[1] Girshick R, Donahue J, Darrell T et al. Rich feature hierarchies for accurate object detection and semantic segmentation. [C]∥IEEE Conference on Computer Vision and Pattern Recognition, 580-587(2014).
[2] Girshick R. Fast R-CNN. [C]∥IEEE International Conference on Computer Vision (ICCV), 1440-1448(2015).
[4] DaiJ, LiY, HeK, et al. R-FCN: object detection via region-based fully convolutional networks[J]. arXiv preprint arXiv:1605.06409, 2016.
[5] Redmon J, Divvala S, Girshick R et al. You only look once: unified, real-time object detection. [C]∥ IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779-788(2016).
[6] Redmon J, Farhadi A. YOLO9000: better, faster, stronger. [C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517-6525(2017).
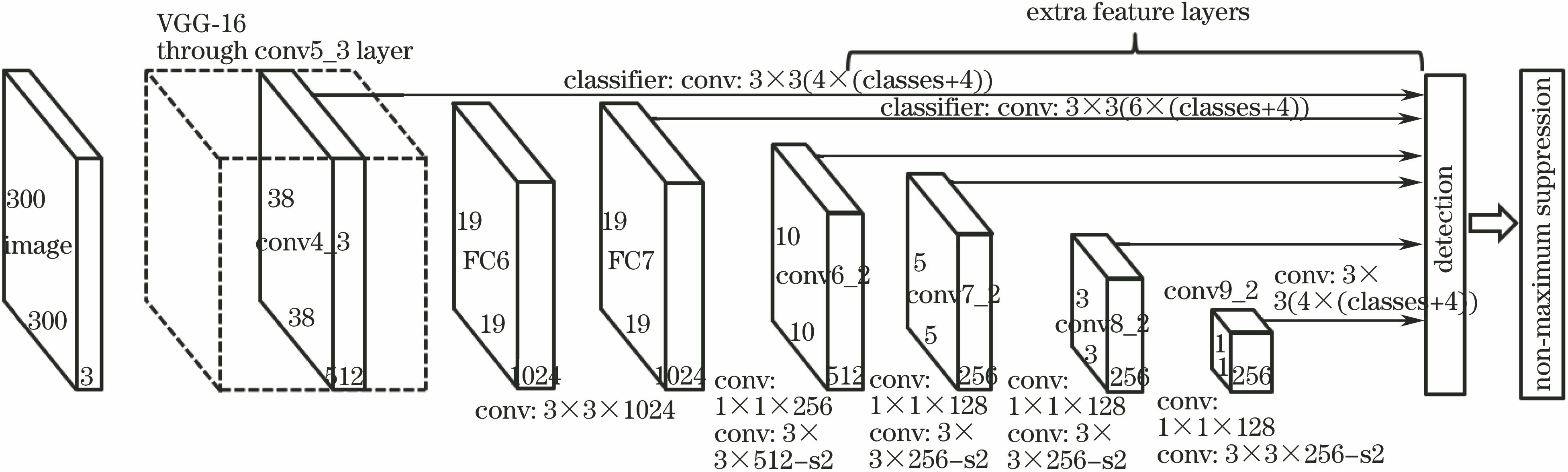
[7] Liu W, Anguelov D, Erhan D et al. SSD:single shot multibox detector. [C]∥European Conference on Computer Vision, 21-37(2016).
[8] Dalal N, Triggs B. Histograms of oriented gradients for Human detection. [C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), 886-893(2005).
[10] Felzenszwalb P. McAllester D, Ramanan D. A discriminatively trained, multiscale, deformable part model. [C]∥IEEE Conference on Computer Vision and Pattern Recognition, 1-8(2008).
[11] Azizpour H, Laptev I. Object detection using strongly-supervised deformable part models. [C]∥ European Conference on Computer Vision, 836-849(2014).
[15] Cai Z, Vasconcelos N. Cascade R-CNN: delving into high quality object detection. [C]∥Computer Vision and Pattern Recognition, 6154-6162(2018).
[19] Redmon J, Farhadi A. YOLOv3: an incremental improvement. [C]∥Computer Vision and Pattern Recognition(2018).
[20] Lin T Y, Goyal P, Girshick R et al. Focal loss for dense object detection. [C]∥IEEE International Conference on Computer Vision (ICCV), 2999-3007(2017).
[21] Fu C Y, Liu W, Ranga A et al. DSSD: deconvolutional single shot detector. [C]∥Computer Vision and Pattern Recognition(2017).
[23] Jeong J, Park H, Kwak N. Enhancement of SSD by concatenating feature maps for object detection. [C]∥ British Machine Vision Conference(2017).
[24] Hosang J, Benenson R, Schiele B. A convnet for non-maximum suppression. [C]∥German Conference on Pattern Recognition, 192-204(2016).
[25] Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining. [C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 761-769(2016).
[26] Jia Y Q, Shelhamer E, Donahue J et al. Caffe. [C]∥Proceedings of the ACM International Conference on Multimedia(2014).
[27] Simonyan K[J]. Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv preprint arXiv, 1556, 2014(1409).
[28] He K M, Zhang X Y, Ren S Q et al. Deep residual learning for image recognition. [C]∥ IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778(2016).
[29] Huang G, Liu Z. Maaten L V D, et al. Densely connected convolutional networks. [C]∥ IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2261-2269(2017).
[30] Zhang X, Zhou X, Lin M et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices. [C]∥ Computer Vision and Pattern Recognition(2018).
[31] Sandler M, Howard A, Zhu M et al. Inverted residuals and linear bottlenecks: mobile networks for classification, detection and segmentation. [C]∥Computer Vision and Pattern Recognition(2018).
[32] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. [C]∥International Conference on Machine Learning, 448-456(2015).