
Xianxin Guo, Thomas D. Barrett, Zhiming M. Wang, A. I. Lvovsky. Backpropagation through nonlinear units for the all-optical training of neural networks[J]. Photonics Research, 2021, 9(3): B71
- Photonics Research
- Vol. 9, Issue 3, B71 (2021)
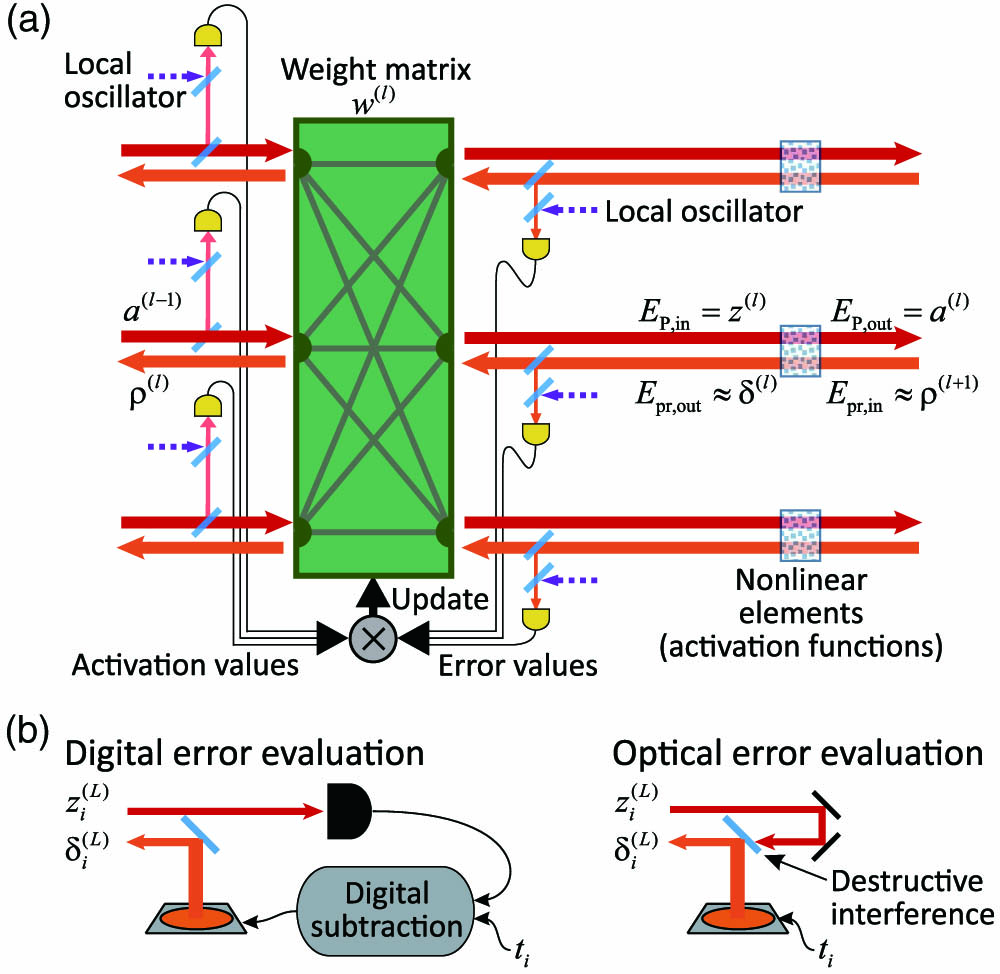
Fig. 1. ONN with all-optical forward- and backward-propagation. (a) A single ONN layer that consists of weighted interconnections and an SA nonlinear activation function. The forward- (red) and backward-propagating (orange) optical signals, whose amplitudes are proportional to the neuron activations, a ( l − 1 ) δ ( l ) 2 ). This multiplication can also be implemented optically, as discussed in the text. The final update of the weights, as well as the preparation of network input, is implemented electronically. (b) Error calculation at the output layer performed optically or digitally, as described in the text.
