State Key Laboratory of Precision Measurement Technology and Instruments, Department of Precision Instruments, Tsinghua University, Beijing 100084, China
Deep learning offers a novel opportunity to achieve both high-quality and high-speed computer-generated holography (CGH). Current data-driven deep learning algorithms face the challenge that the labeled training datasets limit the training performance and generalization. The model-driven deep learning introduces the diffraction model into the neural network. It eliminates the need for the labeled training dataset and has been extensively applied to hologram generation. However, the existing model-driven deep learning algorithms face the problem of insufficient constraints. In this study, we propose a model-driven neural network capable of high-fidelity 4K computer-generated hologram generation, called 4K Diffraction Model-driven Network (4K-DMDNet). The constraint of the reconstructed images in the frequency domain is strengthened. And a network structure that combines the residual method and sub-pixel convolution method is built, which effectively enhances the fitting ability of the network for inverse problems. The generalization of the 4K-DMDNet is demonstrated with binary, grayscale and 3D images. High-quality full-color optical reconstructions of the 4K holograms have been achieved at the wavelengths of 450 nm, 520 nm, and 638 nm.
Introduction
Computer-generated holography is a technology that can accurately modulate the light field distribution in three-dimensional (3D) space. It has been widely applied in various fields, including holographic display1-4, meta-surface design5-8, and laser fabrication9. Currently, only a few spatial light modulators (SLMs) can modulate both the amplitude and phase of the wavefront simultaneously. The complex amplitude hologram (CAH) needs to be converted to an amplitude hologram or a phase-only hologram (POH) for display. Compared with the amplitude hologram, the POH provides higher diffraction efficiency and avoids the twin image in the reconstruction. The POH is calculated only with the amplitude constraints on the object plane without any phase constraints. So the solution is not unique. And the amplitude constraints on the hologram plane are equal to 1, so the solution may not exist. The POH generation process is a typical ill-posed inverse problem. The algorithms used to fit this inverse problem are mostly iterative methods, such as Gerchberg–Saxton (GS) algorithm10, 11, Wirtinger algorithm12, and non-convex optimization algorithm13. But they are time-consuming and only can find the local optimal solutions with speckle noise.
Since the high-performance network structure ResNet was proposed in 201614, the powerful ability of deep learning on highly ill-posed inverse problems has been gradually demonstrated15-17. Deep learning has been widely used for types of hologram generation since its parallel operational framework and complex structure based on convolution layers. Compared with the traditional POH algorithms4, 18-21, the learning-based POH has the great potential to realize real-time and speckle-free holographic display. Nowadays, the learning-based POH can be mainly divided into two types: the data-driven deep learning1, 22-29 and the model-driven deep learning30-38.
In the data-driven deep learning, the neural networks fit the inverse problem by learning the coding method from the approximate solutions calculated by traditional algorithms. The image datasets and their corresponding approximate POHs compose the labeled training datasets. The network is trained to extract the non-linear mapping between the labeled training dataset, which can be regarded as a black box. The training process is realized by calculating the loss function between the output POHs and the label POHs, and updating the network parameters by gradient descent algorithms. The trained data-driven network can effectively speed up the POH generation processes of images outside the training dataset1, 22 and has the advantage of simple network structures. However, since the neural network with the data-driven deep learning purely learns the mapping of the image dataset and label POHs, the labeled training dataset quality limits the ceiling of the training performance and POH generalization. And the label POHs need to be generated in advance, which requires large datasets, huge computing resources, and long calculation time. The above two challenges are particularly prominent in the learning-based POH generation problem24-26, which prohibits the practical application of the data-driven method. To avoid using iterative algorithms in the label POH generation process, random phase patterns and their propagating speckle-like intensity patterns are used for training27. This method was also used for binary amplitude holograms28. However, the trained networks work well only for the speckle-like patterns.
