
Mingjing Yan, Xiyou Su. Hyperspectral Image Classification Based on Three-Dimensional Dilated Convolutional Residual Neural Network[J]. Acta Optica Sinica, 2020, 40(16): 1628002
- Acta Optica Sinica
- Vol. 40, Issue 16, 1628002 (2020)
Abstract
Keywords
1 引言
遥感卫星影像的应用一直都是世界各国重点研究的方向,在各应用方向中,遥感影像分类是其中非常重要的一支。在现阶段,随着空间高分辨率和光谱高分辨率遥感影像的出现,遥感影像分类技术得到了快速发展。高光谱遥感影像的像元可以提供大量的空间维与光谱维信息,从而大大提高了遥感影像分类的精度[
遥感影像的自动分类方法一般可以分为三大类,即监督分类、非监督分类、半监督分类。常用的监督分类方法有Logistic回归(LR)、支持向量机(SVM)、最小距离分类(MDC)、最大似然分类(MLC)[
滕文秀等[
三维结构的高光谱影像通常同时包含空间信息以及丰富的光谱信息。单纯基于光谱特征或基于空间特征的分类方法都不能完全发挥高光谱影像的优势[
2 研究方法
2.1 3D-CNN
CNN最初被用于二维数据的处理与分析,在目标识别、图像分割等方面具有良好的应用效果。但是,传统CNN使用的卷积核通常是二维的,在处理高光谱影像这种三维结构的高维数据时就需要引入大量参数,在处理标注信息较少的高光谱影像时,有可能产生过拟合现象。同时,高光谱遥感影像在空间维也包含有大量信息,2D-CNN的卷积核结构不利于同时提取像元的空间信息与光谱信息[
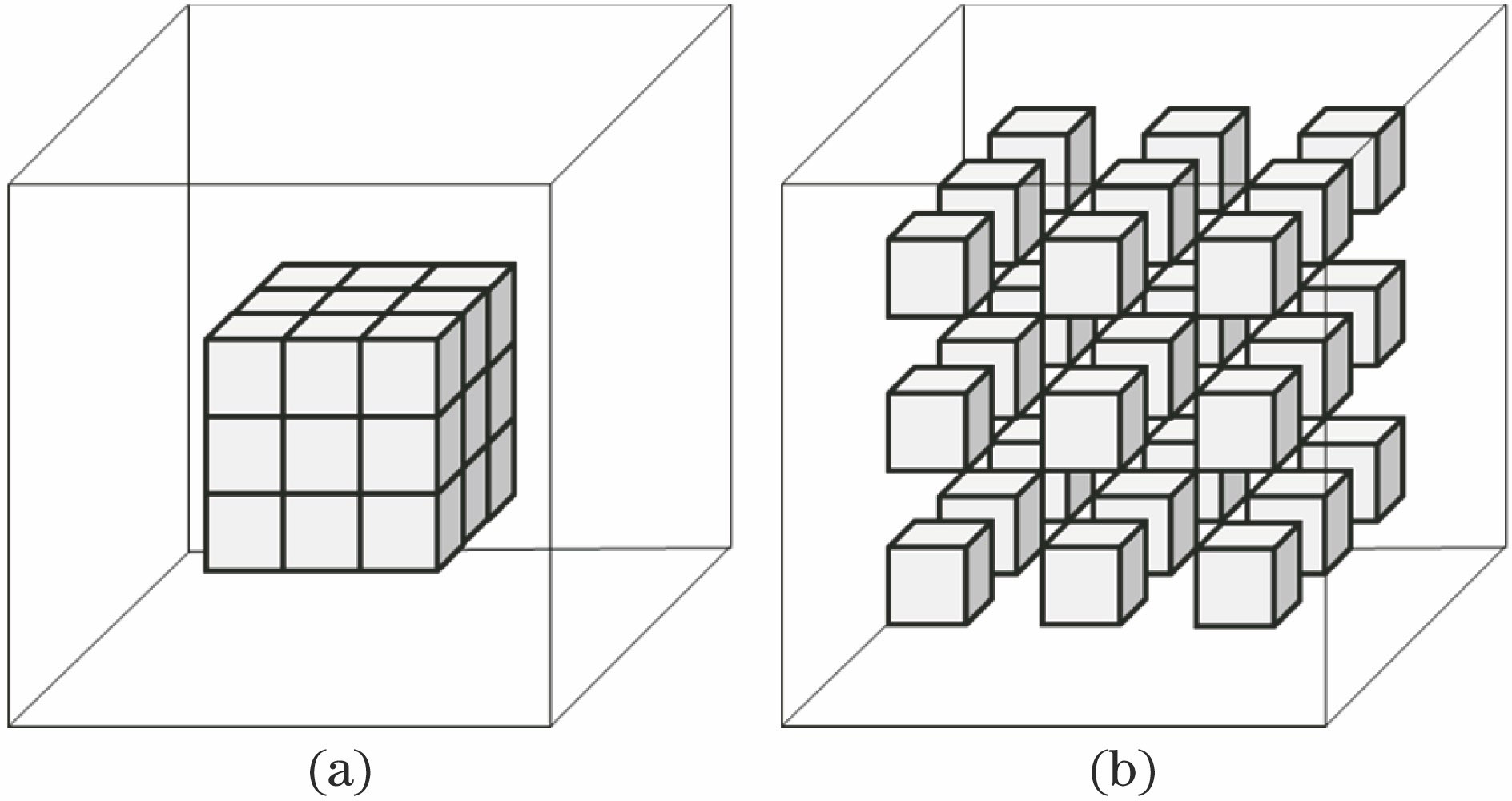
![]()
Figure 1.Two-dimensional and three-dimensional convolution network diagrams. (a) 2D-CNN; (b) 3D-CNN
3D-CNN的卷积核会在三个方向上移动,计算神经网络第i层第j个特征图在(x,y,z)处的点值V的计算公式为
{Invalid MML}
式中:m表示第i-1层中与当前特征图相连的特征图;Li与Wi表示卷积核的长度和宽度;Hi表示卷积核在光谱维度上的尺寸;W代表与i-1层相连的第m个特征图的连接权值;bi,j表示第i层第j个特征图的偏置;f为激活函数。3D-CNN最初由Ji等[
2.2 空洞卷积
