Yuhang Li, Tianyi Gan, Bijie Bai, Çağatay Işıl, Mona Jarrahi, Aydogan Ozcan, "Optical information transfer through random unknown diffusers using electronic encoding and diffractive decoding," Adv. Photon. 5, 046009 (2023)
Copy Citation Text
Free-space optical information transfer through diffusive media is critical in many applications, such as biomedical devices and optical communication, but remains challenging due to random, unknown perturbations in the optical path. We demonstrate an optical diffractive decoder with electronic encoding to accurately transfer the optical information of interest, corresponding to, e.g., any arbitrary input object or message, through unknown random phase diffusers along the optical path. This hybrid electronic-optical model, trained using supervised learning, comprises a convolutional neural network-based electronic encoder and successive passive diffractive layers that are jointly optimized. After their joint training using deep learning, our hybrid model can transfer optical information through unknown phase diffusers, demonstrating generalization to new random diffusers never seen before. The resulting electronic-encoder and optical-decoder model was experimentally validated using a 3D-printed diffractive network that axially spans <70λ, where λ = 0.75 mm is the illumination wavelength in the terahertz spectrum, carrying the desired optical information through random unknown diffusers. The presented framework can be physically scaled to operate at different parts of the electromagnetic spectrum, without retraining its components, and would offer low-power and compact solutions for optical information transfer in free space through unknown random diffusive media.
Free-space optical communication has been an active research area and has gained significant interest due to its unique advantages, such as large bandwidth and high transmission capacity.1–4 It has various applications in, e.g., remote sensing, underwater communication, and medical devices.5–8 One of the challenges that limits optical data transmission in free space with high fidelity is the existence of diffusive random media in the optical path, distorting the optical wavefront, which causes inevitable information loss during the wave propagation.9–11 One approach to mitigate the negative impact of such random diffusers along the optical path has been single-pixel detection with several amplitude-only two-dimensional (2D) encoding patterns used to illuminate the object/scene.12–16 However, this approach is relatively slow, since a series of amplitude-only illumination patterns needs to be sequentially generated and transmitted as optical information carriers for each input object or message; furthermore, a digital reconstruction algorithm is required to reveal the input objects through a sequence of structured illumination patterns. Another potential solution involves using adaptive optics to correct distortions;17–19 however, the spatial light modulators (SLMs) and feedback algorithms employed in adaptive optics increase the cost and complexity of such systems. Motivated by the widespread use of deep learning, recent research has also adopted deep neural networks in optical image transmission through scattering media,20–24 increasing the processing speed and robustness to the distortions caused by random diffusers. Nevertheless, all these methods need digital computation to decode, reconstruct, or extract useful information from the distorted transmitted signals, which can be energy-intensive and time-consuming.25–28
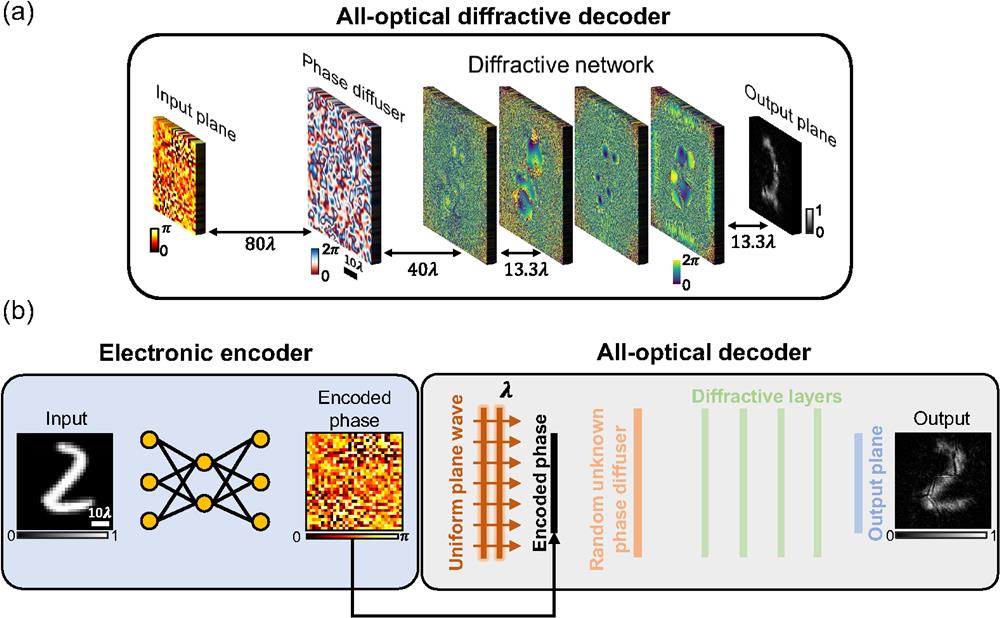
In this work, we demonstrate a jointly optimized electronic-encoder neural network and an all-optical diffractive decoder model for optical information transfer through random unknown diffusers. This electronic-optical design (Fig. 1) is composed of a convolutional neural network (CNN) that encodes the input image information of interest (to be transmitted) into a 2D phase pattern, like an encrypted code, which is all-optically decoded by a jointly trained/optimized diffractive processor that reconstructs the image of the input information at its output plane, despite the presence of random unknown phase diffusers that are constantly changing/evolving (see Video 1). In addition to phase encoding of input information of interest, we also report that amplitude encoding can be used as an alternative scheme for communication through random unknown diffusers using a jointly trained diffractive decoder. Our all-optical diffractive information decoder consists of passive diffractive layers with a compact axial span of and can rapidly decode the encoded optical information (corresponding to any arbitrary input object or message) through random phase diffusers without any digital postprocessing. We experimentally validated the success of this approach using terahertz radiation () and a 3D-printed diffractive network, demonstrating the feasibility of the diffractive decoder with electronic encoding for optical information transmission through random unknown diffusers. The optical decoder of the presented hybrid model can be scaled physically (through expansion or shrinkage) to operate at different parts of the electromagnetic spectrum without the need for retraining its diffractive features. As a result, the presented technique holds potential for wide-ranging applications, such as the transmission of biomedical sensing and imaging data in implantable systems, underwater optical communication, and data transmission through turbulent atmospheric conditions.
