
Liangfu Li, Ruiyun Sun. Bridge Crack Detection Algorithm Based on Image Processing under Complex Background[J]. Laser & Optoelectronics Progress, 2019, 56(6): 061002
- Laser & Optoelectronics Progress
- Vol. 56, Issue 6, 061002 (2019)

Fig. 1. Schematic of dataset amplification of bridge crack images. (a) Original image; (b) horizontal flip; (c) vertical flip; (d) linear transformation; (e) spatial filtering transformation
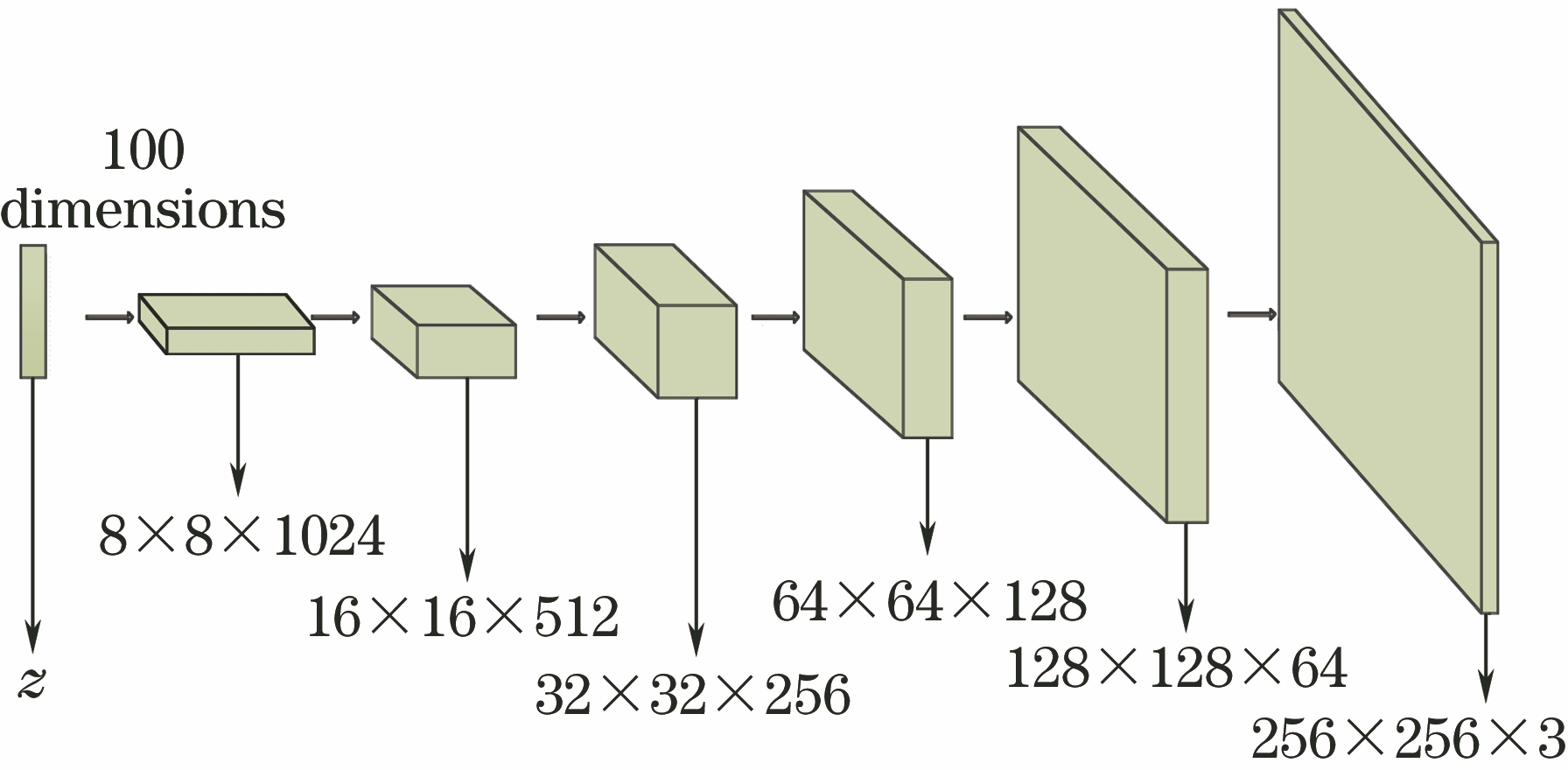
Fig. 2. Generative model
Fig. 3. Discriminant model
Fig. 4. Schematic of 4-layer DenseBlock
Fig. 5. Schematic of detection of high-resolution image
Fig. 6. Visualization comparison of cracks generated by DCGAN and BCIGM. (a) Nepoch=01; (b) Nepoch=03; (c) Nepoch=16; (d) Nepoch=25
Fig. 7. Visualization comparison of cracks generated by ReLU and SeLU. (a) Nepoch=01; (b) Nepoch=03; (c) Nepoch=16; (d) Nepoch=25
Fig. 8. Visualization comparison of experimental results with and without dataset amplification. (a) Original image; (b)label; (c) without dataset amplification; (d) with dataset amplification
Fig. 9. Comparison of crack detection results between existing algorithms and proposed algorithm. (a) Original image; (b) label; (c) threshold segmentation algorithm; (d) Canny algorithm; (e) NB-CNN algorithm; (f) random structure forest algorithm; (g) proposed algorithm
Fig. 10. Partial crack detection results by proposed algorithm. (a) Scene 1; (b) scene 2; (c) scene 3
|
Table 1. Network structure parameters of BCISM
|
Table 2. Proportion of number of different types of images in total dataset
|
Table 3. Influence of BCIGM on training speed under different conditions
|
Table 4. Effect of dataset amplification on experimental results
|
Table 5. Comparison of exiting semantic segmentation models and BCISM

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20