对于高光谱影像,线性组合中的两个波段的图层距离通常较远。以植被识别与监测中常用的归一化植被指数(NDVI)为例,在机载可见光/红外成像光谱仪(AVIRIS)高光谱卫星的遥感影像数据中,红色波段(655.56 nm)与近红外波段(819.48 nm)间隔19个图层,需要使用3个以上长度为3的卷积核才能覆盖上述两个图层,进而提取到NDVI特征。若要通过3D-CNN以较少的卷积层数量学习到上述光谱特征,则需要扩大卷积层的感受野。扩大感受野的常用方法是扩大卷积核或添加池化层(pooling),虽然较大的三维卷积核有利于神经网络获取更多的光谱上下文信息,但会增加网络的计算负荷,而使用池化层则会牺牲一部分特征。在此情况下,引入空洞卷积层替代传统池化层,可以在减少数据损失的同时扩大卷积层的感受野[
空洞卷积在原始卷积核的基础上,通过在值与值之间插入权重为0的行与列来扩大卷积核的感受野,如
![]()
Figure 2.Normal and dilated convolution kernel diagrams. (a) Normal kernel; (b) dilated kernel (r=2)
2.3 残差结构
与浅层神经网络相比,深层CNN具有更多的非线性映射结构,可完成结构复杂的函数逼近,获得的特征更加抽象,提取到的语义信息更加完整,适合处理数据量大的高光谱影像数据[
残差结构最大的特点就是采用跳层连接,这使得其相较于普通神经网络具有更好的学习性能。残差模块输入与输出的关系可以表示为
{Invalid MML}
式中:H(x)表示计算结果;x表示模块输入;f(x)表示残差学习函数。残差结构可根据具体需要对f(x)进行相应的改变,可将(2)式扩充为
{Invalid MML}
式中:x与y分别对应残差模块的输入与输出;f(x,{Wi})表示待训练的残差映射,输入x和残差映射f的维度需保持一致。在省略偏差的情况下,可将残差映射写成f(x,{Wi})=W2σ(W1x),其中σ为激活函数,在这里表示ReLU激活函数。
若输入x和残差映射f的维度不一致,则需要在跳层连接上增加一个线性投影Ws来使维度相同,即
{Invalid MML}
在残差模块训练过程中,输出是由输入与其矩阵变化的结果相加得到的,并未引入新的参数,网络的参数量不会变化,在不影响反向传播过程的同时能够加快模型的训练速度并提高训练效果。
3 网络结构与参数分析
3.1 网络结构
普通的CNN通常适用于二维平面数据,在处理高光谱影像这种高维数据时,不能很好地同时提取到空间维和光谱维特征。针对此问题,本文提出了一种包含空洞卷积层和残差连接的3D-CNN,用它对高光谱影像进行地物分类。进入神经网络后,在网络前段进行浅层特征提取,并去除部分噪声,在网络中段进行深度特征的提取,提取出深度特征后,在网络后段降低数据量和进一步去除噪声,最终使用Softmax分类器完成像元块数据的地物分类。
