Author Affiliations
1 Key Laboratory of Advanced Process Control for Light Industry (Ministry of Education) Jiangnan University, Wuxi Jiangsu 214122, China2 School of Internet of Things Engineering, Jiangnan University, Wuxi, Jiangsu 214122, Chinashow less
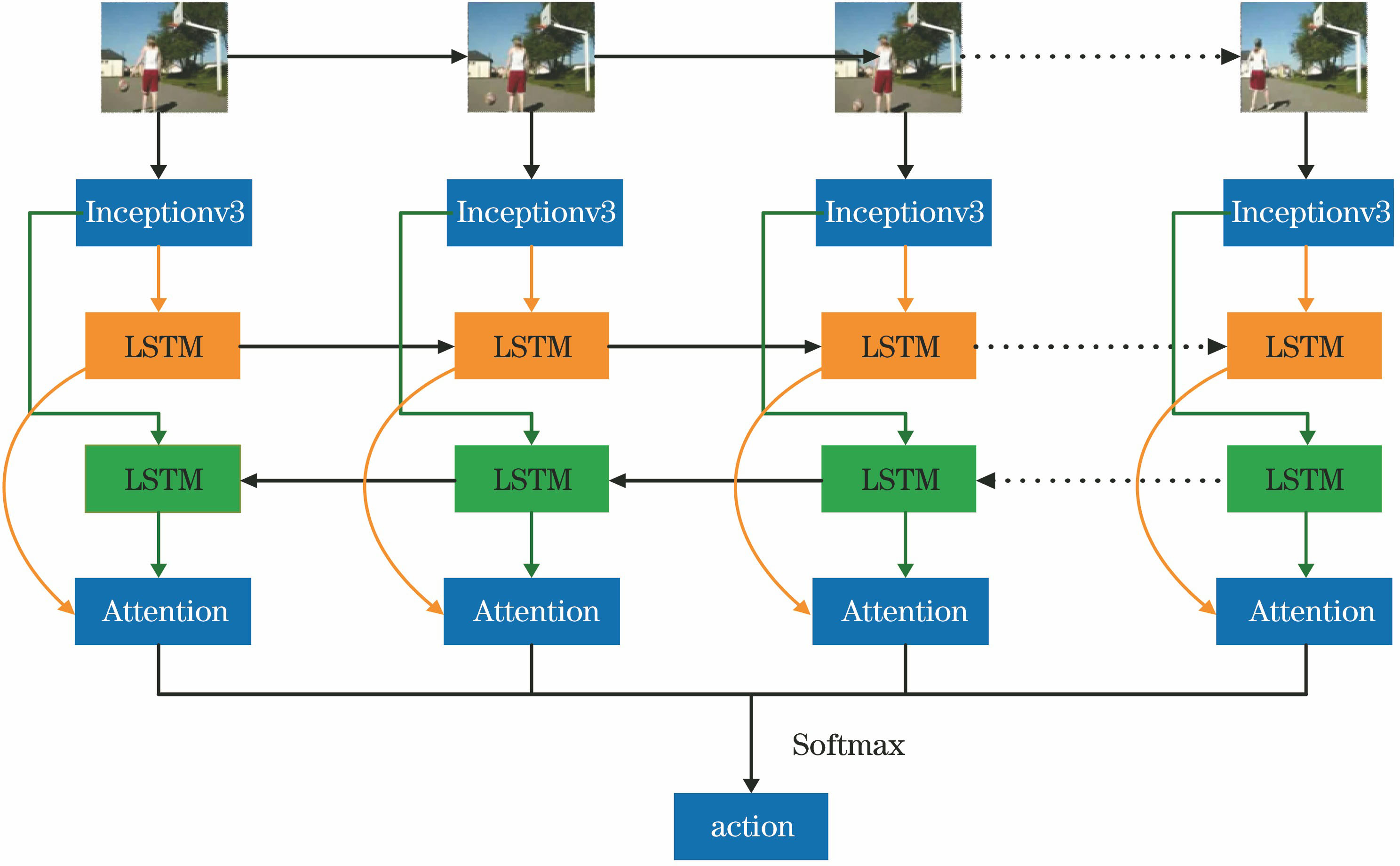
Fig. 1. Action recognition framework based on Bi-LSTM-Attention model
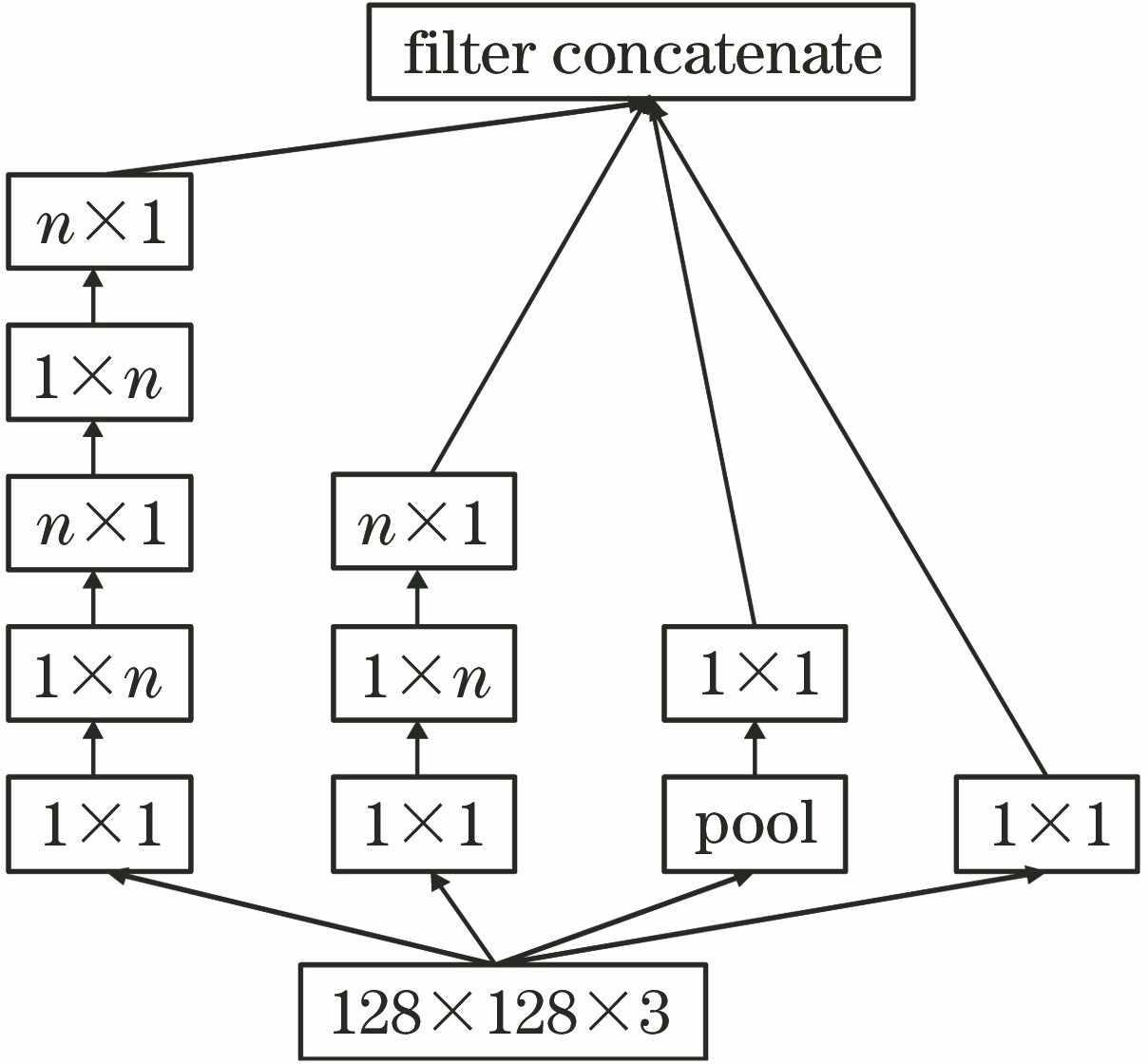
Fig. 2. Partial structural diagram of Inceptionv3
Fig. 3. LSTM cell structure
Fig. 4. Bi-LSTM network model
Fig. 5. Attention mechanism model
Fig. 6. Comparison of video frames before and after adding noise to pictures. (a) Original video frames; (b) noise video frames with σ=0.2; (c) noise video frames with σ=0.4
Fig. 7. Thermodynamic charts of feature regions
| Parameter | Value |
|---|
| Loss function | Categorical_crossentropy | | Optimizer | Adam | | Learning rate | 0.0001 | | Batch_size | 16 | | Epoch | 100 |
|
Table 1. Experimental parameters
| Dataset | Training | Validation | Test | Cross validation |
|---|
| Action Youtobe | 960 | 320 | 320 | 0 | | KTH | 480 | 0 | 120 | 5 |
|
Table 2. Dataset division
| Category | Basketball | Biking | Diving | G-swing | H-riding | Soccer | Swing | Tennis | Jumping | Volleyball | Walking |
|---|
