1State Key Laboratory of Surface Physics, Key Laboratory of Micro- and Nano-Photonic Structures (Ministry of Education) and Department of Physics, Fudan University, Shanghai 200433, China
2Institute for Nanoelectronic Devices and Quantum Computing, Fudan University, Shanghai 200433, China
3Collaborative Innovation Center of Advanced Microstructures, Nanjing University, Nanjing 210093, China
Minjia Zheng, Lei Shi, Jian Zi, "Optimize performance of a diffractive neural network by controlling the Fresnel number," Photonics Res. 10, 2667 (2022)
Copy Citation Text
To achieve better performance of a diffractive deep neural network, increasing its spatial complexity (neurons and layers) is commonly used. Subject to physical laws of optical diffraction, a deeper diffractive neural network (DNN) would be more difficult to implement, and the development of DNN is limited. In this work, we found controlling the Fresnel number can increase DNN’s capability of expression and its spatial complexity is even less. DNN with only one phase modulation layer was proposed and experimentally realized at 515 nm. With the optimal Fresnel number, the single-layer DNN reached a maximum accuracy of 97.08% in the handwritten digits recognition task.
1. INTRODUCTION
Supervised machine learning (ML) is widely used as one of the most essential methods for many computer vision tasks [1,2], including image classification [3,4], image segmentation [5,6], and target or saliency detection [7–11]. Such ML algorithms require large-scale parallel computing, such as convolution operation and large matrix or vector-matrix multiplication [4,12–15]. With the ever-increasing demand for computational resources, advances in performance of electronic devices have hit a bottleneck [16–18]. To meet the need, a new approach called the optical neural network (ONN) has been proposed. ONN naturally provides privileges of high parallelism, high-speed calculation, and low energy consumption over electronic devices [19–33]. ONN also has proved to be feasible and effective in solving many ML problems, and it can be used to work as a image classifier, a speech recognizer, an autoencoder, a recurrent neural network, and so on [19,20,26,27,34–42]. Recently, an all-optical ONN framework termed diffractive deep neural network () was proposed to provide operations of optical diffraction at the speed of light and reach hundreds of billions of connections between neurons in a power-efficient manner [26]. can accomplish some optical logical operations and more image processing tasks as well [42–47].
regards each phase modulation pixel on the hidden layers as an artificial neuron. The connections between the hidden layers are determined by the transmission or reflection coefficient for each neuron when light is traveling forward. The values of neurons in are optimized by using the error backpropagation algorithm, and exact phase values are converted into a relative height map h (, where is the difference of relative index between the fabricated material and the air). After is well trained, the passive neurons can be fabricated by 3D printing or photolithography etching [26,44,48–50]. In the manufacturing process, the allowed phase errors are proportional to the working wavelength. This means that ’s performance at wavelengths shorter than infrared is below expectations. Furthermore, when hidden layers are added into to get better performance, the accumulation of errors owing to the misalignment of multiple layers also remains a big problem. With the growing needs of spatial complexity, especially neurons and layers, implementation difficulties arise as well. Hence, reducing ’s space complexity deserves further study while its capability of expression is kept.
In this work, we introduce a new approach toward designing the phase-only all-optical ML framework by controlling the Fresnel number that describes the regime of diffraction effects. Making this diffraction-related parameter wet-set will optimize the performance of a diffractive neural network (DNN) instead of increasing the hidden layers in . To demonstrate how the Fresnel number works, we propose the framework of a single-layer diffractive neural network (SL-DNN), since its space complexity is minimized to a great extent. We find that DNN with even single phase modulation layer can provide good capability of expression. In numerical experiments, we achieved a blind testing accuracy of 97.08% in the Mixed National Institute of Standards and Technology (MNIST) handwritten digit recognition task [51]. In our experiments, we implemented SL-DNN, tested 1000 samples, and achieved an accuracy rate of 92.70%.