Figure 1.Pipeline of the hybrid electronic encoder and optical diffractive decoder for optical information transfer through random unknown diffusers. (a) Schematic drawing of the presented diffractive decoder, which all-optically decodes the encoded information distorted by random phase diffusers without the need for a digital computer. (b) Workflow of the hybrid electronic-optical model: the electronic neural network encodes the input objects into 2D phase patterns and the all-optical diffractive neural network decodes the information transmitted through random, unknown phase diffusers.
2.1 Design of a Diffractive Decoder with Electronic Encoding for Optical Information Transfer through Unknown Random Diffusers
Figure 1(b) shows the operational pipeline of the presented electronic-encoder and optical-decoder model for optical information transfer through random phase diffusers. A CNN-based encoder (see Appendix) was trained to convert any given input image to be transferred into a phase-encoded pattern, illuminated by a uniform plane wave. The corresponding optical field distorted by random unknown phase diffusers was then decoded by the diffractive network to all-optically recover the original image at its output field–of-view (FOV).
Sign up for Advanced Photonics TOC. Get the latest issue of Advanced Photonics delivered right to you!Sign up now
First, we analyze the impact of the encoder CNN on the optical information transfer through unknown random diffusers present in the optical path, and quantitatively explore its necessity, as opposed to a diffractive decoder that is trained alone. In this analysis, we compared it against the architecture of our previous work,29,30 which was used to see amplitude objects through random diffusers using a diffractive neural network, as shown in Fig. 2(a). Without any encoder neural network present, this diffractive processor could see through random unknown diffusers after its training with hundreds to thousands of examples of random diffusers, successfully generalizing to see through new random diffusers never seen before. However, with the increase in the distance between the input objects and the random phase diffuser plane, a performance drop was observed, as shown in Fig. 2(c). Here we used the Pearson correlation coefficient (PCC) to assess the quality of the output images synthesized by the diffractive network as a function of the Fresnel number (), where is the half-width of the input object FOV and is the axial distance between the input plane and the unknown phase diffuser plane, which was swept from to (see Appendix). These comparative results shown in Figs. 2(a) and 2(c) reveal that while a diffractive decoder alone can be trained to successfully generalize to see through unknown random diffusers, its all-optical image reconstruction quality drops as increases to more than (corresponding to ) for a diffuser correlation length of . For example, consider the extreme case of approaching 0 (i.e., ): in this case, it is expected that a diffractive decoder alone can create a diffraction-limited image of the object at its output FOV, since the problem of this special case boils down to a spatially incoherent31 imaging system where the impact of a random phase diffuser rapidly changing at can be considered as spatially incoherent illumination of a static amplitude-only object. As increases, however, each randomly changing phase grain at the diffuser plane will start introducing perturbations to spherical waves that originate from a larger number of the object points at the input plane due to diffraction across , making the image reconstruction a more difficult problem. This is at the heart of the performance reduction observed in Figs. 2(a) and 2(c) for the diffractive decoder alone operating at () for . The all-optical image reconstruction examples of the handwritten digit “8” with only the diffractive decoder layers (no electronic-encoder network) also confirm this conclusion in Fig. 2(a), where the contour of the digit “8” became unrecognizable when .
