Longxue Cheng, Lixia Xi, Donghe Zhao, Xianfeng Tang, Wenbo Zhang, Xiaoguang Zhang. Improved modulation format identification based on Stokes parameters using combination of fuzzy c-means and hierarchical clustering in coherent optical communication system[J]. Chinese Optics Letters, 2015, 13(10): 100604
Copy Citation Text
In this Letter, we develop the Stokes space-based method for modulation format identification by combing power spectral density and a cluster analysis to identify quadrature amplitude modulation (QAM) and phase-shift keying (PSK) signals. Fuzzy c-means and hierarchical clustering algorithms are used for the cluster analysis. Simulations are conducted for binary PSK, quadrature PSK, 8PSK, 16-QAM, and 32-QAM signals. The results demonstrate that the proposed technique can effectively classify all these modulation formats, and that the method is superior in lowering the threshold of the optical signal-to-noise ratio. Meanwhile, the proposed method is insensitive to phase offset and laser phase noise.
The continued demand for increased optical network capacities provides challenges for current and future network designs. To overcome these challenges, elastic optical networks equipped with flexible transceivers are required[1]. In order to demodulate signals optimally at the receiver side[2], modulation format identification (MFI) is needed in future elastic optical networks.
Exploration for MFI techniques in optical communication has just begun. Four different methods have been employed for optical MFI: (a) identification from constellation diagrams using k-means, which is simple but requires a carrier and phase recovery before MFI[3]; (b) artificial neural network-based identification, which can recognize all the formats but needs prior training[4]; (c) principal component analysis-based pattern recognition on asynchronous delay-tap plots, which can realize channel estimation in the meantime but needs specific amounts of sampling points[5]; (d) the Stokes space and machine learning technique[6].
Here, we theoretically analyze the distribution characteristics of Stokes space clusters for different formats. Based on this, Stokes parameters are extracted in the coherent receiver and utilized to distinguish between quadrature amplitude modulation (QAM) and phase-shift keying (PSK) signals. Furthermore, a decision criterion combining fuzzy c-means (FCM) and a hierarchical clustering algorithm is used to provide enhanced discrimination among the modulation formats. This method was proved applicable to wireless communications[7]. The identification algorithm is implemented after chromatic dispersion (CD) compensation.
Sign up for Chinese Optics Letters TOC. Get the latest issue of Chinese Optics Letters delivered right to you!Sign up now
For polarization-multiplexed (PM) system, the received signal can be expressed with the Jones vector in the following form:
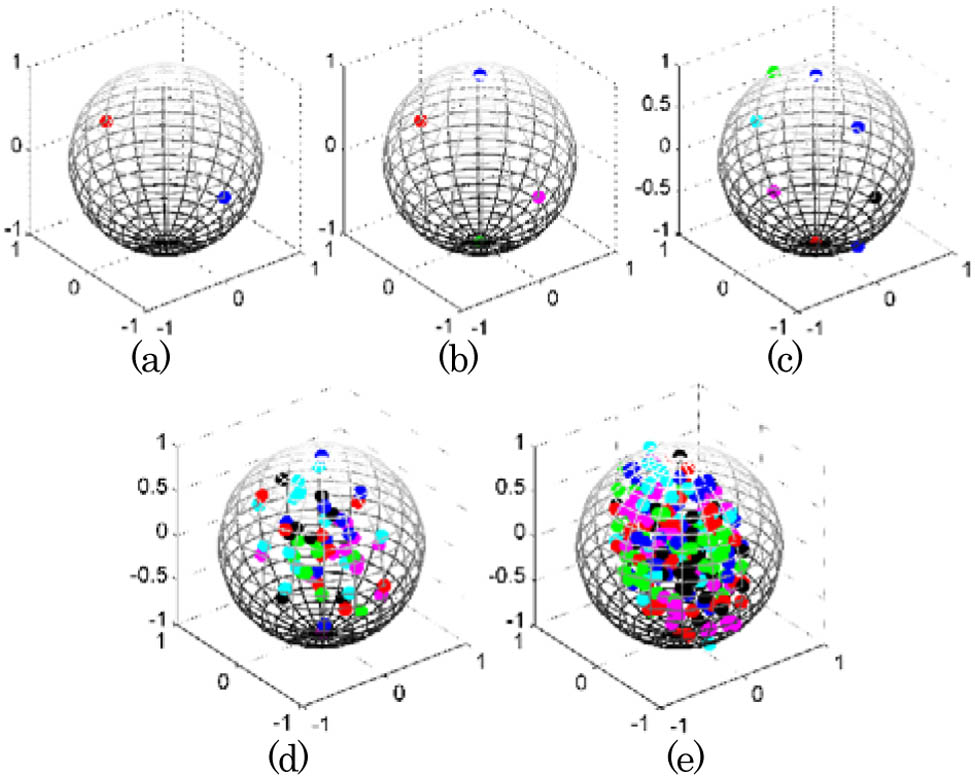
The Jones vector is transformed into the Stokes vector, , as follows[8]: where is the phase difference between the and polarization components of the Jones vector . If the frequency offset, laser linewidth, and initial phase are considered in the received signal, they just change the phase of and , and hence the Stokes parameters are not affected, as shown in Eq. (2). Thus, the proposed method is insensitive to these impairments. When normalized by , the vector indicates different points inside the Poincaré sphere. Different modulation formats exhibit different signatures in accordance with the number of clusters inside the Poincaré sphere; therefore, we can identify modulation formats by recording the number of clusters. For binary PSK (BPSK), quadrature PSK (QPSK), 8PSK, 16-QAM, and 32-QAM signals, the numbers of clusters are 2, 4, 8, 60, 248, and the distributions inside the Poincaré sphere are shown in Fig. 1.
