
Tao ZHOU, Yali DONG, Shan LIU, Huiling LU, Zongjun MA, Senbao HOU, Shi QIU. Cross-modality Multi-encoder Hybrid Attention U-Net for Lung Tumors Images Segmentation[J]. Acta Photonica Sinica, 2022, 51(4): 0410006
- Acta Photonica Sinica
- Vol. 51, Issue 4, 0410006 (2022)
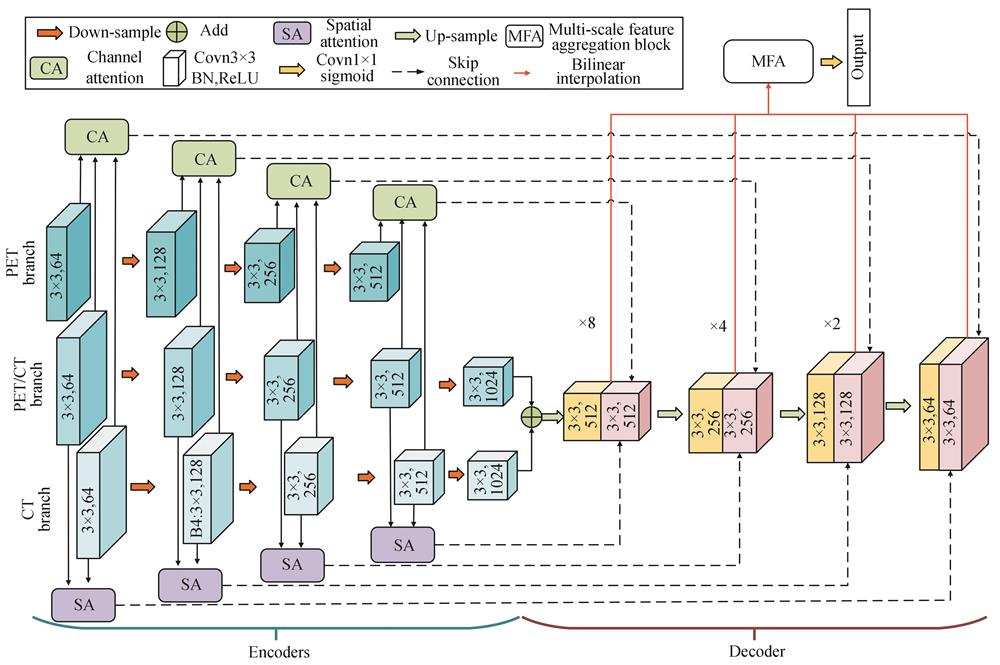
Fig. 1. MEAU-Net network architecture
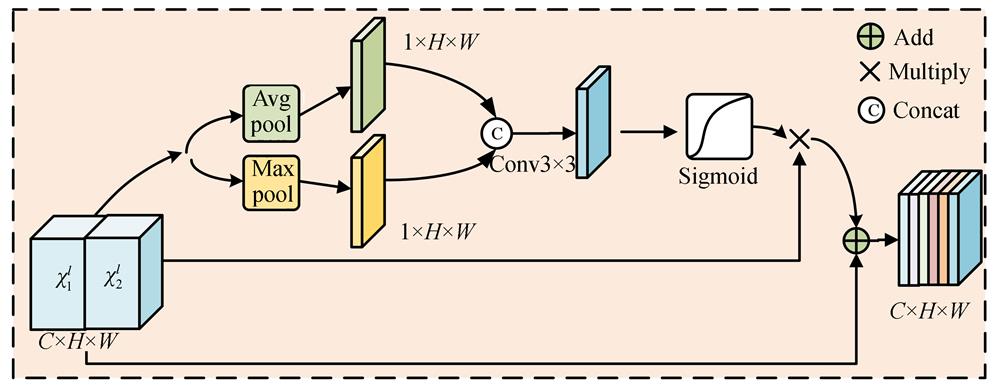
Fig. 2. Spatial attention mechanism
Fig. 3. Channel attention mechanism
Fig. 4. Multi-scale feature aggregation block
Fig. 5. CT,PET/CT and PET image
Fig. 6. CT image three-dimensional gray value
Fig. 7. Network segmentation results of different encoders
Fig. 8. Comparison of segmentation results of different encoders
Fig. 9. CT image three-dimensional gray value
Fig. 10. Network segmentation results of different attention mechanisms
Fig. 11. Comparison of segmentation results of different attention mechanisms
Fig. 12. CT image three-dimensional gray value
Fig. 13. Segmentation results of different methods
Fig. 14. Comparison of segmentation results of different methods
|
Table 0. [in Chinese]
|
Table 0. [in Chinese]
|
Table 1. Segmentation results of multi-encoders
|
Table 2. Segment results of different attention mechanisms
|
Table 3. Segmentation results of MEAU-Net and other networks

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20