Figure 2.Comparison between all-optical diffractive networks and the hybrid electronic-optical models for transferring optical information through random unknown diffusers. (a) Schematic of a four-layer diffractive network trained to all-optically reconstruct the amplitude images of input objects through random phase diffusers without electronic encoding. (b) Schematic of a four-layer diffractive decoder with an electronic encoder jointly trained to decode the encoded optical image through random unknown diffusers. (c) The information transmission fidelity (PCC) of the two approaches (all-optical versus hybrid) as a function of the Fresnel number () of the diffractive system. All the parameters were identical in the two approaches being compared, except for the existence of the electronic encoder (at the front end of the hybrid approach).
To break through this limitation and extend the capabilities of diffractive neural networks to communicate through random unknown diffusers, we jointly trained an electronic encoding neural network to collaborate with the all-optical diffractive decoder network for transferring optical information through random unknown phase diffusers, covering a much larger span of and as shown in Figs. 2(b) and 2(c). To achieve this enhanced performance with the hybrid (electronic-optical) model, a data-driven supervised learning strategy was utilized to transfer any optical information or message of interest through random unknown phase diffusers. Specifically, we trained a CNN-based electronic neural network (see Fig. S1 in the Supplementary Material), which encoded the input samples from the MNIST data set into phase-only 2D patterns (codes), and a four-layer diffractive network was jointly optimized with this CNN to be able to decode the optical fields distorted by random unknown diffusers at the output FOV. This decoding part and the reconstruction of the object images are performed all-optically and rapidly completed at the speed-of-light propagation through thin passive layers, without any external power source. Multiple () randomly generated diffusers, modeled as thin phase masks, were introduced in each training epoch to build generalization capability for both the electronic encoder and the diffractive decoder against the distortions caused by random phase diffusers, as shown in Fig. 3(a). The correlation length () was used to characterize random diffusers with respect to their effective grain size, and all the random diffusers used in the training and blind testing were set to have the same correlation length, (see Appendix). During the training stage, handwritten digits were fed to the electronic encoder, and the resulting encoded phase patterns were illuminated by a uniform plane wave, propagating through the corresponding random diffuser and the successive diffractive layers to form the intensity profiles at the output plane. The height values of the diffractive features at each layer were adjusted through stochastic gradient descent-based error backpropagation by minimizing a PCC-based loss function between the target optical information and the decoded output intensity profiles (see Appendix). The encoder and the decoder were trained simultaneously for 100 epochs, i.e., different random diffusers were used during the entire training process. Figure 3(b) shows the resulting diffractive layers of the trained diffractive decoder.
Figure 3.Optical information transfer through random phase diffusers using electronic encoding and diffractive decoding. (a) Random phase diffusers with a correlation length used for training and testing the presented joint electronic-optical model. (b) Phase profiles of the trained diffractive layers of the optical decoder. (c) Examples of optical information encoded by an electronic-encoder CNN that is jointly trained with an optical decoder; output images processed by the all-optical decoder are also shown on the right. (d) Sample images captured by an aberration-free diffraction-limited lens.
To demonstrate the efficacy of this trained hybrid electronic encoder and optical decoder for transferring optical information through random phase diffusers, we first compared its performance to that of a conventional lens-based image transmission system (see Appendix). The imaging results of the same objects through the same diffusers, as shown in Fig. 3(d), exhibited blurry intensity profiles of handwritten digits “2,” “7,” and “8” when captured by an ideal lens. These blurry images clearly illustrate the negative impact of the random phase diffusers within the optical path, making it impossible to recognize the transmitted images with the naked eye. In contrast, the jointly trained electronic-optical system, comprising an electronic encoder/front end and an optical diffractive decoder/back end, can successfully transmit and receive these images through unknown new phase diffusers, as shown in Fig. 3(c), indicating the strong resilience of the hybrid system against the distortions caused by random diffusers during the signal transmission process.
To shed more light on the generalization ability of the hybrid model, we further tested it with additional handwritten digits sampled from the test set that were never used during the training stage; these test objects were individually distorted by two newly generated diffusers that were never encountered during the training (termed as new diffusers), as shown in Fig. 4, left two columns. Additional results of this hybrid electronic-optical model for transferring new optical images of interest through random unknown phase diffusers that are constantly changing are shown in Video 1. All of these resulting output images are easily recognizable compared to the blurry counterparts of the ideal lens, revealing the generalization of the trained electronic-encoder and optical-decoder model to new objects and new random phase diffusers that have never been seen before.
Figure 4.Simulation results of the hybrid electronic-optical model for optical information transmission through unknown random phase diffusers. .
To provide examples of “external generalization” to test objects of different types, we used binary gratings with linewidth, which were not included in the training data set; such linear gratings are vastly different compared to handwritten digits used during training and were employed here to exemplify the external generalization of the jointly trained system for transferring spatial information corresponding to different types of objects through new random diffusers (see Fig. 4, right two columns). After being encoded by the electronic encoder CNN and transmitted through the random phase diffusers, the gratings were successfully decoded by the diffractive optical decoder, even though our electronic-optical model was trained using only MNIST handwritten digits. The successful transmission of different types of object information through random, unknown phase diffusers indicates that our hybrid electronic-encoder and optical-decoder system jointly approximates a general-purpose optical information transfer system, without overfitting to a special class of objects. The spatial resolution of this jointly trained electronic-optical model can be further improved by including training images that contain higher spatial frequency information32 as opposed to using relatively low-resolution training image sets such as MNIST.