Figure 1.Stokes cluster inside the Poincaré sphere. (a) PM-BPSK, (b) PM-QPSK, (c) PM-8PSK, (d) PM-16-QAM, and (e) PM-32-QAM.
We theoretically derived the distributions for different modulation formats. Take 16-QAM, for example: the distribution of clusters is derived as follows.
Figure 2 shows the constellation diagram of 16-QAM, and the possible values of amplitude and phase are listed in Table 1.
The corresponding Stokes vector can be calculated via Eq. (2). The possible values of are listed in Table 2. The number of clusters of the 16-QAM signal is 60.
Figure 1 shows that the number of clusters increases sharply when the order of modulation increases. The distances between clusters become smaller, and distinguishing between the adjacent clusters becomes more difficult. Nevertheless, we find that the data is characterized by symmetry from Table 2. Therefore, the number of clusters whose coordinate values, , , and are all nonnegative can be utilized to distinguish different QAM signals. The corresponding numbers for 16-QAM and 32-QAM are 14 and 43, respectively, which is shown in Fig. 3.
Figure 3.Stokes cluster with nonnegative coordinate values inside the Poincaré sphere. (a) PM-16-QAM and (b) PM-32-QAM.
We first distinguish between the PSK and QAM signals. The key feature used is the maximum value of the power spectral density of the normalized-centered instantaneous amplitude , which is defined by where is the number of symbols, DFT means discrete Fourier transform, and is the value of the normalized-centered instantaneous amplitude at the time instants , , defined by
Here, , where is the average value of the instantaneous amplitude
For ideal PSK signals, there is no amplitude modulated information and is zero; thus, the parameter is zero theoretically. For QAM signals, the amplitude is not constant and varies; thus, is much higher than zero[9]. The PSK and QAM signals can be distinguished by setting an appropriate threshold of . Additionally, utilizing the spectral power density rather than the time domain data can lower the influence of burst noise.
After distinguishing between the PSK and QAM signals, we combine the FCM algorithm and hierarchical clustering to further identify M-PSK and M-QAM signals.
FCM is the most popular fuzzy-clustering algorithm. It is based on the minimization of the following objective function[10]: where is an arbitrary real number greater than 1, is the number of sampling points, and is the clustering number. stands for the degree of membership for cluster , represents the th measured data, is the th center of the cluster, and is the Euclidean distance between any measured data and the center.
Fuzzy partitioning is carried out through an iterative optimization of the objective function in Eq. (6), with the update of membership and the cluster centers by
FCM is sensitive to initial conditions, especially the initial cluster centers, which may lead to local minimum results. To avoid the local result, a simple and efficient select rule of the initial cluster centers is applied in the FCM algorithm[11].
This iteration will stop when is satisfied, where is a termination criterion between 0 and 1, and is number of iteration steps.