残差特征学习部分包含两个空洞卷积结构块,每个结构块包含3个卷积层。为深入探讨空洞卷积层对神经网络的影响,本文从感受野覆盖范围和形式以及累加线性特征进行非线性处理两方面进行研究。本文假设了如
![]()
Figure 3.Seven permutation and combination types of dilated and normal convolutional layers and two activation function distribution strategies. (a) Type 1; (b) type 2; (c) type 3; (d) type 4; (e) type 5; (f) type 6; (g) type 7; (h) distribution strategy Ⅰ; (i) distribution strategy Ⅱ
不同空洞卷积结构块在训练时均采用相同的训练参数和训练集,并选用总体精度(OA)、平均精度(AA)和Kappa系数 (Kappa)作为模型精度的评价指标。
| Structure type | Indian Pines | Salinas | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Kappa | OA | AA | OA-mean | Kappa | OA | AA | OA-mean | ||||
| Type 1-Ⅰ | 95.852 | 96.976 | 92.041 | 96.942 | 95.797 | 96.986 | 94.524 | 96.823 | |||
| Type 2-Ⅰ | 95.676 | 96.851 | 91.499 | 95.534 | 96.794 | 94.748 | |||||
| Type 3-Ⅰ | 95.885 | 97.000 | 91.383 | 95.388 | 96.690 | 94.694 | |||||
| Type 4-Ⅰ | 95.155 | 96.480 | 90.501 | 96.505 | 95.862 | 97.028 | 95.027 | 96.943 | |||
| Type 5-Ⅰ | 94.811 | 96.232 | 89.872 | 95.808 | 96.991 | 94.772 | |||||
| Type 6-Ⅰ | 95.609 | 96.801 | 91.559 | 95.554 | 96.810 | 94.666 | |||||
| Type 7-Ⅰ | 95.680 | 96.855 | 91.335 | 96.855 | 95.320 | 96.644 | 94.192 | 96.644 | |||
Table 1.