2.2 Impact of the Number of Diffractive Layers on the Optical Information Transfer Fidelity
The depth advantages that deeper diffractive architectures possess include better generalization capacity for all-optical inference tasks, which has been supported in the literature by both theoretical and empirical evidence.29,31,33–37 To quantitatively evaluate the impact of the number () of diffractive layers on the accuracy of optical information transfer through unknown random diffusers, we trained three hybrid models, where the architectures of the electronic encoder were kept identical, but the diffractive optical decoders had different numbers of trainable diffractive layers in each model. Figure 5 reports the output results of three exemplary handwritten digits and a test grating object information transferred through a new unknown random diffuser using these three hybrid models with , 4, and 6. The visualization of the decoded images and the corresponding PCC values in Fig. 5 illustrate that the two-layer diffractive decoder network had a relatively lower image reconstruction performance through an unknown random diffuser (despite still providing recognizable images at the output plane). Our results further reveal that the information transmission quality improved significantly as we increased the number of diffractive layers in the decoder architecture, as shown in Fig. 5. The fact that the decoder still worked (despite a compromise in its output image quality) indicates the effectiveness of the joint training strategy, where the electronic-encoder CNN can efficiently collaborate with the diffractive optical decoder and partially compensate for its reduced degrees of freedom caused by fewer diffractive layers in its architecture.
Figure 5.Additional trainable diffractive layers (increasing ) improve the optical information transfer performance through random unknown diffusers. The PCC values are listed for each transmitted message.
In the analyses presented above, we did not impose a bit depth restriction during the training and testing stages, and the encoded phase patterns and the corresponding diffractive heights on each layer were set with a 16-bit depth. In certain applications, the available bit depth of the encoded phase pattern would be limited due to, e.g., the resolution of the SLM; similarly, the bit depth of the diffractive features will be constrained by the 3D fabrication resolution. Motivated to mitigate these challenges, we quantized the electronic encoder and the diffractive decoder that were trained with 16 bits into lower quantization levels in the test stage and investigated the influence of the limited bit depths of the encoded phases’ patterns and the diffractive layers on the quality of the optical information transfer through random new diffusers. Figure 6(a) reports the results of this comparative analysis for several combinations of encoded phase patterns and diffractive decoders with different bit depths. The unconstrained electronic-optical hybrid model’s output results are shown at the top for reference. In this comparison, we first kept the bit depth of the encoded phase patterns as 16-bit while quantizing the diffractive decoder trained with 16-bit to 2-bit, 3-bit, or 4-bit—performing a form of ablation study. The output images of three MNIST handwritten digits and a grating-like object are displayed in Fig. 6(a), revealing a quick improvement in the information transfer performance with increasing diffractive decoder bit depth. We utilized the diffractive decoder (trained under 16-bit depth) using merely 2 bits, and the output image was blurry; however, the output of the 3-bit diffractive decoder improved significantly and the gratings were resolvable [see Fig. 6(a)]. As we further increased the bit depth to 4, the output performance became approximately identical to that of the same model without any bit-depth constraints, as shown in Fig. 6(a).
Figure 6.The impact of the phase bit depth on the optical information transfer fidelity. (a) The joint model trained without any bit-depth limitations, i.e., 16-bit phase representation, and tested with restricted bit-depth phase patterns and decoder pairs. The average PCC value for 10,000 handwritten test digits transmitted through unknown (new) random diffusers is provided in each case. (b) The resulting mean PCC values are compared for various combinations of phase bit-depth. .
On the other hand, when we limited the bit depth of the encoded phase patterns while maintaining the diffractive decoder at 16 bits, it was surprising to find out that even with only 1 bit, i.e., binary-encoded phase patterns, the encoder–decoder system remained capable of transferring the input images of interest through unknown random phase diffusers with acceptable output performance [Fig. 6(a)]. Furthermore, the results obtained using the 2-bit phase encoder were comparable to the unconstrained model [Fig. 6(a), top]. These ablation studies highlight the strong robustness of our information encoding strategy to the changes in the phase bit depth that is available. Figure 6(b) reports additional results for various combinations of quantized encoded phase and quantized diffractive decoder, showing that a larger phase bit depth generally leads to better output image performance.