Sign up for Photonics Research TOC. Get the latest issue of Photonics Research delivered right to you!Sign up now
2. THEORETICAL ANALYSIS
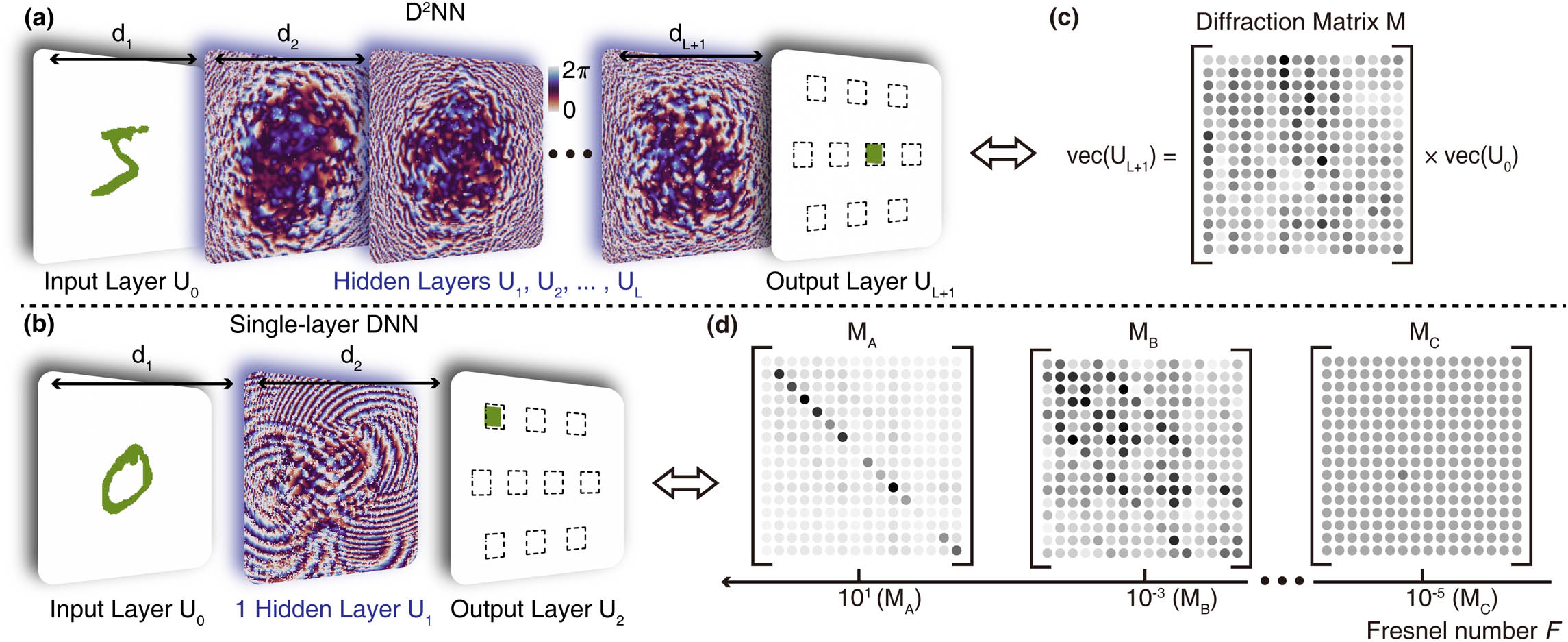
Phase-only describes a multidiffraction process to arbitrarily modulate the wavefront of light diffracted from an input plane. The process can be treated as a matrix multiplication operation on the input plane without the nonlinear activation layer. As illustrated in Figs. 1(a) and 1(c), the diffraction process of multilayer diffraction can be simply represented by a complex-valued matrix , and the optical intensity after the entire diffraction process can be expressed as where and are the vectorized optical field at the input and output layer, and is the optical intensity of the output layer. In Eq. (1), represents the number of phase modulation layers. The diffraction process between the successive two layers can be characterized as where is the optical field before layer and is the optical field after layer , and is the diffraction process between the two successive layers and is a complex-valued symmetric matrix. The phase modulation layer is added after , and the optical field becomes “” represents the Hadamard product, and the operation can be transformed to matrix multiplication. Therefore, Eq. (3) can be rewritten as So far, the diffraction matrix can be described by
Figure 1.Schematic diagram of the frameworks of (a) deep and (b) SL-DNN; (c) the entire diffraction and multi-layer phase modulation process can be regarded as a matrix multiplication by diffraction matrix . (d) The diffraction matrix of SL-DNN with different values of Fresnel number can be represented by (), (), and ().