To solve the above two challenges, the model-driven deep learning is proposed for the POH generation30, 31. In the model-driven deep learning, the corresponding forward process model of the inverse problem is used as the constraints to train the networks. It can directly fit the inverse problem without the limitation of the approximate solutions. For POH generation, the physical diffraction model is incorporated into the network structure. The loss function can be directly calculated between the image dataset and the output reconstructions, which effectively eliminates the need for label POHs. The network can automatically learn the latent encodings of POHs in an unsupervised way. Current studies have successfully explored and demonstrated the availability of model-driven deep learning for various POH generation tasks. Peng et al. optimized the diffraction model by the camera-in-the-loop (CITL) strategies, which obtained speckle-free holographic images with coherent light sources32, 33 and partially coherent light sources34. Shimobaba et al. realized zoomable reconstruction larger than the holograms35. Liu et al. proposed the phase dual-resolution network (PDRNet) structure to learn the mapping on the same optical plane rather than crossing optical planes36. Sun et al. solved dual tasks of amplitude reconstruction and phase smoothing jointly by loss function optimization37. In our previous research, the model-driven network Holo-Encoder could generate one single-wavelength 4K POH in 0.15 s38. However, due to the insufficient constraints, the existing model-driven networks face the limited convergence result problem39, 40. The transfer learning with the single target image is needed for better reconstruction quality. There is a trade-off between the reconstruction quality and calculation speed, which limits the practical application. The combined-driven method, which combines the advantages of the data-driven and model-driven method, was proposed and achieved high-quality reconstructions of 3D objects41. But it still faces the time-consuming generation challenge of the labeled training dataset.
In this paper, we systematically investigate the existing learning-based POH research and especially analyze the advantages of the model-driven method over the data-driven method. We propose a high-fidelity 4K POH generation network, called 4K Diffraction Model-driven Network (4K-DMDNet). The constraint of the reconstructed images in the frequency domain is strengthened. The network structure combines the residual method and sub-pixel convolution method, which effectively enhances the fitting ability of the network for inverse problems. The generalization of the 4K-DMDNet is demonstrated with both binary and grayscale images, which can achieve high-fidelity and high-speed POH generation for 4K display.
POH generation network of 4K-DMDNet
Network architecture
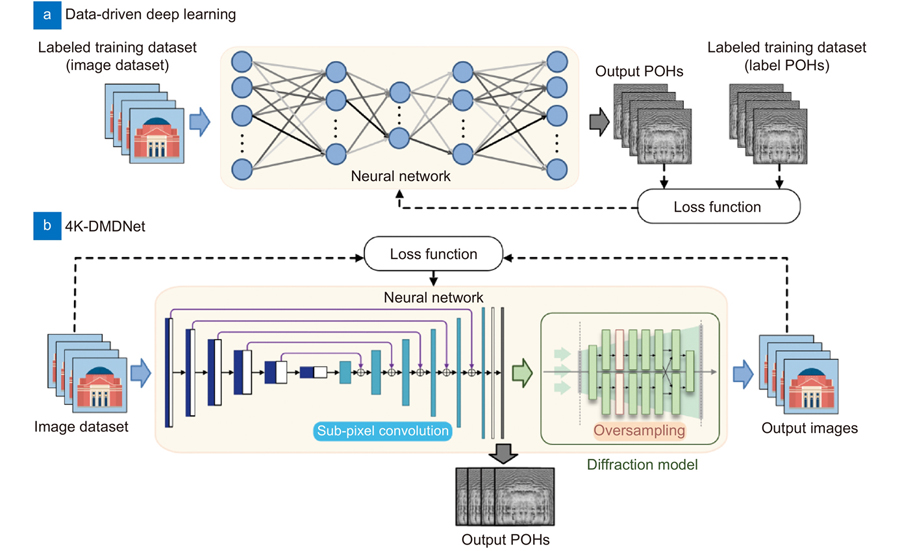
Compared with the data-driven deep learning method, the 4K-DMDNet consists of the convolutional neural network (CNN) for POH generation and the diffraction model for loss function calculation, as shown in Fig. 1. The output of the neural network with the data-driven method is the predicted POHs. The loss function calculates the error between the output POHs and the label POHs, as shown in Fig. 1(a). Thus, it requires the preparation of a labeled training dataset consisting of the image dataset and its corresponding label POHs. However, the label POHs need to be generated by iterative algorithms, which is time-consuming and limits the ceiling of the training performance and generalization. In comparison, the proposed 4K-DMDNet works in an unsupervised way by incorporating the diffraction model as a part of the neural network, as is shown in Fig. 1(b). The diffraction model simulates the light field propagation process. Therefore, the loss function can be directly calculated between the image dataset and the output images. The latent POH encodings can be sought without the label POHs by 4K-DMDNet:
Figure 1.Training processes of (a) data-driven deep learning and (b) 4K-DMDNet, respectively.
