm compute and update the time of signal arrival and leaving. Line 15 reflects the fact that this algorithm computes the time-multiplexing-aware congestion cost for a wire and then analyzes overall cost of this wire. Line 33 computes the historical congestion penalties at microcycles. Finally, line 4 checks the routing algorithm if there still have any remaining congested routing resources. This has been detailed in Section 4. In addition, our router can also check whether the next condition holds in every microcycle.
4.8. Algorithm analysis
In this part, we mainly focus on its unroutability detection, time complexity and memory requirement.
4.8.1. Unroutability detection
Our algorithm only declares the circuit is unroutable after 50 iterations on the given FPGA like Pathfinder algorithm. Because this process will take a long time, we will enhance our algorithm for quicker unroutability detection.
4.8.2. Time conplexity
The algorithm is based on iterations. In practice, the iteration number is usually limited to a certain number of times. Therefore, it is sufficient to analyze the iteration complexity in this algorithm.
The pseudo-code in Fig. 6 shows that, every iteration is made up of two parts. Netlist routing is the first (lines 5–29), and post-processing is the second (lines 30–34). Netlist routing means running routing algorithm for every net in netlist. Previous work shown that the complexity of the net routing algorithm in Pathfinder is
From Section 4.2, we know that the time consume on a routing-resource node
Next we will do post-processing. The main computation is computing
Back-annotation Elmore delay (line 30) will take
4.8.3. Memory requirement
In our algorithm, FPGA routing-resource graph and circuit timing graph are requiring a substantial amount of main memory requirement.
We record many information for all nodes in the routing-resource graph, such as its connectivity information, physical information, congestion information, timing information and some other information used for wave expansion.
We record the timing information and connectivity information for all vertex in timing graphs. For edges in timing graph, we record the timing information and connectivity information. Typically,
5. Algorithm validation
We verify our time-multiplexing-aware routing algorithm through experiments. By using this algorithm, we implement benchmark circuits for the TM-ARCH architecture. For comparison, we also implement the same set of benchmark circuits for conventional architectures. To achieve an easy and fair comparison, we use MCNC 20 benchmark circuits with a standard EDA flow.
5.1. Experimental setup
5.1.1. EDA flow
Fig. 7 shows our EDA flow. First, LUTs are packaged into the cluster logic block using the TVPack tool in the VPR 5 package. Next, place the circuit using VPR 5. The wiring is performed twice according to the same placement result. The VPR 5 timing-driven router is used to route circuits to traditional island FPGAs. TM-ARCH FPGAs with time-multiplexed interconnects are supported by our time-multiplexing-aware router. We call these two routing branches as conventional routing and time-multiplexing routing. Since then, we will call VPR timing-driven router and our time-multiplexing-aware router as VPR-ROUTER and TM-ROUTER.
![]()
Figure 7.(Color online) The TM-ARCH and TM-ROUTER evaluation framework.
5.1.2. Assumptions of FPGA architecture
In this work, we only consider similar FPGA architectures. Even with this assumption, FPGA architecture’s design space is still quite large, so we cannot fully study the time-multiplexed interconnects. In order to make the work easier to do, we first fix a representative benchmark FPGA architecture. The benchmark FPGA architecture is represented in Fig. 7 as "arch.xml", which uses conventional interconnects. We replace all wires with our multiplexable wires, so we got the TM-ARCH FPGA architecture shown in Fig. 7 as "tm_arch.xml".
We choose the XML file used in iFAR[
5.2. Results
5.2.1. Minimum channel width
In this part of the experiments, a conventional routing and the time-multiplexing routing perform a binary search to find the minimum channel width for each circuit. VPR-ROUTER routes circuits to FPGA with conventional architecture to find the minimum channel width, and TM-ROUTER does the same work on TM-ARCH FPGA. We set 50 as the maximum iterations number for both routing algorithms.
Table 3 shows the minimum channel width experimental results. The numbers listed under “
We think that, in one clock cycle there are two microcycles that can only supplies little opportunity to TM-ROUTER to achieve time multiplexing of wires. Table 4, “
Table 4 shows that, in the first microcycle, 92.85% of the wires are used, while in the second microcycle, only 5.17% wires are used. This means that TM-ROUTER has very limited opportunities for time-multiplexing in this condition. To implement time-multiplexing in FPGAs, our routing algorithm will match the same wire in the first microcycle and the second microcycle. Table 4 shows that used wire segments are most likely to be used by net in the first microcycle, and less likely to be used by another net in the second microcycle, so our time-multiplexing-aware algorithm may less likely to implement time-multiplexing wires in this situation. Looking back at Section 4, the signal does not be actively delayed by our routing algorithm. But scheduling algorithm of Francis et al’s does it to implement more time-multiplexing[
TM-ARCH generally needs a smaller channel width from
5.2.2. Circuit critical path delay
FPGAs routing resources are often not heavily utilized in order to reduce latency in real applications. So we use 20% more minimum channel width than Table 3 to do the routing process. In this section, we also assume that TM switch has same delay with its conventional switch.
Table 5 lists the critical path delays with low-stress routing for 20 benchmark circuits. “
In conventional FPGAs, circuit critical path may not be routed in the shortest path due to limited routing. This is true even when low-stress wiring is performed. Unlike conventional FPGAs, the TM-ARCH architecture allows multiple signals multiplex wires in different clock cycles. This effectively mitigates its routing congestion. As a result, the circuit critical path is likely to be routed in a shorter path.
6. Conclusion
In this paper we propose a time-multiplexing FPGA architecture and its routing algorithm. Our algorithm actively identifies the qualified interconnects that can be multiplexed on our new FPGA architecture. We have validated the architecture and algorithm by implementing it as a multiplexing-aware router and using this router to implement benchmark circuits to FPGAs with time-multiplexed interconnects. The results show that compared with an existing router targeting a conventional island-style architecture, 38% smaller minimum channel width and 3.8% smaller circuit critical path delay can be achieved.
References
[1]
[2]
[3]
[4] J Luu, I Kuon, P Jamieson et al. VPR 5.0: FPGA CAD and architecture exploration tools with single-driver routing, heterogeneity and process scaling. ACM Trans Reconfig Technol Syst, 4, 32(2011).
[5]
[6]
[7]
[8] M Shen, W Zhang, G Luo et al. Serial-equivalent static and dynamic parallel routing for FPGAs. IEEE Trans Comput-Aid Des Integr Circuits Syst(2018).
[9]
[10]
[11]
[12]
[13]
[14]
[15] D Wang, Z Duan, C Tian et al. A runtime optimization approach for FPGA routing. IEEE Trans Comput-Aid Des Integ Circuits Syst, 37, 1706(2017).
[16]
[17]
[18]
[19]
[20]
[21]
[22]
[23]
[24]
[25]
[26]

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20