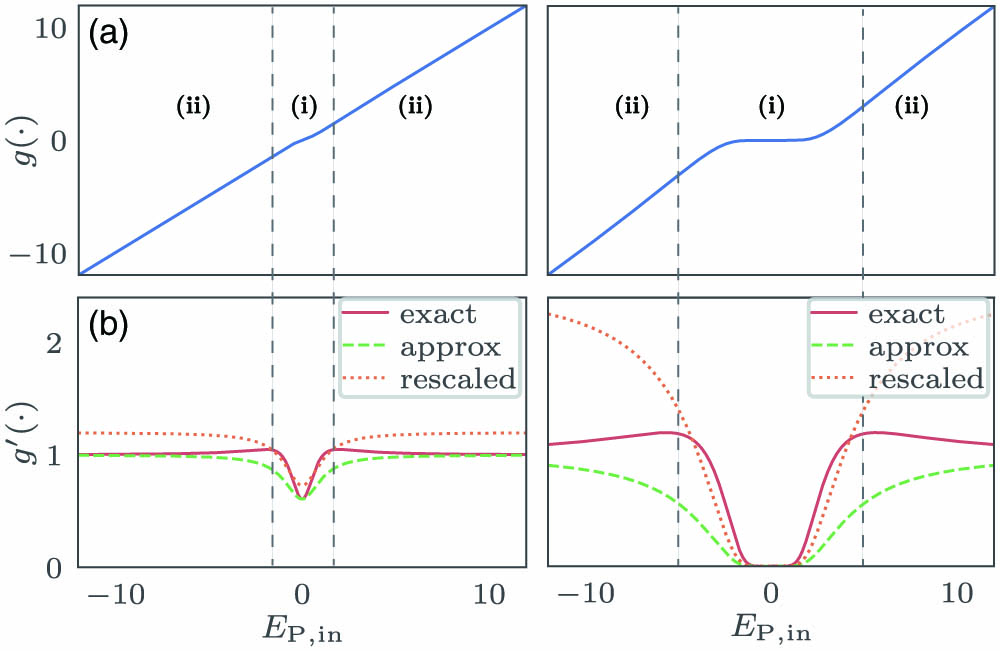
Fig. 2. Saturable absorber response. (a) The transmission and (b) transmission derivative of an SA unit with optical depths of 1 (left) and 30 (right), as defined by Eqs. (4 ) and (6 ), respectively. Also shown in panel (b) are the actual probe transmissions given by Eq. (5 ), which approximate the derivatives, with and without the rescaling. The scaling factors are 1.2 (left) and 2.5 (right). In the amplitude region (i), the SA behaves as a linear absorber for weak input but then exhibits strong nonlinearity when the pump intensity approaches the saturation threshold. Region (ii) corresponds to strong saturation: the ground-state population is depleted, and the absorber is rendered transparent.
Fig. 3. Effects of imperfect approximation of the activation function derivative. (a) Feed-forward neural network architecture using a single hidden layer of 128 neurons. (b) Distribution of neuron inputs (E P , in ( 1 ) ≡ z ( 1 ) g ( · ) α 0 = 10 g ′ ( · ) α 0 = 10 B for details). (e) Average error of the derivative approximation in Eq. (5 ) as a function of the optical depth of an SA nonlinearity.
Fig. 4. Performance on image classification. (a) (i) The fully connected network architecture. (ii) Learning curves for the SA [with either exact derivatives in Eq. (6 ) of the activation function or their approximation in Eq. (5 )] and benchmark ReLU networks. (iii) The final classification accuracy achieved as a function of the optical depth, α 0 28 × 28 N C = 10 N C = 47
Fig. 5. Optical backpropagation through saturable gain (SG) nonlinearity. (a) Fully connected network architecture, which is the same as Fig. 4 (a) except for the nonlinearity. (b) Transmission and transmission derivatives of the SG unit with gain factor g 0 = 3

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20