[1] Buri M, Pobar M, Kos M I. An overview of action recognition in videos. [C]∥2017 40th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), May 22-26, 2017, Opatija, Croatia. New York: IEEE, 1098-1103(2017).
[2] Luo H L, Wang C J, Lu F. Survey of video behavior recognition[J]. Journal on Communications, 39, 169-180(2018).
[3] Willems G. Tuytelaars T, van Gool L. An efficient dense and scale-invariant spatio-temporal interest point detector[M]. ∥Forsyth D, Torr P, Zisserman A. Computer vision-ECCV 2008. Lecture notes in computer science. Berlin, Heidelberg: Springer, 5303, 650-663(2008).
[4] Rapantzikos K, Avrithis Y, Kollias S. Dense saliency-based spatiotemporal feature points for action recognition. [C]∥2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 20-25, 2009, Miami, FL, USA. New York: IEEE, 1454-1461(2009).
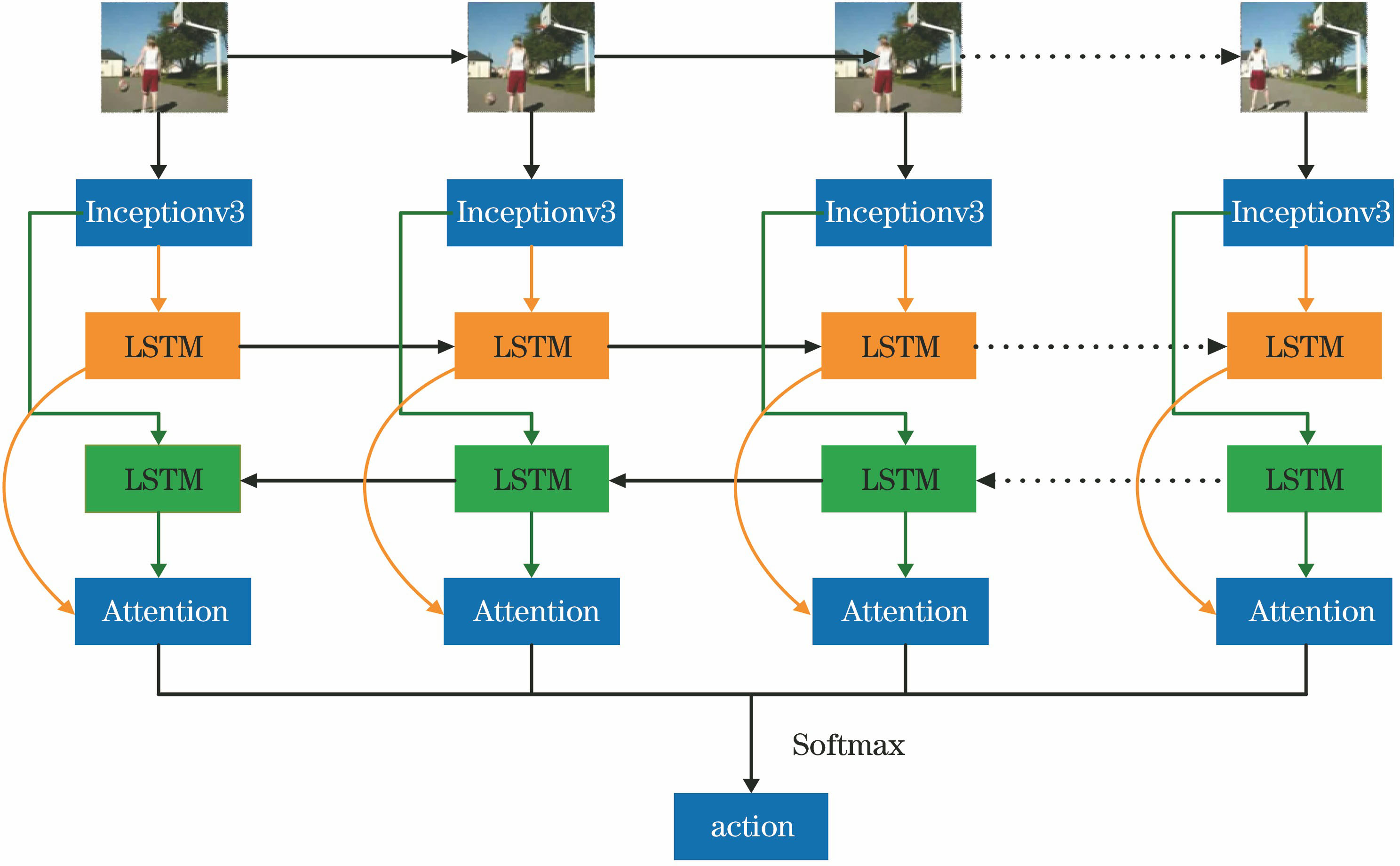
[12] Donahue J, Hendricks L A, Guadarrama S et al. Long-term recurrent convolutional networks for visual recognition and description. [C]∥2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 7-12, 2015, Boston, MA, USA. New York: IEEE, 2625-2634(2015).
[13] Gammulle H, Denman S, Sridharan S et al. Two stream LSTM: a deep fusion framework for human action recognition. [C]∥2017 IEEE Winter Conference on Applications of Computer Vision (WACV), March 24-31, 2017, Santa Rosa, CA, USA. New York: IEEE, 177-186(2017).
[15] Das S, Koperski M, Bremond F et al. Deep-temporal LSTM for daily living action recognition. [C]∥2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance(AVSS), November 27-30, 2018, Auckland, New Zealand. New York: IEEE, 18455900(2018).
[17] Szegedy C, Vanhoucke V, Ioffe S et al. Rethinking the inception architecture for computer vision. [C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 27-30, 2016, Las Vegas, NV, USA. New York: IEEE, 2818-2826(2016).
[18] Ravanbakhsh M, Mousavi H, Rastegari M et al. -12-13)[2019-01-02]. https:∥arxiv., org/abs/1512, 03980(2015).
[19] Yang X D, Tian Y L. Action recognition using super sparse coding vector with spatio-temporal awareness[M]. ∥Fleet D, Pajdla T, Schiele B,
[20] Wang J, Liu Z C, Wu Y et al. Mining actionlet ensemble for action recognition with depth cameras. [C]∥2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 16-21, 2012, Providence, RI, USA. New York: IEEE, 1290-1297(2012).
[21] Peng X J, Zou C Q, Qiao Y et al. Action recognition with stacked fisher vectors[M]. ∥Fleet D, Pajdla T, Schiele B,
[23] Sun L, Jia K, Chan T H et al. DL-SFA: deeply-learned slow feature analysis for action recognition. [C]∥2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 23-28, 2014, Columbus, OH, USA. New York: IEEE, 2625-2632(2014).