
Fuzheng Guo, Jun Kong, Min Jiang. Action Recognition Based on Adaptive Fusion of RGB and Skeleton Features[J]. Laser & Optoelectronics Progress, 2020, 57(20): 201506
- Laser & Optoelectronics Progress
- Vol. 57, Issue 20, 201506 (2020)
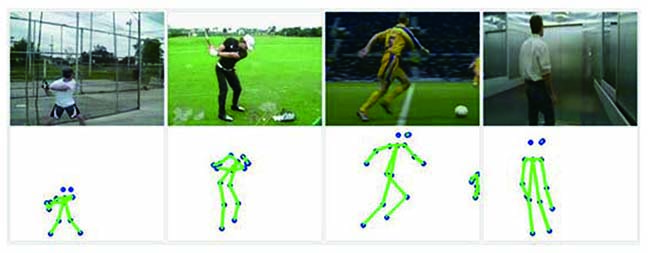
Fig. 1. RGB images and corresponding skeleton images
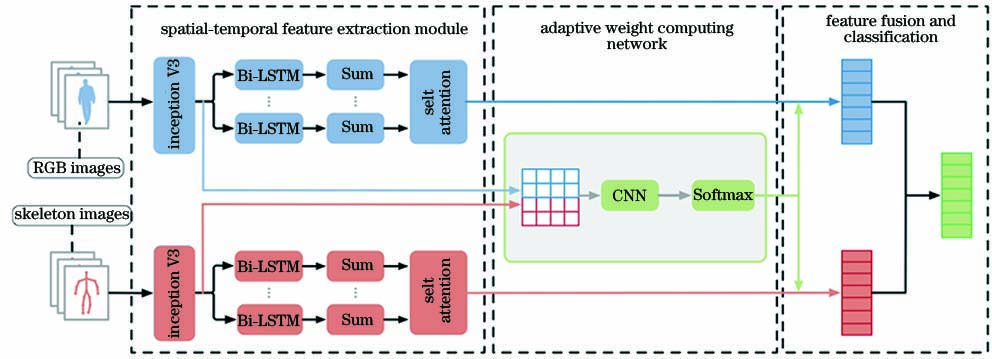
Fig. 2. Overall network
Fig. 3. Spatial-temporal feature extracting network with self-attention
Fig. 4. Adaptive weight computing network
Fig. 5. Feature fusion and classification
Fig. 6. Accuracy of different weight combinations
Fig. 7. Recognition results of using skeleton features only and fusion features
Fig. 8. Visualization of self-attention on skeleton and RGB images of Golf
Fig. 9. Visualization of self-attention on skeleton and RGB images of Baseball swing
Fig. 10. Visualization of adaptive weight of Golf, Baseball swing, Walk and Run
|
Table 1. Experimental parameters
|
Table 2. Accuracy with and without self-attention on Penn Action dataset unit: %
|
Table 3. Accuracy with and without self-attention on JHMDB dataset unit: %
|
Table 4. Comparison of AWCN and other algorithms on Penn Action dataset unit: %
|
Table 5. Comparison of AWCN and other algorithms on JHMDB dataset unit: %
|
Table 6. Comparison of AWCN and other algorithms on NTU RGB-D dataset unit: %

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20