由
虽然空洞卷积结构能够扩大卷积层的感受野,但是单纯增加空洞卷积层的效果并不能取得最优的感受野分布效果。由
| Structure type | Indian Pines | Salinas | ||||||
|---|---|---|---|---|---|---|---|---|
| Kappa | OA | AA | OA-mean | Kappa | OA | AA | OA-mean | |
| Type 1-Ⅱ | 95.976 | 97.066 | 91.912 | 96.973 | 95.804 | 96.989 | 94.793 | 96.944 |
| Type 2-Ⅱ | 95.698 | 96.866 | 91.800 | 95.883 | 97.045 | 94.903 | ||
| Type 3-Ⅱ | 95.866 | 96.987 | 91.956 | 95.532 | 96.796 | 94.432 | ||
| Type 4-Ⅱ | 95.775 | 96.921 | 91.839 | 96.689 | 95.455 | 96.741 | 94.262 | 96.856 |
| Type 5-Ⅱ | 94.798 | 96.220 | 90.179 | 95.718 | 96.928 | 94.737 | ||
| Type 6-Ⅱ | 95.783 | 96.927 | 91.543 | 95.676 | 96.898 | 94.682 | ||
| Type 7-Ⅱ | 95.618 | 96.808 | 91.351 | 96.808 | 95.457 | 96.739 | 94.568 | 96.739 |
Table 2.
![]()
Figure 4.Receptive field's distributions of different convolution combinations. (a) Dilation parameter distribution is (2,2,2); (b) dilation parameter distribution is (1,2,2); (c) dilation parameter distribution is (1,1,2)
综合比较
![]()
Figure 5.Network structure
该网络分为三个主体部分:part 1包含2个卷积核大小为3×3×7、通道数为16的3D卷积层,其中1个为空洞卷积层;part 2包含8个卷积核大小为3×3×3、通道数分别为32和48的3D卷积层,其中有5个为空洞3D卷积层;part 3包含2个Maxpooling层,2个卷积核大小为3×3×5、通道数为24的3D卷积层,以及2个卷积核大小3×3×3、通道数为16的3D卷积层,所有卷积层的卷积模式均为same,并在归一化之后使用ReLU函数进行激活。在数据通过神经网络后,为避免过拟合,在结果分类前添加参数为0.4的Dropout层,最终的分类由全连接层和Softmax分类器完成。
本网络输入的数据为7×7×N的像元块,N为像元块的光谱维长度,数据标签为像元块空间几何中心像元所属的地类。为模拟实际的应用场景,训练数据集和验证数据集中均混入了未进行地物类别标注的背景像元,训练集和验证集的像元数量均为总像元数量的50%,训练集中包含20%的已标记地物类别的像元,验证集中包含80%的已标记地物类别的像元。
实验总流程可以分为训练网络和验证网络两大部分,训练网络包含制作训练数据和训练神经网络两部分。在训练网络阶段,首先在原图像中按比例抽取已标记和未标记的高光谱像元立方体,进行随机混序排列,然后将它们依次输入到网络模型中进行特征提取,最终使用Softmax分类器进行分类。在验证网络阶段,先将验证数据依次输入到已训练好的网络模型中,提取出分类特征,采用Softmax分类器进行分类预测,然后使用精度评价指标验证网络的有效性。
3.2 参数设置与分析
在空洞CNN中,膨胀系数(dilation rate)是一个很重要的参数,代表卷积核中有效行列之间不参与计算的行和列的个数。扩大因子增大会使卷积核的覆盖范围变大,从而扩大感受野,使卷积层能够学习到更广的特征,但也会使一部分细节信息被忽视掉。
在实验中,选取2~7共6个扩大因子,对其影响进行分析。考虑到数据集中各地类的像元数量极不平衡,最终选用OA、AA和Kappa系数作为模型精度的评价指标,其中,OA表征对总体分类结果的评价,AA表征各类别自身分类精度的均值,Kappa系数表征模型分类结果与参考结果的一致程度。空洞卷积层中不同膨胀系数对应的精度结果如
![]()
Figure 6.Corresponding precision of dilation rate in two datasets. (a) Indian Pines spectral dimension; (b) Salinas spectral dimension; (c) Indian Pines spatial dimension; (d) Salinas spatial dimension