where H represents the POH, I represents the target image, and represents the propagation process from the hologram plane to the object plane. Moreover, 4K-DMDNet directly learns the optimal encoding POHs, avoiding the quality degradation caused by the extra complex-to-phase-only conversion operation. Since no random phase is added in the whole calculation process, the ubiquitous speckle noises are significantly suppressed.
Once the network training is complete, the network parameters can be solidified into the computer chip to realize the rapid generation of holograms. The generation and reconstruction process of 4K POHs by the 4K-DMDNet is shown in Fig. 2. A set of images or series of video frames outside the image dataset are input into the network in sequence. The trained network is used to predict the POHs of images. The output POHs are uploaded on the 4K SLM. To realize full-color optical reconstruction, the 4K-DMDNet is trained in three different wavelength versions corresponding to the three channels of the RGB image. The POHs corresponding to the three channels are loaded onto the SLM in turn, and three illumination lasers with different wavelengths are switched simultaneously. This time-multiplexing method can present high-quality color images without interference-induced noise. Finally, observers can see the optically reconstructed image or video at the set distance.
Figure 2.Generation and reconstruction process of 4K POHs by the 4K-DMDNet. The sub-pixel convolution method and oversampling method have played decisive roles to achieve it.
The U-Net network as the CNN of 4K-DMDNet is shown in Fig. 3(a). It consists of a contracting downsampling path to capture context and a symmetric expanding upsampling path that enables precise localization, which achieves excellent performance on different image-to-image problems42. And the skip connection from the downsampling path to the upsampling path is another feature of the U-Net, which makes the output images include more details. Here the downsampling path is a residual neural network, consisting of downsampling blocks and corresponding residual blocks. Each block is composed of two sets of batch normalization, nonlinearity (ReLU), and a 3×3 convolutional layer stacked one above the other. And the residual block effectively solves the degradation problem with skip connections14. The downsampling is realized directly by convolutional layers with a stride of two. The upsampling path consists of upsampling blocks, as shown in Fig. 3(b). In order to achieve 4K hologram generation, the upsampling is realized by the sub-pixel convolution method43. It includes convolutional layers to increase the channel number and a pixel shuffle layer to turn the tensor from H×W×2C to 2H×2W×C/2. And the residual method is also used. Finally, the output layer of the U-Net is a tanh function that limits the POH value in the range of [−π, π].
Figure 3.(a) U-Net neural network architecture of 4K-DMDNet. (b) Upsampling block architecture. The figures between the brackets present the kernel size and the stride of the convolutional layer, respectively.
The learnable parameter number presents the learning capability of network frameworks. For CNN, it is the number and size of the convolution kernels. When the pending data exceeds the learning capability, the network will not converge stably. Increasing the number of convolutional layers is usually used for more learnable parameters. But the deeper the network, the more difficult the training. The upsampling method is another important factor which prominently affects the learnable parameter number. Here we use the sub-pixel convolution method to achieve the 4K hologram generation. It can increase the learnable parameters of the upsampling path by four times without changing the network depth. To highlight the strong learning capability of the sub-pixel convolution method, we compare it with the other two common upsampling methods, as shown in Fig. 4.
Figure 4.(a–c) Schematic diagram of the transposed convolution, NN-resize convolution, and sub-pixel convolution with their corresponding numerical simulations.
