Map construction is crucial to simultaneous localization and mapping (SLAM) technology and the foundation for robot positioning and navigation tasks. The environment map constructed using the traditional SLAM approach only provides the environment’s topological and geometric information; it fails to provide the object’s semantic information, thereby resulting in the poor understanding of the environment. When global positioning is performed in a complicated environment, obtaining faster positioning using only the environmental scale information in the map is a challenge. A semantic map can realize a more intelligent human-computer interaction function of the robot and accelerate the robot repositioning. In the indoor environment, there is rich and fixed wall corner information. The distinction of wall corners aids the mobile robot in performing higher-level positioning and navigation work. An approach of incrementally constructing a semantic map based on the fusion of laser and vision to determine the semantic information of wall corners and objects is proposed. The findings reveal that using a semantic map can enhance the positioning performance of robots.
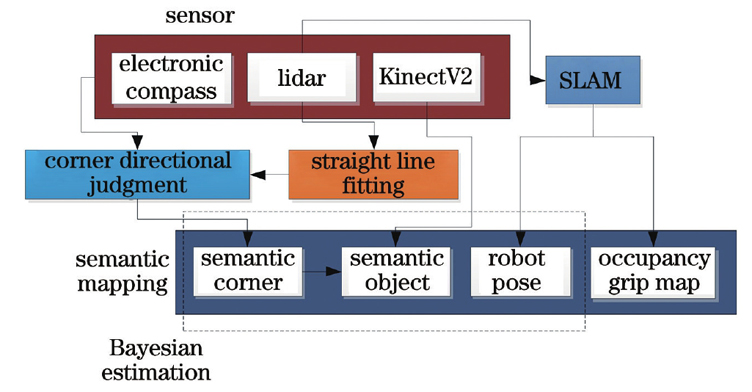
First, the laser lidar hit point was fitted linearly. Concave and convex wall corner information in the environment was extracted. The camera and electronic compass were employed to judge several wall corner categories to achieve rich wall corner category information. Then, the concave and convex wall corner information was used to determine and remove the cabinet objects, and the depth value achieved by the depth camera was corrected using the depth information of lidar, to obtain a more accurate semantic information of the surrounding object. Finally, the robot pose was synchronized, Bayesian estimation was employed to update the wall corner category and the object’s occupancy probability, and a semantic map was incrementally constructed.
In the indoor environment, the category information of concave and convex wall corners is extracted. Green represents the concave wall corner and blue represents the convex wall corner (Fig. 4). Then, wall corners are identified via target detection. The electronic compass and laser lidar are integrated to judge the direction of wall corners to obtain wall corner category information in four directions. The identification findings are accurate in the actual environment (Fig. 9). Errors are prone to occur when obtaining semantic information about cabinet objects via semantic segmentation. Therefore, concave and convex wall corner information is employed to remove the false detection of semantic segmentation. The camera depth is corrected using lidar depth information (Fig. 12). Finally, the constructed object semantic map, grid map, and wall corner information are combined to obtain the final semantic map (Figs. 18 and 19). The object’s outline is consistent with the grid obstacle area, and different wall corner categories correlates with the correct wall corner position. The semantic map represents the semantic information in the environment. The success rate of repositioning using the proposed algorithm is 95% (Table 5), and the speed of repositioning is three times faster than that of the approach without a semantic map (Fig. 24).
Laser lidar sensors were used to linearly fit the laser lidar hit point. Concave and convex wall corner information from the environment was extracted. The vision and electronic compass were employed to distinguish the concave wall’s directional corners, and four concave wall corners with various orientations were obtained. Furthermore, concave and convex wall corner information was employed to remove camera misidentification. First, the camera depth value was corrected using the laser depth value to achieve the correct semantic information of the cabinet object. Then, the semantic information was converted to coordinates and the object’s semantic map was incrementally constructed using Bayesian estimation. Finally, the semantic and grid maps were combined to obtain a final semantic grid map. Experiments in the simulation and real environment can prove the proposed method’s effectiveness. The semantic map is employed for relocation experiments to validate the semantic map’s practicality.