Journals >Laser & Optoelectronics Progress


- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 200401 (2020)

- Publication Date: Oct. 13, 2020
- Vol. 57, Issue 20, 201001 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201003 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201004 (2020)
- Publication Date: Jan. 01, 1900
- Vol. 57, Issue 20, 201005 (2020)

- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201006 (2020)
- Publication Date: Oct. 10, 2020
- Vol. 57, Issue 20, 201007 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201008 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201010 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201011 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201012 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201013 (2020)
- Publication Date: Oct. 13, 2020
- Vol. 57, Issue 20, 201014 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201015 (2020)
- Publication Date: Oct. 13, 2020
- Vol. 57, Issue 20, 201016 (2020)
- Publication Date: Oct. 20, 2020
- Vol. 57, Issue 20, 201017 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201018 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201020 (2020)
ing at the problem of low location accuracy and detection accuracy of fire detection, a fire detection method based on localization confidence and region-based fully convolutional network is proposed. First, expanded separable convolutions are used to improve the receptive field, reduce the amount of model parameters, and improve the detection speed. Second, the prediction candidate frame is translated and stretched to improve the integrity of the candidate region. Then, for non-maximum suppression method, the classification confidence degree is used as a sorting standard, which leads to the error suppression problem, so as to improve the location accuracy and detection accuracy of the candidate frame. Finally, new tags are added, they represent the weak fire with no obvious characteristics and the strong fire with obvious characteristics, respectively. The weak fire samples are strengthened to distinguish the weak fire from the bright background, so as to reduce the sample missing rate. Experimental results show that the proposed method, based on the public fire data set of Bilkent University and the test data collected from the internet, can make the fire area detected to be more complete. The fire position is more accurate, and the fire detection rate is higher.
.- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201021 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201022 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201023 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201101 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201102 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201104 (2020)
- Publication Date: Oct. 13, 2020
- Vol. 57, Issue 20, 201105 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201106 (2020)
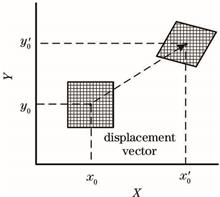
ing at the problems that there exist poor accuracy of the optical flow method and time consumption of the feature point method in traditional visual odometers, we propose the model of a visual odometer by integrating optical flow with feature matching. This model mainly fuses the LK optical flow pose estimation based on inter-frame optimization with the optical flow / feature point pose optimization based on key frames. In addition, aiming at the problem that there occur accumulation errors in the traditional reference-frame/current-frame tracking method, we introduce a local optimization algorithm on the basis of the optical flow method to preliminarily estimate the camera's pose. Simultaneously, aiming at the problems that the image insertion frequency is too high and time consumption in the feature method, we construct a unified loss function of optical flow/feature points on the basis of the key frames to optimize the camera’s pose. The position accuracy test results of the algorithm on the EuRoC dataset show that the position accuracy of the proposed algorithm in simple environments is equivalent to that of the feature point method, and in the case of missing feature points, the proposed algorithm possesses position accuracy higher than that of the feature point method and has certain robustness. The running time test results show that on the basis of ensuring the positioning accuracy, the running time of the proposed algorithm is 37.9% less than that of the feature point method, and the algorithm has the certain real-time performance.
.- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201501 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201502 (2020)
- Publication Date: Oct. 10, 2020
- Vol. 57, Issue 20, 201503 (2020)
ing at the problem of color distortion and edge blur in RetinexNet low illumination image enhancement algorithm, we propose an improved RetinexNet algorithm. First, using the relatively independent characteristics of each channel in the HSV (Hue, Saturation, Value) color space model to enhance the brightness component. Then, the correlation coefficient is used to adaptively adjust the saturation component with the change of the brightness component to avoid changes in image color perception. Finally, aiming at the edge blur problem of the enhanced image, Laplace algorithm is adopted to sharpen the reflectivity image to enhance the ability of detail expression of the image. Experimental results show that the proposed algorithm could effectively enhance the details of the image, keep the overall color of the image consistent with the original image, and improve the visual effect of the image.
.- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201504 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201505 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201506 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201507 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 201508 (2020)
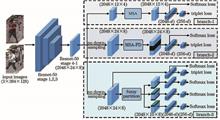
ing at the problem of inaccurate estimation results caused by the complexity of limbs and environment in human pose estimation, a human pose estimation method based on secondary generation adversary is proposed in this work. The stacked hourglass network (SHN) is trained for generation adversary through two stages. First, the SHN is used as a discriminator in the first generation adversarial network model, and the on-line adversarial data is used to strengthen training to improve the estimation performance of the SHN. Then, the SHN acts as a generator in the second generation adversarial network model, and the limb geometric constraints are used as the discriminator. The estimation performance of the SHN is improved again through the second adversarial training, and the final SHN is obtained. The proposed method is tested on the public data sets LSP and MPII, and the results show that it can effectively improve the estimation accuracy of the SHN.
.- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 201509 (2020)
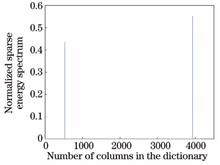
ing at the problems of the co-analysis of multiple 3D models in the function space and the co-segmentation of the whole model cluster, we propose a co-segmentation method based on point cloud sparse coding. First, the point cloud feature is extracted and the 3D information is transformed into the feature space. Second, the dictionary matrix and sparse vectors are constructed after the decomposition of the feature vectors into the base vectors by the deep learning network. Finally, the test data is represented by dictionary sparseness and the category of each point in the point cloud model is determined. To get the co-segmentation result, the homogeneous points are divided into the same region. The experimental results show that the segmentation accuracy on ShapeNet Parts dataset obtained using the proposed algorithm is 85.7%. Compared to the current mainstream algorithms used for segmentation, the proposed algorithm can not only compute the relational structure of model clusters more effectively, but also improve the segmentation accuracy and effect.
.- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 201510 (2020)
- Publication Date: Sep. 26, 2020
- Vol. 57, Issue 20, 201701 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 202801 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 202802 (2020)
- Publication Date: Oct. 14, 2020
- Vol. 57, Issue 20, 202803 (2020)
- Publication Date: Oct. 12, 2020
- Vol. 57, Issue 20, 200001 (2020)
- Publication Date: Oct. 17, 2020
- Vol. 57, Issue 20, 203001 (2020)
- Publication Date: Sep. 26, 2020
- Vol. 57, Issue 20, 203002 (2020)