The task of the upsampling path is to upscale the low-resolution feature map gradually to the target size. The transposed convolution method, also called the deconvolution method, realizes the upsampling by zero-padding around the input layer to double size and then convoluting with a stride of one. It is the original upsampling method used in the U-Net network. However, its reconstructions face the “checkerboard artifacts” problem, caused by the uneven overlap in the convolution process44, as shown in Fig. 4(a). The nearest neighbor resize convolution (NN-resize convolution) can effectively solve this problem. It replaces the zero-padding operation with the nearest neighbor interpolation, adding more valid information. The sub-pixel convolution further uses learnable parameters instead of interpolation information to enhance network performance. It includes a convolutional layer with a stride of one and four times the original channel number, and a pixel shuffle layer to permute data from the channel dimension into blocks of 2-D spatial data,
The peak signal-to-noise ratio (PSNR) is employed to quantitatively evaluate the reconstruction quality of the above three upsampling methods. We can see that the sub-pixel convolution method can achieve high-fidelity and artifact-free images compared with the other two methods. The PSNR of the reconstruction with the sub-pixel convolution method is 19.27 dB.
Diffraction model of 4K-DMDNet
Fresnel diffraction model in network layer manner
The Fresnel diffraction model is used as the diffraction model of 4K-DMDNet, which is advantageous for computational speed. It calculates the propagation process from the hologram plane to the object plane, as shown in Fig. 5(a). The intensity distribution on the object plane can be formulated as
Figure 5.(a) Schematic diagram of the Fresnel diffraction model. (b) Fresnel diffraction model with oversampling method realized in the neural network layer manner. (c) Comparison between the numerical simulation and optical reconstruction with the undersampling problem. (d) Schematic diagram of the oversampling method.
where represent the coordinates on the object plane and the hologram plane, respectively, represents the complex amplitude distribution on the object plane, denotes the Fourier transform, is the output POH of the U-Net, is the wavelength of the light sources, and is the distance between the two planes. By changing the parameters and , full-color and multi-plane holographic displays can be obtained by the 4K-DMDNet. The calculation process of the Fresnel diffraction model is realized in the network layer manner, as shown in Fig. 5(b). Because the neural network can only backpropagate with real numbers, the light field distribution on the hologram plane is split into real and imaginary parts at the beginning according to the Euler’s formula:
Since the FFT results of real numbers are complex numbers, they need to be split again according to the following formulas:
where is the complex amplitude distribution on the object plane before the second fftshift operation, and are the real and imaginary parts of FFT result in the cos path, and are the real and imaginary parts of FFT result in the sin path. The intensity distribution on the object plane is calculated by .
Oversampling method
Although the model-driven deep learning is an effective tool for high-quality POH generation, the insufficient constraints cause the artifacts on the reconstructions. Here we propose to strengthen the constraints in the frequency domain for solving this problem. The spectrum of the light field is zero padded to double the size in the calculation process. The spectrum of the object plane can be calculated as
So the spectrum S is the inverted image of . The zero padding operations are directly added after the sin and cos layer, as shown in Fig. 5(b).
In addition, this method also plays the role of oversampling. Here we discuss the cause and practical elimination method of the undersampling problem in the Fresnel diffraction calculation. The frequency analysis below is one-dimensional for simplicity. According to the Nyquist-Shannon sampling theorem, the maximum sampling interval on the object plane is determined by the maximum spatial frequency of the light field. The light ray formed by connecting the edge point of the hologram and the center point of the object represents the maximum spatial frequency that the hologram needs to recover, as shown in Fig. 5(a). It can be formulated as
where n and p are the pixel number and pixel pitch of the hologram, respectively. The maximum sampling interval satisfying the Nyquist-Shannon sampling theorem is
However, according to
Eq. (3), the complex amplitude field on the object plane is obtained by multiplying the spherical phase and performing a single FFT. According to the corresponding relationship in the frequency domain, the sampling interval of the object plane in the Fresnel diffraction calculation process is
Therefore, the Fresnel diffraction model generally faces the undersampling problem. The numerical simulations can’t accurately represent the practical reconstructions, as shown in Fig. 5(c). The speckle noise often exists in experiments, which is a common problem of POH that need to be addressed45. According to the reciprocal relationship between the frequency domain range and the spatial sampling interval, the zero-padding to the spectrum is Fourier transferred to the double pixel number and half pixel pitch on the object plane, as shown in Fig. 5(d). Therefore, the Nyquist-Shannon sampling theorem is satisfied without any additional information.