实验结果表明:在空间维,空洞参数虽然可以发挥一定作用,但当空洞参数超过2之后,空间维空洞结构的增大反而会带来负面影响,即卷积核尺寸大于数据块的空间维尺寸,影响分类精度;在光谱维,空洞参数与总体精度OA之间不是线性关系,随着空洞参数增大,总体精度OA先小幅下降再上升,然后再下降。当空洞参数开始增大时,卷积层感受野扩张范围不足,同时特征损失增加,导致总体精度OA下降;当空洞结构增大到一定范围时,感受野的扩张使卷积层能学习到更多的特征,从而弥补了空洞结构所导致的特征损失,使分类精度AA升高;随着空洞参数继续增大,由于光谱维数据有限,感受野的增大并不能学习到更多的特征,而空洞结构的特征损失继续增大,从而导致分类精度AA再次下降。综合两个数据集的实验结果,本文选取光谱维为4、空间维为2的空洞参数。
4 实验结果与分析
为评价本文所提神经网络结构的分类效果,选取Indian Pines以及Salinas两个典型的高光谱遥感数据集进行地物分类实验。
Indian Pines数据集是由AVIRIS于1992年对美国印第安纳州一块实验地进行成像得到的遥感图像,空间分辨率为20 m,包含145×145个地物像素和224个光谱通道,去掉水分吸收较强的光谱通道(第104~108通道,第150~163通道,第220通道)后,共有200个光谱通道可用于分类。该数据集包含16个地物类别和1个背景类别,其中包含10249个已标记地物类别的像元和10776个背景像元。
Salinas数据集是由AVIRIS于1998年对美国加利福尼亚州的Salinas山谷进行成像的遥感图像,空间分辨率为3.7 m,包含512×217个地物像素和224个光谱通道,去掉水分吸收较强的光谱通道(第108~112通道,第154~167通道,第224通道)后,共有200个光谱通道可用于分类。该数据集包含16个地物类别和1个背景类别,其中包含54129个已标记地物类别的像元和56975个背景像元。
![]()
Figure 7.Pseudo-color composite images of two datasets. (a) Indian Pines; (b) Salinas
| Class name | Classification accuracy | |||||
|---|---|---|---|---|---|---|
| SVM | 2D-CNN | Res-3DCNN | M3D-DCNN | 3D-CNN | Dilated-3D-CNN | |
| Background | 69.123 | 98.797 | 98.406 | 99.240 | 99.376 | 99.653 |
| Alfalfa | 24.348 | 52.174 | 73.587 | 69.130 | 82.065 | 82.065 |
| Corn-notill | 61.583 | 85.007 | 84.352 | 88.235 | 93.092 | 94.492 |
| Corn-mintill | 40.126 | 80.624 | 86.640 | 89.329 | 92.948 | 94.555 |
| Corn | 29.473 | 77.426 | 84.325 | 88.270 | 93.418 | 92.806 |
| Grass-pasture | 73.113 | 83.013 | 83.046 | 86.115 | 90.971 | 91.766 |
| Grass-trees | 75.993 | 89.370 | 89.411 | 92.493 | 94.945 | 96.075 |
| Grass-pasture-mowed | 23.750 | 58.036 | 70.893 | 70.714 | 78.750 | 81.786 |
| Hay-windrowed | 85.471 | 97.406 | 97.416 | 97.699 | 98.180 | 98.441 |
| Oats | 22.750 | 49.250 | 47.000 | 72.000 | 75.250 | 87.000 |
| Soybean-notill | 55.710 | 84.767 | 84.268 | 88.971 | 93.897 | 95.307 |
| Soybean-mintill | 71.536 | 91.440 | 89.668 | 93.733 | 96.449 | 97.132 |
| Soybean-clean | 40.780 | 72.686 | 75.941 | 86.169 | 89.771 | 92.119 |
| Wheat | 84.293 | 93.317 | 94.756 | 95.683 | 96.585 | 97.390 |
| Woods | 55.486 | 86.644 | 86.067 | 92.518 | 95.636 | 95.945 |
| Buildings-Grass-Trees-Drives | 28.455 | 58.503 | 63.965 | 77.532 | 87.946 | 90.303 |
| Stone-Steel-Towers | 33.441 | 77.796 | 81.667 | 86.237 | 90.860 | 89.570 |
| Kappa | 54.791 | 88.317 | 88.514 | 92.541 | 95.377 | 96.304 |
| OA | 64.636 | 91.721 | 91.820 | 94.622 | 96.634 | 97.303 |
| AA | 51.496 | 78.603 | 81.848 | 86.710 | 91.185 | 92.730 |
Table 3.