In other words, , as well as , is the transformation matrix that maps vectors of the input plane () into the output plane () in an -dimensional Hilbert space, where is the pixel number of every layer’s side length. should have two major properties to finish the classification task. One is that the row vectors of need to be incompletely orthogonal, which allows to implement many-to-one mapping so that has the ability to cluster inputs of the same class. The other is that the value of rows of has to be arbitrary. It provides the ability to separate the different kinds of samples. To satisfy these two requirements, research has focused on increasing neurons and layers of , in other words, increasing its spatial complexity. In Fig. 1(c), the diffraction matrix of multilayer provides both the many-to-one mapping and the arbitrariness. Generally speaking, ’s classification ability is strengthened when the number of layers is increased [26]. With the increase of neurons and layers, the difficulty of preparing phase modulation neurons and the layer-to-layer alignment increases.
It is commonly considered that with few layers can provide only one of these requirements mentioned above. In Figs. 1(b) and 1(d), the diffraction matrix of DNN with one hidden layer can be divided by the Fresnel number into three cases, where and is the pixel area, is the working wavelength, and is the layer-to-layer distance. As shown in Fig. 1(d), when is approximately , it also means in the case of very near diffraction, the row vectors of are arbitrary but completely orthogonal. It means only elements on the diagonal of the diffraction matrix have the capability to modulate the incident light. The input and the output layers are mapped one-to-one by , and it cannot afford the requirement of many-to-one mapping. Likewise, when is a pretty small value (approximately ), it also means in the case of very far diffraction, all row vectors of are almost linearly related. In , all elements are almost identical, which means . All will have the same pattern at the output layer, and DNN offers no ability to modulate the incoming light. This leads to the result that the diffraction matrix can only provide many-to-one mapping but cannot separate samples from different classes.
In order to resolve the contradiction between DNN’s preparation difficulty and the requirements of its ability of expression, we propose a new approach for regulating an SL-DNN by controlling the Fresnel number so that it can also meet both requirements mentioned above. DNN regards connections originating from each neuron as the kernels of convolutional neural network. If is too large, the kernel size will be , and if is too small, the kernel size will be very large and the values of the kernel are almost identical. An appropriate provides both enough receptive field and different values of the kernel. In Fig. 1(d), with a proper is more like the in Fig. 1(c) than and . determines the property of .
We can compare with and find out that an appropriate can provide a many-to-one mapping of the input layer to the output layer even if only one phase modulation layer is applied. In the meantime, good arbitrariness can support SL-DNN to accomplish tasks like MNIST handwritten digit recognition. Furthermore, when , SL-DNN can provide enough ability of expression and show good performance in such a classification job. More information is provided in Appendix A.