Loss function
The network training process is realized by calculating the loss function between the image dataset and the corresponding output images, and updating the convolution kernel by the Adam optimization algorithm according to the loss46. The negative Pearson correlation coefficient (NPCC) is chosen as the loss function for the 4K-DMDNet. It guarantees linear amplification and bias-free reconstruction, which increases the convergence probability. The NPCC between the input image and output image can be formulated as
Display demonstration of 4K-DMDNet
We verified the feasibility of the proposed 4K-DMDNet by both numerical simulations and optical reconstructions. The training epoch is set as 40 and the distance between the object plane and the hologram plane is 0.3 m. The network is trained and tested with public image datasets, DIV2K_train_HR and DIV2K_valid_HR, respectively. And we use the Matlab Deep Learning Toolbox to realize the network building and training. The trained network model and training code are shown in ref.47. All the algorithms were run on the same workstation with an Intel Xeon Gold 6248R CPU and an NVIDIA Quadro GV100 GPU. Note that the transfer training was employed in our previous Holo-Encoder work for better display effects. In order to more intuitively compare the performance of different algorithms, this method was not used for all the following results.
We first compared the full-color simulations of the POHs generated by the traditional GS algorithm, Holo-Encoder, and the proposed 4K-DMDNet, as shown in Fig. 6(a–c). The test image was selected from the DIV2K_valid_HR dataset, which wasn’t seen by the network before. From the detail views, we can see the GS algorithm faces the speckle noise problem caused by the initial random phase and the amplitude information loss. The contrast of the simulation was low. The Holo-Encoder faces the quality reduction caused by the limited learning capability. The 4K-DMDNet effectively suppressed the above problems and obtained the natural-looking reconstruction. The blurs in Fig. 6(c) are mainly caused by the detailed information loss in the downsampling path. And it can be effectively improved by using other advanced network structures for POH generation. For example, the HRNet maintains high resolution through the whole process, while the U-Net recovers high resolution from low resolution48. Fig. 6(d) shows the PSNR values under different runtimes of the above three algorithms. The GS algorithm achieved a better quality with more iterations and converged to an average quality of 16 dB for above 100 s. However, the 4K-DMDNet broke the trade-off between computation time and reconstruction quality. It can generate the POH in just 0.26 s, with the PSNR of 20.49 dB.
Figure 6.Contrast between the numerical simulations of POHs by (a) the GS algorithm, (b) Holo-Encoder, and (c) 4K-DMDNet. (d) Evaluation of algorithm runtime and image quality. The length of the bar represents the standard deviation of 100 samples (DIV2K_valid_HR).
The experimental setup is shown in Fig. 7(a). A coherent beam was attenuated, expanded, and polarized before illuminating the SLM. A Holoeye GAEA-2 phase-only SLM with the resolution of 3840 × 2160 pixels was employed. The pixel pitch of the SLM was 3.74 μm. The POHs of the target object were uploaded on the SLM. The reconstructed pattern was photographed at the distance of 0.3 m. Color holographic display was realized by time-multiplexing with the 638 nm red, 520 nm green, and 450 nm blue laser sources, as shown in Fig. 7(b). During the time period T, the POHs corresponding to the three channels were loaded onto the SLM in turn. A programmable light switch synchronously controls one of the red, green, and blue lasers that passes through and illuminates the SLM. When the period T is less than the human eye response time, the reconstructed images become a color image. It was high-fidelity and without interference-induced noise, as shown in Fig. 7(c). As to the GS algorithm, since the practical light propagation is not ideal, the speckle noise problem is always magnified on the optical reconstructions. An incoherent Light Emitting Diode (LED) or a partially coherent Self-scanning Light Emitting Device (SLED) source could be employed to reduce the speckle noise. However, the low-coherence light sources also create blurred details and reduced image sharpness. By contrast, in this work, the POHs predicted by the 4K-DMDNet are too smooth to generate the vortex phase. Therefore, compared with the simulations, the optical reconstructions with the laser illumination have no quality degradation and the speckle noise is mostly suppressed.