| Class name | Classification accuracy | |||||
|---|---|---|---|---|---|---|
| SVM | 2D-CNN | Res-3DCNN | M3D-DCNN | 3D-CNN | Dilated-3D-CNN | |
| Background | 70.502 | 98.295 | 98.365 | 98.491 | 98.672 | 98.806 |
| Brocoli-green-weeds-1 | 94.556 | 95.768 | 91.594 | 86.573 | 95.888 | 96.374 |
| Brocoli-green-weeds-2 | 95.456 | 98.332 | 97.772 | 98.552 | 98.355 | 98.395 |
| Fallow | 44.098 | 86.180 | 73.336 | 86.282 | 89.653 | 90.567 |
| Fallow-rough-plow | 60.740 | 82.123 | 80.289 | 86.596 | 88.238 | 90.585 |
| Fallow-smooth | 47.043 | 87.957 | 87.580 | 89.402 | 91.423 | 91.356 |
| Stubble | 98.964 | 96.419 | 95.926 | 87.176 | 96.583 | 96.638 |
| Celery | 91.562 | 96.462 | 96.159 | 97.399 | 97.122 | 97.837 |
| Grapes-untrained | 83.636 | 92.165 | 92.618 | 93.300 | 95.896 | 96.643 |
| Soil-vinyard-develop | 64.362 | 93.482 | 92.085 | 93.865 | 95.142 | 96.079 |
| Corn-senesced-green-weeds | 79.297 | 92.466 | 90.876 | 92.527 | 95.597 | 95.165 |
| Lettuce-romaine-4wk | 71.196 | 94.180 | 93.153 | 94.094 | 95.781 | 95.058 |
| Lettuce-romaine-5wk | 31.651 | 95.916 | 90.497 | 94.714 | 97.738 | 98.093 |
| Lettuce-romaine-6wk | 22.858 | 86.096 | 71.331 | 90.291 | 91.745 | 92.651 |
| Lettuce-romaine-7wk | 52.255 | 86.670 | 83.944 | 88.426 | 89.789 | 90.792 |
| Vinyard-untrained | 38.987 | 85.982 | 83.519 | 87.330 | 93.218 | 95.129 |
| Vinyard-vertical-trellis | 97.662 | 95.990 | 96.006 | 96.231 | 96.068 | 96.388 |
| Kappa | 61.951 | 93.267 | 92.013 | 93.226 | 95.567 | 96.149 |
| OA | 70.697 | 95.185 | 94.324 | 95.178 | 96.820 | 97.236 |
| AA | 67.343 | 92.028 | 89.121 | 91.838 | 94.524 | 95.091 |
Table 4.