| Basketball | 96.30 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.7 | 0 | | Biking | 10.52 | 89.48 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | Diving | 0 | 0 | 100.00 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | G-swing | 0 | 0 | 0 | 96.67 | 0 | 0 | 3.33 | 0 | 0 | 0 | 0 | | H-riding | 0 | 0 | 2.08 | 0 | 95.84 | 0 | 0 | 0 | 2.08 | 0 | 0 | | Soccer | 0 | 0 | 0 | 12.12 | 0 | 87.88 | 0 | 0 | 0 | 0 | 0 | | Swing | 0 | 0 | 0 | 0 | 0 | 0 | 96.55 | 0 | 0 | 3.45 | 0 | | Tennis | 3.70 | 0 | 0 | 0 | 0 | 0 | 0 | 96.30 | 0 | 0 | 0 | | Jumping | 4.35 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 95.65 | 0 | 0 | | Volleyball | 0 | 0 | 9.52 | 0 | 0 | 0 | 0 | 0 | 0 | 90.48 | 0 | | Walking | 0 | 0 | 0 | 3.84 | 0 | 3.84 | 0 | 0 | 0 | 3.84 | 88.48 |
|
Table 3. Action recognition confusion matrix of Action Youtobe dataset%
| Algorithm | Accuracy | Memory occupancy | Accuracy (0.2) | Accuracy (0.4) |
|---|
| Binary CNN-Flow[18] | 84.30 | 46 | 77.32 | 70.68 | | 3D spatio-temporal[19] | 88.00 | - | - | - | | Hierarchical clustering multi-task[7] | 89.70 | 53 | 84.40 | 78.60 | | Deep-Temporal LSTM[15] | 90.27 | 46 | 87.56 | 83.28 | | Discriminative representation[20] | 91.60 | - | - | - | | Proposed DB-LSTM[16] | 92.84 | 42 | 89.15 | 82.37 | | Fisher vectors[21] | 93.80 | - | - | - | | Inceptionv3 + LSTM | 89.53 | 31 | 83.54 | 76.54 | | Inceptionv3 + Bi-LSTM | 92.81 | 33 | 88.38 | 82.82 | | Inceptionv3+ Bi-LSTM-Attention | 94.38 | 37 | 92.56 | 89.24 |
|
