
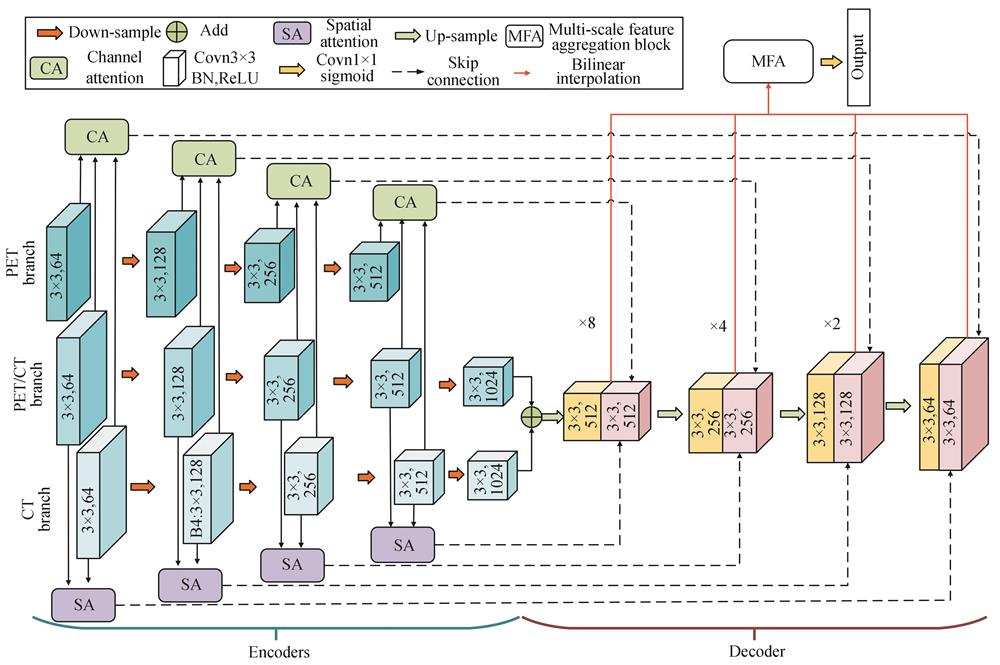
Tao ZHOU, Yali DONG, Shan LIU, Huiling LU, Zongjun MA, Senbao HOU, Shi QIU. Cross-modality Multi-encoder Hybrid Attention U-Net for Lung Tumors Images Segmentation[J]. Acta Photonica Sinica, 2022, 51(4): 0410006
- Acta Photonica Sinica
- Vol. 51, Issue 4, 0410006 (2022)
Abstract


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20