3. IMPLEMENTATION OF DNN AT DIFFERENT FRESNEL NUMBERS
A. Training Methods
In Fig. 2, SL-DNN consists of two diffraction and one phase modulation process. The first diffraction is from input layer to the phase modulation layer (hidden layer), and the second diffraction is from the hidden layer to the output layer. Note that is given by the pixel size , the diffraction distance , and the working wavelength . To get different in the experiment, there is no need to change or every time. We can simply resize the input layer, and this operation equivalently changes when the parameters of DNN are fixed. We use the angular spectrum (AS) method to simulate these two diffraction processes. This can be written as where and are the optical field at layer and , is the transfer function in the AS method, and is the Fourier transform. The process of phase modulation is provided by a Hadamard product of the incoming optical field and the phase delay part. Phase values are optimized via the error backpropagation algorithm. We use softmax-cross-entropy (SCE) loss and the mean squared error (MSE) loss as loss functions for our training. SCE loss can be defined as and represents the number of categories, is the one-hot encoding of ground truth, and is the softmax operation of output, where is the sum of light intensity in the selected region of digit on the output layer shown in Fig. 2. MSE loss can be defined as where is the light intensity on the output plane and is the ground truth.
Figure 2.Schematic experimental setup of SL-DNN. A laser beam at 515 nm was used. The linearly polarized beam was incident on the DMD and images of digits in the MNIST data set were illuminated by DMD. After that, light was normally reflected and propagated to the SLM. SLM modulates the phase of light field and it was reflected by a beam splitter (BS). The output layer is shown by the incoming light received by a CMOS camera. The image dimensions of digits are resized to and to show different when the diffraction distance is fixed. Colors of two light paths are only to distinguish between two SL-DNNs with different .
To demonstrate the performance of SL-DNN in the MNIST handwritten classification task, we trained the network with 60,000 images of 10 digits. After SL-DNN had been well trained, we numerically tested the model with a test set of another 10,000 images. In Fig. 3(b), SL-DNN achieves an accuracy of 94.94% in blindly testing its performance when we use SCE and MSE loss functions whose ratio is 0.2:0.8. We set the dimension of every layer to be and selected an appropriate to achieve SL-DNN’s best performance. SL-DNN also achieves the highest accuracy of 97.08% when using SCE loss only. More information about the simulation and experiments is provided in Appendix A.
Figure 3.(a) Images of MNIST handwritten input digits are binarized. Ten light intensity detector regions are set on the output plane, respectively. The detector with maximum sum of intensity shows the predicted number. (b) The confusion matrix and energy distribution percentage of show numerical test results of blindly testing 10,000 images, and it achieves the max accuracy rate of 94.94%. (c) The confusion matrix and energy distribution percentage for the experimental results. We use 1000 different handwritten digits in the test set as input and achieve an accuracy rate of 92.70%.
To implement SL-DNN, we adapted the experimental setup shown in Fig. 2. In the experiment, we used a programmable digital micromirror device (DMD) to form the input patterns of data sets and another programmable reflective phase-only liquid-crystal spatial light modulator (LC-SLM) as the phase modulation layer. We also used a complementary metal oxide semiconductor (CMOS) image sensor to read the light intensity at the output layer. The working wavelength of light was at 515 nm based on a diode-pumped laser. In our experiment, input digits were illuminated by the collimated laser beam incident onto the DMD, and then images in the test set were displayed on DMD. Before that, images were resized and binarized. We used a 2-bit reflective DMD to form the shapes of different input digits. After the light was reflected and traveled a distance of (), we used a reflective phase-only SLM as the phase modulation layer. This will lead to a problem: the reflected light coming from the untrained pixels outside the region we have trained will also affect the optical field distribution at output plane. So, we enlarge the dimension of phase modulation layer to to avoid this problem. We trained SL-DNN, and phase values of the hidden layer are uploaded to the SLM. After the second diffraction of distance of (), a CMOS camera received the light intensity signal. As shown in Fig. 3(a), we manually selected the ten regions of output light distribution captured by the CMOS camera. Of these ten regions, the highest total light intensity shows the recognized digit. In Fig. 3(c), we got an accuracy rate of 92.70% in blindly testing 1000 randomly selected samples in the test set when . In Fig. 3, we also provide the energy distribution of the ten selected regions. It is obvious that light has been focused in the specific region of each test sample. Note that, when we get into the experiment, errors in the diffraction distance measurement and of the instruments themselves cause little energy misdistribution on the output layer in comparison to simulation results. The fill factors of the DMD and SLM also slightly affect the reconstruction of the diffraction process. All these lead to a decrease in accuracy of the experiments compared with numerical simulation.