Figure 7.(a) Photograph of the experimental setup. (b) Schematic diagram of the time multiplexing method for full-color display. (c) Full-color 4K optical reconstruction by 4K-DMDNet and its detail views. (d) Optical reconstruction by GS algorithm. (e) Optical reconstruction by Holo-Encoder.
The 4K-DMDNet learns the latent encodings of POHs in an unsupervised way, which enables a better generalization compared with the data-driven deep learning networks. In the field of two-photon microscopic imaging, optical micromanipulation, and laser nuclear fusion, the patterns with simple shapes and high contrast are widely used. A binary object was experimentally reconstructed to demonstrate the high generalization of the 4K-DMDNet, as shown in Fig. 8. The intensity of the signal part was uniform and the background showed no bottom noise. It is pretty applicable to the head-up display (HUD) and diffractive optical elements (DOEs) design.
Figure 8.(a) Object, (b) POH, and (c) optical reconstruction of the binary target.
The ability to reconstruct 3D scenes of the 4K-DMDNet is presented in Fig. 9. The objects in the scene were at different depths which is indicated by the grayvalue in Fig. 9(b). The 4K-DMDNet could be applied to generate POHs for the layer-oriented objects with the value of the depth. The reconstruction distances were set as 0.28 m, 0.3 m and 0.32 m, respectively. The obvious focusing and defocusing effects can be observed by using a camera.
Figure 9.(a) All-in-focus image of the 3D scene. (b) Depth map of the 3D scene. (c) (d) and (e) Optical reconstructions of the 4K-DMDNet for 3D scene at the 28 cm, 30 cm and 32 cm, respectively. The enlarged views are presented at the right side.
In summary, we propose the 4K-DMDNet model-driven neural network capable of generating high-fidelity 4K computer-generated holograms. The constraint of the reconstructions in the frequency domain is strengthened, which ensures the high-precision optical reconstructions. The sub-pixel convolution method solves the limited learning capability problem which typically appears in the existing hologram generation networks. Compared with the transposed convolution method and NN-resize convolution method, the image quality can be improved to 19.27 dB. Full-color and binary optical reconstructions have been obtained. The display quality outperforms the traditional iterative algorithms and data-driven deep learning algorithms. We believe that our approach further makes the computer-generated holographic display theory to be a viable technology for productive practice.
The current network architecture is based on the universal U-Net. It is suggested that the accurate physical models and smart mapping relations can also be applied to other advanced network architectures, such as generative adversarial network and graph neural network. More efforts will be needed to accelerate the calculation speed in the future. The proposed 4K-DMDNet can also be integrated for laboratory studies such as metasurface design and additive manufacturing. It should be a very powerful algorithm for portable virtual and augmented reality with the rapid development of ASICs. And it provides a versatile CNN framework for the solutions of various ill-posed inverse problems with mass data.
References
[14] He KM, Zhang XY, Ren SQ, Sun J. Deep residual learning for image recognition. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 770–778 (IEEE, 2016);http://doi.org/10.1109/CVPR.2016.90.
[42] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention 234–241 (Springer, 2015);http://doi.org/10.1007/978-3-319-24574-4_28.
[43] Shi WZ, Caballero J, Huszár F, Totz J, Aitken AP et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 1874–1883 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.207.
[44] Dumoulin V, Shlens J, Kudlur M. A learned representation for artistic style. In Proceedings of the 5th International Conference on Learning Representations (IEEE, 2016). https://arxiv.org/abs/1610.07629
[46] Kingma DP, Ba J. Adam: a method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (2014). https://arxiv.org/abs/1412.6980