
Alessia Suprano, Danilo Zia, Emanuele Polino, Taira Giordani, Luca Innocenti, Alessandro Ferraro, Mauro Paternostro, Nicolò Spagnolo, Fabio Sciarrino, "Dynamical learning of a photonics quantum-state engineering process," Adv. Photon. 3, 066002 (2021)
- Advanced Photonics
- Vol. 3, Issue 6, 066002 (2021)
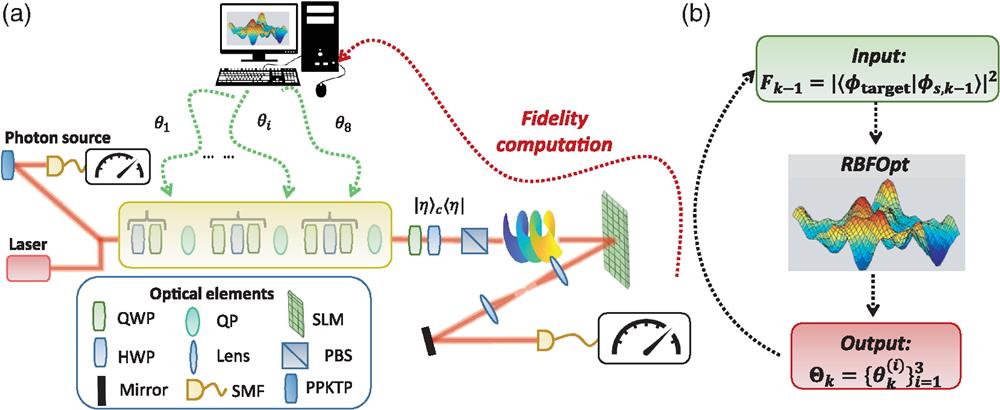
Fig. 1. Experimental apparatus. (a) The engineering protocol has been tested experimentally in a three-step discrete-time QW encoded in the OAM of light with both single-photon inputs and classical continuous wave laser light (CNI laser PSU-III-FDA) with a wavelength of 808 nm. The single-photon states are generated through a type-II spontaneous parametric down-conversion process in a periodically poled KTP crystal. The input state is characterized by a horizontal polarization and OAM eigenvalue
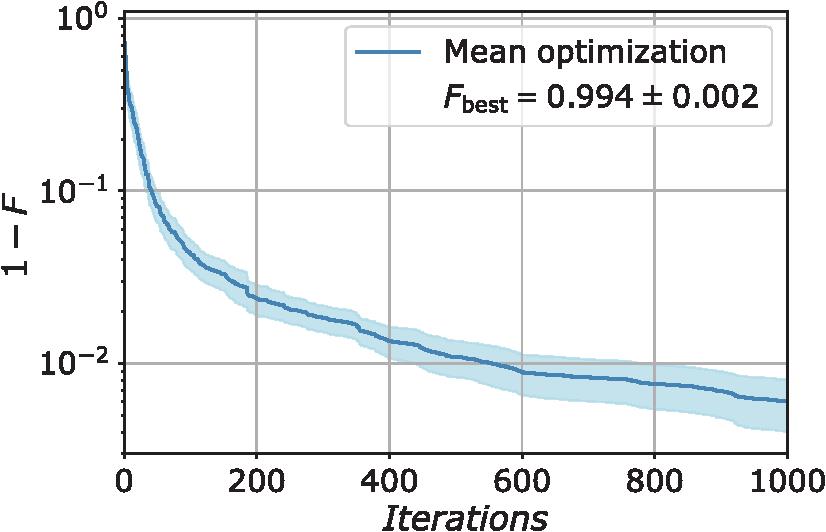
Fig. 2. Simulated optimization: infidelity
Fig. 3. Experimental results: (a) minimization of the quantity
Fig. 4. Experimental perturbation results. (a) Optimization under external perturbation of the quantity
Fig. 5. Scalability: the plot shows the mean number of RBFOpt algorithm iterations as a function of the black-box problem parameters. Here, the optimization process is interrupted when a value of the fidelity between the target state and the one proposed by the algorithm of at least 98% is reached. For each configuration, the iteration values are obtained by averaging more than 50 random target states and simulating experimental noise using binomial and Poissonian distributions. The uncertainty associated with each point is provided by the standard deviation of the mean.
Fig. 6. Comparison between different optimization algorithms: the plot reports the simulated performances of three different algorithms averaged over the optimization of 10 different states, each of which is repeated 10 times. Dotted blue, dashed green, and continuous orange lines report the trends corresponding to Powell, random search, and RBFOpt, respectively. RBFOpt is found to perform significantly better than the alternatives in most cases. All curves are generated simulating experimental noise with both Poissonian () and binomial fluctuations.
|
Table 1. The parameters used in the study of the optimization under perturbations for the engineered states. In the second column, we report the values of the perturbation occurrence probability q t
|


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20