These earlier results were ablation studies performed after the joint training of the electronic-optical model by reducing the available bit depth at the testing phase of the encoder–decoder pair. To explore the minimum requirement of bit depth for accurately transferring optical information through random diffusers, next we adopted the bit-depth limitation during the training process and created three additional electronic-optical models with different levels of bit depth available; see Fig. 7. When both the encoded phase patterns and the diffractive optical decoder were constrained to only 2 bits, the transferred information suffered from significant distortions at the output; however, the contours of some images were still visible. Keeping a bit depth of 2 for the phase encoder while increasing the diffractive decoder’s bit-depth to 4 achieved much better information transfer, where the spatial details of the input images were successfully reconstructed after passing through random phase diffusers. For the combination where both the electronic phase encoder and the optical diffractive models had 4 bits of phase, the performance of optical information transfer through random diffusers was comparable to the hybrid model trained and tested with 16 bits (see Fig. 7).
Figure 7.The electronic encoder and the diffractive decoder trained and tested with different levels of phase bit-depth. The average PCC values are listed for each case. .
2.4 Experimental Demonstration of Optical Information Transfer through Unknown Random Phase Diffusers Using a Diffractive Decoder with Electronic Encoding
The presented hybrid electronic-optical model was demonstrated experimentally based on a terahertz continuous-wave (CW) system, operating at , as shown in Figs. 8(c) and 8(d) (see Appendix). The resulting phase patterns encoded from the input images by the electronic-encoder CNN were physically 3D-printed and illuminated by the terahertz source, propagating forward through a 3D-printed unknown random diffuser and the diffractive decoder layers, positioned sequentially. For this proof-of-concept experimental demonstration, we jointly trained an electronic-encoder CNN and a diffractive decoder with two layers (), each consisting of diffractive neurons with a size of 0.4 mm. Owing to the limitations posed by the 3D printer’s resolution and build size, we adjusted the dimensions of the optical elements and operated at a Fresnel number of 9.4, thereby maintaining the difficulty of the information transfer task through random diffusers [see Fig. 2(c)]. This electronic-optical model was trained with different random diffusers for 100 epochs, i.e., different random diffusers were utilized during the training, each with a correlation length of . Moreover, an additional output power efficiency loss was introduced to make the diffractive decoder strike a good balance between the information transfer performance and diffraction efficiency (see Appendix). To mitigate the negative impact of potential misalignments during the fabrication and assembly of the optical components, we also introduced random displacements to the diffractive layers (on purpose) in the training process, “vaccinating” the diffractive decoder against such imperfections (see Appendix for details).38Figure 9 shows the experimental results of the optical information transfer through unknown random phase diffusers using a 3D-printed diffractive decoder and electronic encoding. The experimental measurements match the simulation results very well, confirming the feasibility of the hybrid electronic-optical model to effectively transfer optical information and messages of interest through random unknown phase diffusers.
Figure 8.Experimental demonstration of optical information transfer through an unknown random diffuser using a jointly trained pair of an electronic encoder and an optical decoder. (a) Schematic of the joint model for experimental demonstration. (b) Left: height profiles of a new random diffuser (never seen before) and the trained diffractive layers of the all-optical decoder. Right: the fabricated new random diffuser and the diffractive layers used in the experiment. (c) Schematic of the terahertz system. (d) Photograph of the experimental setup and the 3D-printed diffractive decoder.
Figure 9.Experimental results of optical information transfer through an unknown random phase diffuser using the 3D-printed diffractive decoder with electronic encoding.
We presented a joint electronic-encoder and optical-decoder model designed to transfer optical information through random unknown phase diffusers, outperforming (1) an ideal (diffraction-limited) imaging system and (2) a system solely employing trainable diffractive surfaces, as demonstrated in our previous work.30 With an electronic-encoder CNN encoding the original input images into 2- to 4-bit depth phase patterns, a jointly trained diffractive optical decoder becomes much more resilient to the distortions caused by random, unknown phase diffusers along the optical path, leading to enhanced performance and higher data transmission fidelity. The diffractive optical decoder, consisting only of passive diffractive layers, can decode the encoded information through random phase diffusers at the speed of light and enable the hybrid model to work with low power consumption. The overall volume of the diffractive optical decoder is also compact, with an axial span of . Our experimental results in the terahertz part of the spectrum confirmed the applicability of our hybrid electronic-encoder and optical-decoder model for transferring optical information through unknown random diffusers.
Note that the phase encoding strategy employed in our models could also be interchanged with an amplitude encoding scheme, while sustaining a comparable level of performance and data transmission fidelity across random, unknown diffusers. To showcase this, we trained an alternative hybrid electronic-optical model using amplitude encoding to transfer optical information through random phase diffusers with a correlation length of , maintaining all the other parameters the same as the model shown in Fig. 1. The average of the PCC values resulting from the blind testing of this hybrid model with unknown objects distorted by unknown diffusers was 0.88, similar to the performance of the reported hybrid model with phase-only encoding, underscoring the applicability of the amplitude encoding scheme.