To illustrate the relation between Fresnel number and the performance of SL-DNN further, we tested the network at different numerically and experimentally. The experimental setup is fixed so that we can see from Fig. 2 that resizing the input images equivalently changes the . We can see from Fig. 4 that at different wavelengths of light, there is the same range, which is from approximately to . If is in this range, SL-DNN can provide good performance and has good ability of expression. We also experimentally tested SL-DNN at different by resizing the input images on DMD from initially to , , and , respectively, while keeping the experiment setup fixed. The accuracy of another three experiments we have gotten is 64.10%, 86.60%, and 74.10%, respectively. More information about the experiment is shown in Appendix B.
Figure 4.Accuracy of SL-DNN as an MNIST handwritten digit classifier with changing Fresnel number . For different working wavelengths, SL-DNN has a same range of approximately from to , which shows SL-DNN’s good performance.
To conclude, we propose a new approach that shows that controlling the diffraction-related parameter can improve the network’s capability of expression and optimize the performance of the DNN. As long as the diffractive parameters are well set, a DNN with only single phase-only modulation layer can also be applied to accomplish object classification tasks. As the space complexity is reduced, it is possible to implement DNN at a shorter wavelength. We numerically tested SL-DNN performance in MNIST handwritten recognition task and reached the highest accuracy rate of 97.08%. We then experimentally realized SL-DNN in the visible range by using a DMD as the input layer and a reflective phase-only SLM as the phase modulation layer. We also experimentally tested the performance of SL-DNN and got an accuracy rate of 92.70%. This article reveals a new modulation dimension to optimize the performance of DNN and makes it possible to implement more complex and miniaturized all ONN devices.
B. Discussion on the Difference between the Fresnel Number Model and Fully Connected Model
The fully connected model proposed by Lin et al. [26] and Chen et al. [48] ensures that pixels on the successive phase modulation layers are actually linked. It shows that the diffraction distance should be bounded below by . Their conclusion is appropriate for multilayer DNNs. In this article, we show that if diffraction distance is substituted for the Fresnel number, it should be bounded above by . This conclusion is self-consistent with Lin’s and Chen’s work. Moreover, we find that the Fresnel number is also bounded below by , and it is merely related to the dimension of inputs. When the Fresnel number is in this optimal range, which has both upper and lower bounds, DNN can have a good performance. Our conclusion further applies to DNN with a single-phase modulation layer. More information is shown in Appendix A.
C. Discussion on DNN at Broadband Incoherent Light Incidence
To make DNN into a practical application, the optimization of DNN in the case of broadband incoherent light incidence is worth investigation. Speaking of broadband illumination, we first think of multichannel DNN with coherent light. SLMs can be used as gratings to separate different colors of light and as lenses to focus light at different locations. For the single frequency of light, the theory on the performance of network with respect to the Fresnel number still works. When the answers from the DNN from every channel are combined or retrieved, broadband DNNs can be realized. Since there are difficulties in the implementation of such a DNN with a single SLM, more SLMs and metasurfaces can be used to respond to light at different frequencies.
Moreover, holography techniques are useful in the implementation of DNNs. Self-interference incoherent digital holography (SIDH) is one of the techniques that can record the holographic information from the object illuminated by the incoherent light [52]. We believe that overlay phase values of SLMs can be trained to realize classification tasks, since the initial phase encoding can be optimized by the Gerchberg–Saxton algorithm [53].