实验所用的计算机配置为Intel(R) Core(TM) i7-7700HQ CPU,NVIDIA GeForce GTX 1070,16 GB内存,在Windows 10系统下基于Python 3.71的Keras框架实现。实验数据使用主成分分析(PCA)法进行预处理,在保留99.9%原始特征的条件下对光谱维进行压缩。在网络中使用Adam优化器进行网络训练,初始学习率为0.001,设置损失函数的稳定容忍值为4,每次触发使学习率降低到其当前值的1/10。网络各卷积层采用He normal[
为验证本文提出的网络模型的有效性,选取了5个网络模型对照组,包括经典的SVM分类算法、相同网络层次结构的2D-CNN、Res-3DCNN[
由
![]()
Figure 8.Classification images of different network models in Indian Pines dataset. (a) True value image; (b) SVM; (c) 2D-CNN; (d) Res-3DCNN; (e) M3D-DCNN; (f) 3D-CNN; (g) Dilated-3D-CNN
![]()
Figure 9.Classification images of different network models in Salinas dataset. (a) True value image; (b) SVM; (c) 2D-CNN; (d) Res-3DCNN; (e) M3D-DCNN; (f) 3D-CNN; (g) Dilated-3D-CNN
5 结论
本文研究了CNN在高光谱影像分类中的应用,设计了一种基于三维空洞卷积残差神经网络的分类模型Dilated-3D-CNN,该模型通过在网络中引入空洞结构来扩大卷积层的感受野,提高地物分类的精度。在Indian Pines和Salinas数据集上,将本文所提网络模型与其他5种网络模型进行对比,结果表明,本文设计的网络模型具有最好的分类性能,这说明合适的空洞结构可以在网络参数量不变的基础上提高分类精度。
基于三维空洞卷积残差神经网络的高光谱影像分类方法可以很好地同时提取空间维特征和光谱维特征,为处理三维高光谱影像数据提供了新思路。在实际应用中,由于现有神经网络程序框架的优化问题,空洞结构仍会给网络带来一定负担。随着框架的优化与发展,三维卷积层和空洞结构将在高光谱影像分类领域具有更大的潜力,如何使用二者来提高分类精度和效率还需要进一步研究。
References
[1] Meher S K. Semisupervised self-learning granular neural networks for remote sensing image classification[J]. Applied Soft Computing, 83, 105655(2019).
[2] Li Y F, Lin H. Multi-spectral remote sensing image classification of ground coverage based on CNN[J]. Microprocessors, 40, 43-48(2019).
[3] Liu P. Choo K K R, Wang L Z, et al. SVM or deep learning? A comparative study on remote sensing image classification[J]. Soft Computing, 21, 7053-7065(2017).
[4] Zhao C X, Qian L X. Comparative study of supervised and unsupervised classification in remote sensing image[J]. Journal of Henan University (Natural Science Edition), 34, 90-93(2004).
[5] Cao L L, Li H T, Han Y S et al. Application of convolutional neural networks in classification of high resolution remote sensing imagery[J]. Science of Surveying and Mapping, 41, 170-175(2016).
[7] Zhong Z L, Li J, Luo Z M et al. Spectral-spatial residual network for hyperspectral image classification: a 3-D deep learning framework[J]. IEEE Transactions on Geoscience and Remote Sensing, 56, 847-858(2018).
[8] Mou L C, Ghamisi P, Zhu X X. Deep recurrent neural networks for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 55, 3639-3655(2017).
[9] Dai X Y, Xue W. Hyperspectral remote sensing image classification based on convolutional neural network[C]∥37th Chinese Control Conference., 10373-10377(2018).
[10] Wolterink J M, Leiner T, Viergever M A et al[M]. Dilated convolutional neural networks for cardiovascular MR segmentation in congenital heart disease, 95-102(2017).
[11] Zhang H K, Li Y, Jiang Y N. Deep learning for hyperspectral imagery classification: the state of the art and prospects[J]. Acta Automatica Sinica, 44, 961-977(2018).
[14] Sun Z J, Xue L, Xu Y M et al. Overview of deep learning[J]. Application Research of Computers, 29, 2806-2810(2012).
[15] He K M, Zhang X Y, Ren S Q et al. Deep residual learning for image recognition[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 27-30 June 2016, Las Vegas, NV, USA., 770-778(2016).
[16] He KM, Zhang XY, Ren SQ, et al.Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]∥2015 IEEE International Conference on Computer Vision (ICCV). 7-13 Dec. 2015, Santiago, Chile. New York: IEEE Press, 2015: 1026- 1034.
[17] Ding J, Chen S T. Hyper-spectral remote sensing image classification based on residual 3D convolutional neural network[J]. Laser Journal, 40, 45-52(2019).
[18] He M Y, Li B, Chen H H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification[C]∥2017 IEEE International Conference on Image Processing (ICIP). 17-20 Sept. 2017, Beijing, China., 3904-3908(2017).

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20