In our results reported so far, the positioning of the diffusers remained constant during the training and testing phases. To assess the impact of unknown diffuser location on the data transmission fidelity, we blindly tested the model shown in Fig. 1(a), trained using a fixed diffuser location, with varying axial positions spanning to around the designed position; see Fig. S2 in the Supplementary Material. These blind testing results revealed that our hybrid model, despite being trained with a fixed diffuser position, maintained satisfactory data transmission fidelity within a diffuser axial position uncertainty range of ; however, beyond this range, a considerable drop in fidelity was observed, as depicted in Fig. S2 in the Supplementary Material (green curve). To further enhance the electronic-optical hybrid model’s resilience to diffuser position uncertainty, we adopted a “vaccination” strategy, similar to what we employed in the training of the experimental model (see Appendix), by randomly shifting the unknown diffusers around their designated axial position. Subsequently, four additional hybrid models with different amounts of vaccination, covering diffuser shift levels of , and were trained; after their training, we report the data transmission fidelity results of these vaccinated models as a function of the diffuser location uncertainty in Fig. S2 in the Supplementary Material. These results reveal that, by intentionally introducing uncertainty in the diffuser axial position during training, we can build an electronic-encoder/optical-decoder pair with improved resilience to random and unknown variations in the diffuser position, while retaining a decent data transmission fidelity, making this framework more suitable for real-world applications, where the position of the scattering media can vary randomly.
Following the previous literature on random phase diffusers,21,22,39,40 in this work, we used thin optical elements with random phase patterns to simulate diffusers; the exploration of volumetric diffusers, which can be described by several thin phase diffusers and split-step beam propagation, is an exciting future research direction.41,42 In addition, wavelength-division multiplexing, widely used in fiber-optic communication to enable high transmission bandwidths,43 can be integrated into the presented jointly trained models, allowing simultaneous information transfer at multiple wavelengths and increasing the overall capacity of information transfer through random unknown diffusers. Finally, our method can be physically scaled (expanded/shrunk) with respect to the illumination wavelength without retraining its components and can operate at different parts of the electromagnetic spectrum to transfer optical information through random scattering media.
4 Appendix
4.1 Electronic Encoder Design
We used a CNN to encode the input object into a 2D phase pattern. The network architecture is shown in Fig. S1 in the Supplementary Material, which has convolutional layers with filters followed by batch normalization (BN)44 and a parametric rectified linear unit.45 We performed downsampling directly by max pooling. The network ends with two fully connected layers and a sigmoid activation layer.
4.2 All-Optical Diffractive Decoder Model
The monochrome illumination with a wavelength of was used for optical information transfer through unknown random diffusers. The diffractive layers were modeled as thin optical modulation elements where the complex transmission coefficient of the layer located at can be modeled as
Both the amplitude modulation and the phase modulation can be written as a function of the diffractive neuron’s thickness and the incident wavelength , where and are the refractive index and the extinction coefficient of the material, respectively, i.e., the complex refractive index can be written as . In this work, the height of each neuron was defined as where is the variable optimized during the data-driven training procedure. The actual height of each diffractive neuron was calculated by setting and a fixed base thickness of .
We modeled the random diffusers as pure phase elements, whose complex transmission can be calculated using the refractive index difference between the air and the diffuser material []. The random height map was defined as where denotes the remainder after division, and is a random height matrix with each pixel, i.e., , following a normal distribution with a mean of and a standard deviation of , i.e., is a zero-mean Gaussian smoothing kernel with a standard deviation of , and “ ” denotes the 2D convolution operation. The phase-autocorrelation function of a random phase diffuser [] is calculated as where refers to the correlation length of the random diffuser. By numerically fitting the function to , we can statistically get the correlation length of randomly generated diffusers. In this work, for , , and , we calculated the average correlation length as based on 2000 randomly generated phase diffusers.
Adjacent optical elements (e.g., input phase patterns, random diffusers, diffractive layers, and detectors) are optically connected by free-space light propagation in air, which was formulated using the Rayleigh–Sommerfeld equation.46 The propagation can be modeled as a shift-invariant linear system with the impulse response, where and .
Considering a plane wave that is incident at a phase-modulated object positioned at , we can write the distorted image right after the random phase diffuser located at as
This distorted field is used as the input field of subsequent diffractive layers. And the optical field right after the diffractive layer at can be written as where is the axial distance between two successive diffractive layers. After being modulated by all the diffractive layers, the optical field was collected at an output plane that was away from the last diffractive layer. The intensity is used as the decoded output intensity profile of the diffractive decoder,
4.3 Digital Implementation
For the diffractive decoder, we sampled the 2D space with a grid of , which is also the size of each diffractive neuron on the diffractive layers. Every diffractive layer and random diffusers had a size of (). A coherent light illumination with a wavelength of was assumed. Both the input and output FOVs were set to be , which corresponds to . The axial distances between the input phase object and the random diffuser, the diffuser and the first diffractive layer, two successive diffractive layers, and the last diffractive layer and the output plane were set to be , , , and , respectively.