D. Discussion on Optical Nonlinearity of DNN
Optical nonlinearity can be implemented by using nonlinear materials as diffractive layers in DNNs. In the framework of DNNs, the only nonlinear operation without optical nonlinearity is the recording of light intensity at the camera. This kind of operation is different from the commonly known “nonlinear activation function.” The difference is that it has no “activation” judgment. When we add a complex-valued activation function, such as modReLU, after the phase modulation layer, the performance of the DNN will be improved. More information is shown in Appendix A. Although nonlinear activation function is applied, SL-DNN cannot be called a “deep” neural network. When activation functions or optical nonlinearity layers are applied after every layer in multilayer DNNs, a deep nonlinear DNN can be realized and will have better performance. Optical nonlinearity requires immense light intensity, so that the implementation of nonlinear DNN at low-light intensity deserves further investigation.
APPENDIX A: NUMERICAL EXPERIMENTS
Data Set Preprocessing
Input images in MNIST handwritten data set of ten digits () are resized and binarized by using the image resize algorithm based on OpenCV. We use the resampling methods with the pixel area relation provided by OpenCV. The limit of sampling in the Fourier space may cause inaccuracy in simulation. So, each sample image employed zero padding in real space to limit the computational error. It can be written as
Derivation of Optimal Range of the Fresnel Number
Let be the diffraction distance between the successive two layers and and remain the same value in the DNN. Let be the distance of neuron on one layer and the other on the next layer. We can simply get where is the layer’s dimension of one side and is the pixel size. The neurons receive the information that the maximum phase difference is determined by the secondary wave diffraction. It should satisfy the following inequality, which is It can also be rewritten as Then, we can get Fresnel number is defined by Eq. (6). We can substitute it into Eq. (A5) and get Normally, is a very small and negligible amount. So, we can get In Fig. 4, we can get .
Since the shape of each pixel is a square, the diffraction pattern of a single pixel has its own energy distribution. It can be expressed as where is the coordinate of pixel at output plane, and We let and can get The max or is supposed to be . So, we can get the inequality that and here, we can also see from Fig. 4 that . So far, we know that when and , SL-DNN has a good performance as an MNIST handwritten digits classifier. In this study, we let . So, we can get .
In Fig. 5, a large shows that the DNN provides a one-to-one mapping, and a very small shows that DNN provides a many-to-one mapping but no arbitrary desirability. An appropriate gives DNN a good ability of expression.
Figure 5.Optical intensity of single-pixel illumination at different F.
The experimental setup of the SL-DNN is shown in Fig. 12. A linear polarizer (LP) was placed to get linearly polarized light. Another LP filter was placed before the CMOS image sensor, and it was used as an analyzer whose direction of polarization was oriented parallel to the long axis of the SLM. A half-wave (HW) plate was placed between the LP and the DMD to eliminate zero-order diffraction as much as possible. The angle between incident light and its normal is about 24°.
Figure 14.Experiment results of resizing the images of input digits to 50, 500, and 800, respectively, and equivalent Fresnel number is approximately , , and .
[3] P. Bartlett, A. Krizhevsky, F. Pereira, I. Sutskever, C. Burges, G. E. Hinton, L. Bottou, K. Weinberger. Advances in Neural Information Processing Systems 25 (NIPS 2012): 26th Annual Conference on Neural Information Processing Systems 2012(2012).
[4] Y. LeCun, D. Touretzky, B. Boser, J. Denker, D. Henderson, R. Howard, W. Hubbard, L. Jackel. Advances in Neural Information Processing Systems, 2(1989).
[32] S. Pai, Z. Sun, T. W. Hughes, T. Park, B. Bartlett, I. A. D. Williamson, M. Minkov, M. Milanizadeh, N. Abebe, F. Morichetti, A. Melloni, S. Fan, O. Solgaard, D. A. B. Miller. Experimentally realized in situ backpropagation for deep learning in nanophotonic neural networks(2022).
[53] R. W. Gerchberg, W. O. Saxton. A practical algorithm for the determination of plane from image and diffraction pictures. Optik, 35, 237-246(1972).
Minjia Zheng, Lei Shi, Jian Zi, "Optimize performance of a diffractive neural network by controlling the Fresnel number," Photonics Res. 10, 2667 (2022)