After the FCM algorithm iterates over, the number of clusters is constant, which cannot determine the modulation formats. Determining the actual number of clusters is necessary in the next step, which is based on hierarchical clustering, where data is grouped by creating a cluster tree over a variety of scales. The procedure of hierarchical clustering is as follows: first, we calculate the Euclidean distance between every pair of objects in the data set (centroids after FCM clustering). Then, we group the objects into a binary, hierarchical cluster tree. Finally, we determine where to cut the hierarchical tree into clusters, which will achieve different numbers of clusters. The cluster number can be assigned from ( is the number of clusters in the FCM algorithm). In this step, we calculate the objective function for each possibility, and the number of optimum clusters corresponds to the minimum value of the objective function. The objective function is defined as follows[12]:
For every modulation format, a range is set. We propose to use the range where the cluster result (the number of clusters) falls as the decision metrics.
Simulations using VPI and MATLAB are carried out to verify the above method. Figure 4 shows the simulation setup. In the transmitter, 28GBaud PM-BPSK, PM-QPSK, PM-8PSK, PM-16-QAM, and PM-32-QAM signals are generated separately. In the optical channel, the PM signal passes through the optical fiber, the set optical signal-to-noise ratio (OSNR) module, and the polarization mode dispersion (PMD) emulator. After coherent detection and two-fold oversampling, four-channel signals are sent to the digital signal processing module, which is implemented using MATLAB. After CD compensation, MFI is performed. The dotted frame at lower side of Fig. 4 shows the identification flow.
In the first step, the threshold of is set to 1, which is determined from a number of simulations. The PSK and QAM formats can be successfully identified when the OSNR is above 16 dB. Figure 5 shows the values of versus different OSNRs for different modulation formats.
Figure 5. versus OSNR for various modulation formats.
Next, the FCM and hierarchical clustering are combined to further distinguish between the PSK and QAM signals. The decision range for every format is listed in Table 3.
Figure 6 shows the probability of correct identification under the effect of OSNR. The OSNR values for different formats are well chosen based on the needs of a commercial system. As can be seen from Fig. 6, the probability of correct identification increases when the OSNR increases, except for the BPSK signal. Even when the OSNR is as low as 1 dB, the BPSK signals can be identified with 100% probability. For the QPSK, 8PSK, 16-QAM, and 32-QAM signals, the thresholds of identification with 100% probability are 17, 22, 28, and 30 dB.
Figure 6.Probability of correct identification versus OSNR.
Figure 7 shows the probability of correct identification under the effect of the first-order PMD, which is quantified by differential group delay (DGD). Here, we just list the results for the QPSK and 32-QAM signals. The OSNR values are set to 17 and 30 dB independently. As can be seen from Fig. 7, the probability of correct identification decreases as the DGD increases. The thresholds of identification with 100% probability for the QPSK and 32-QAM signals are 22 and 14 ps. So, this method shows high tolerance to first-order PMD.
Figure 7.Probability of correct identification versus DGD.
In conclusion, we improve the Stokes space-based MFI method in Ref. [6] by combing power spectral density and a cluster analysis. The process of clustering utilizes FCM and hierarchical clustering algorithms. The simulation results indicate that the method shows higher tolerance to OSNR and first-order PMD than the method in Ref. [6], and our method is insensitive to the laser linewidth. Meanwhile, we extend the modulation formats that can be identified to 32-QAM signals. Since this method is sensitive to CD, it must be implemented in systems where the CD can be monitored and compensated precisely, like the systems in Refs. [13,14]. Meanwhile, the Stokes-based method only can be used in a receiver capable of measuring Stokes parameters[6].
References
[1] K. Roberts, C. Laperle. Proceedings of the ECOC, 1(2012).
[2] I. T. Monroy, D. Zibar, N. G. Gonzalez, R. Borkowski. Proceedings of the 13th ICTON, 1(2011).
[3] N. G. Gonzalez, D. Zibar, I. T. Monroy. Proceedings of the ECOC, 6, 11(2010).
Longxue Cheng, Lixia Xi, Donghe Zhao, Xianfeng Tang, Wenbo Zhang, Xiaoguang Zhang. Improved modulation format identification based on Stokes parameters using combination of fuzzy c-means and hierarchical clustering in coherent optical communication system[J]. Chinese Optics Letters, 2015, 13(10): 100604