During the joint training process of the electronic encoder and the diffractive decoder using deep learning, we first normalized the handwritten digits from the MNIST training data set to the range [0, 1] and bilinearly interpolated them from to (). After being transformed by the electronic encoder into a phase distribution, the resulting encoded phase patterns were upsampled to () using the “nearest” mode to match the size of the input FOV. In addition, we interpolated to with “nearest” mode as well to serve as the target output . In our simulation optical forward model, we assumed the material absorption of the objects, diffusers, and diffractive layers to be zero [i.e., ], which is a reasonable assumption considering that these are thin optical elements. Accordingly, the input phase objects can be expressed as , where .
During the training, uniquely different phase diffusers were randomly generated at each epoch. In each training iteration, a batch of different objects from the MNIST handwritten digit data set was sampled randomly and fed to the electronic encoder; each corresponding encoded phase pattern in a batch was numerically duplicated times and separately perturbed by a set of randomly selected diffusers. Therefore, different optical fields were obtained, and these distorted fields were individually forward-propagated through the same state of the diffractive network. Therefore, we obtained different decoded output intensity profiles at the output plane (), which were used for the PCC-based training loss function calculation, where denotes the PCC value between the output image and the target image, calculated using
To validate the necessity of employing a hybrid electronic-encoder and optical-decoder model for optical information transmission through random phase diffusers, we trained both the hybrid model and the diffractive decoder independently using various values of , corresponding to Fresnel numbers of , calculated for an input object width of .
The electronic encoder and the diffractive optical decoder were jointly trained using Python (v3.8.16) and PyTorch (v1.11, Meta AI) with a GeForce RTX 3090 graphical processing unit (Nvidia Corp.), an Intel® Core™ i9-12900KF central processing unit (Intel Corp.), and 64 GB of RAM, running the Windows 11 operating system (Microsoft Corp.). The calculated loss values were backpropagated to update the weights and biases of the electronic encoder and diffractive neuron heights using the Adam optimizer47 with a decaying learning rate of , where epoch refers to the current epoch number. Training a typical joint electronic-optical model takes to complete with 100 epochs and diffusers per epoch.
4.4 Quantization of the Encoded Phase and the Diffractive Decoder Layers
To evaluate the performance of the hybrid electronic-encoder and optical-decoder models under limited bit-depth cases, we quantized the encoded phase and/or the heights of the features on the diffractive layers into lower quantization levels. For the encoded phase patterns with a maximum phase of , the range was equally divided into steps. For example, the 1-bit encoded phase is binary encoded with 0 and , while the 2-bit encoded case has , i.e., four steps. In the same way, we quantized the diffractive decoder heights in the range of .
4.5 Terahertz Experimental Setup and Design
The experimental setup is shown in Fig. 8(b). The terahertz source used in the experiment was an AMC (modular amplifier, WR9.0M SGX, Virginia Diode Inc.; multiplier chain, WR4.3x2 WR2.2x2, Virginia Diode Inc.) with a compatible diagonal horn antenna (WR2.2, Virginia Diode Inc.). The input of the AMC was a 10 dBm RF input signal at 11.1111 GHz () and after being multiplied 36 times, the output signal was CW radiation at 0.4 THz. The AMC was also modulated with a 1 kHz square wave for lock-in detection. The distance between the exit aperture of the horn antenna and the object plane of the 3D-printed diffractive optical network was about 75 cm. After passing the diffractive decoder network, the output signal was 2D scanned with a 1.2 mm step by a single-pixel Mixer (WRI 2.2, Virginia Diode Inc.) placed on an positioning stage, built by combining two linear motorized stages (NRT100, Thorlabs). A 10 dBm RF signal at 11.0833 GHz () was sent to the detector as a local oscillator to down-convert the signal to 1 GHz for further measurement. The down-converted signal was amplified by a low-noise amplifier (ZRL-1150-LN+, Mini-Circuits) and filtered by a 1 GHz () bandpass filter (Electronics 3C40-1000/T10-O/O, KL). The signal first passed through a low-noise power detector (ZX47-60, Mini-Circuits) and then was measured by a lock-in amplifier (SR830, Stanford Research) with the 1 kHz square wave used as the reference signal. The lock-in amplifier readings were calibrated into a linear scale.
The phase objects, diffusers, and diffractive layers used for experimental demonstration were fabricated using a 3D printer (Objet30 Pro, Stratasys). The absorption of the 3D printing material was taken into account and estimated by Eq. (2) for the phase patterns, diffusers, and diffractive layers during the training. For the two-layer decoder model used in the experimental demonstration, each diffractive layer consisted of diffractive neurons, each with a lateral size of 0.4 mm. The diffuser had the same size as the diffractive layers with (). The size of the input and output FOV was designed as (). The axial distances between the input phase object and the random diffuser, the diffuser and first diffractive layer, two successive diffractive layers, and the last diffractive layer and the output plane were set to be , and , respectively.