Table 4. Comparison of proposed algorithm and other model algorithms on Action Youtobe dataset%
| Algorithm | Dataset1 | Dataset2 | Dataset3 | Dataset4 | Dataset5 | Average |
|---|
| Inception v3 +LSTM | 97.50 | 82.50 | 97.50 | 86.67 | 87.50 | 90.33 | | Inception v3 +Bi-LSTM | 99.17 | 87.50 | 100.00 | 93.33 | 93.33 | 94.67 | | Inception v3+Bi-LSTM-attention | 100.00 | 89.17 | 100.00 | 95.00 | 94.17 | 95.67 |
|
Table 5. Accuracy comparison of cross validation for KTH dataset%
| Action | Boxing | Handclapping | Handwaving | Jogging | Running | Walking |
|---|
| Boxing | 99 | 0 | 0 | 0 | 0 | 1 | | Handclapping | 0 | 97 | 3 | 0 | 0 | 0 | | Handwaving | 0 | 3 | 97 | 0 | 0 | 0 | | Jogging | 0 | 0 | 0 | 96 | 4 | 0 | | Running | 0 | 0 | 0 | 5 | 93 | 2 | | Walking | 0 | 0 | 0 | 4 | 4 | 92 |
|
Table 6. Action recognition confusion matrix of KTH dataset
| Algorithm | Accuracy | Memory occupancy | Accuracy (0.2) | Accuracy (0.4) |
|---|
| 3D CNN[11] | 90.20 | 62 | 87.20 | 81.80 | | Spatio-temporal[6] | 92.10 | - | - | - | | D-M and S-P feauters[22] | 92.70 | - | - | - | | D-L slow feature[23] | 93.10 | 58 | 0.80 | 85.40 | | Deep-Temporal LSTM[15] | 93.90 | 46 | 90.10 | 84.60 | | CNN-LSTM[24] | 94.20 | - | - | - | | Hierarchical clustering multi-task[7] | 94.30 | 53 | 90.60 | 84.30 | | Inceptionv3 + Bi-LSTM-Attention | 95.67 | 37 | 93.80 | 90.27 |
|
Table 7. Comparison of proposed algorithm and other model algorithms on KTH dataset%