To build the resilience of the diffractive decoder layers to potential mechanical misalignments in the experimental testing, the diffractive decoder was “vaccinated” with deliberate random shifts during the training.38 For this vaccination process, a random lateral displacement () was added to the diffractive layers, where and were randomly and independently sampled, i.e.,
A random axial displacement of was also added to the axial separations between any two consecutive diffractive planes. Accordingly, the axial distance between any two consecutive diffractive layers was set to , where is the designed distance and was randomly sampled,
Considering the material absorption and minimum detectable signal in our experiments, we also added another power penalty to balance the output quality and the diffraction efficiency. We calculated the power efficiency of the diffractive network as and the corresponding diffraction efficiency penalty was calculated as follows: where was the target power efficiency, which was set to 0.04 empirically. Consequently, the total loss function that included the power-efficiency penalty was used for the training of our experimentally tested model and can be rewritten as
4.6 Image Contrast Enhancement
To better visualize the images, we digitally enhanced the contrast of the experimental measurements using a built-in MATLAB function (imadjust), which by default saturates the top 1% and the bottom 1% of the pixel values and maps the resulting images to a dynamic range between 0 and 1. All the quantitative data analyses, including PCC calculations and resolution test target results, are based on raw data without applying image contrast enhancement.
4.7 Simulation of the Standard Lens-Based Image Transmission System
We numerically implemented a conventional lens-based image transmission system to evaluate the impact of a given random diffuser on the output image. A Fresnel lens was designed to have a focal length () of and a pupil diameter of , whose transmission coefficient was formulated as where is the pupil function,
The lens was placed () away from the input objects, and the image plane was also () away from the lens. The light propagation was calculated using the angular spectrum method. And the intensity profiles at the image plane were collected as the results of imaging through random phase diffusers using an ideal diffraction-limited lens.
Yuhang Li received his BS degree in optical science and engineering from Zhejiang University, Hangzhou, China, in 2021. He is currently working toward his PhD in Electrical and Computer Department at the University of California, Los Angeles, California, United States. His work focuses on the development of computational imaging, machine learning, and optics.
Tianyi Gan received his BS degree in physics from Peking University in 2021. He is currently a PhD student in the Electrical and Computer Engineering Department at the University of California, Los Angeles. His research interests are terahertz source and imaging.
Bijie Bai received her BS degree in measurement, control technology and instrumentation from Tsinghua University, Beijing, China, in 2018. She is currently working toward her PhD in the Electrical and Computer Engineering Department, University of California, Los Angeles, California, United States. Her research focuses on computational imaging for biomedical applications, machine learning, and optics.
Çağatay Işıl graduated with a BS degree in electrical-electronics engineering (EE) in 2017 and a BS degree in physics in 2018 from Middle East Technical University in Ankara, Turkey. Subsequently, he completed his MS degree in EE at the same institution. Currently, he is actively engaged in pursuing his doctorate in the Electrical and Computer Engineering Department at the University of California, Los Angeles (UCLA), located in California, United States. His research is primarily centered around the advancement of virtual staining techniques and all-optical machine-learning systems.
Mona Jarrahi is a professor and Northrop Grumman Endowed Chair in electrical and computer engineering at UCLA and the director of Terahertz Electronics Laboratory. She has made significant contributions to the development of ultrafast electronic and optoelectronic devices and integrated systems for terahertz, infrared, and millimeter-wave sensing, imaging, computing, and communication systems by utilizing novel materials, nanostructures, and quantum structures, as well as innovative plasmonic and optical concepts.
Aydogan Ozcan is the Chancellor’s Professor and the Volgenau Chair for Engineering Innovation at UCLA and an HHMI professor with the Howard Hughes Medical Institute. He is also the associate director of the California NanoSystems Institute. He is elected fellow of the National Academy of Inventors (NAI) and holds more than 65 issued/granted patents in microscopy, holography, computational imaging, sensing, mobile diagnostics, nonlinear optics, and fiber-optics, and is also the author of one book and the co-author of more than 1000 peer-reviewed publications in leading scientific journals/conferences. He is an elected fellow of Optica, AAAS, SPIE, IEEE, AIMBE, RSC, APS, and the Guggenheim Foundation, and is a lifetime fellow member of Optica, NAI, AAAS, and SPIE. He is also listed as a highly cited researcher by Web of Science, Clarivate.
Yuhang Li, Tianyi Gan, Bijie Bai, Çağatay Işıl, Mona Jarrahi, Aydogan Ozcan, "Optical information transfer through random unknown diffusers using electronic encoding and diffractive decoding," Adv. Photon. 5, 046009 (2023)