Experimental engineering of high-dimensional quantum states is a crucial task for several quantum information protocols. However, a high degree of precision in the characterization of the noisy experimental apparatus is required to apply existing quantum-state engineering protocols. This is often lacking in practical scenarios, affecting the quality of the engineered states. We implement, experimentally, an automated adaptive optimization protocol to engineer photonic orbital angular momentum (OAM) states. The protocol, given a target output state, performs an online estimation of the quality of the currently produced states, relying on output measurement statistics, and determines how to tune the experimental parameters to optimize the state generation. To achieve this, the algorithm does not need to be imbued with a description of the generation apparatus itself. Rather, it operates in a fully black-box scenario, making the scheme applicable in a wide variety of circumstances. The handles controlled by the algorithm are the rotation angles of a series of waveplates and can be used to probabilistically generate arbitrary four-dimensional OAM states. We showcase our scheme on different target states both in classical and quantum regimes and prove its robustness to external perturbations on the control parameters. This approach represents a powerful tool for automated optimizations of noisy experimental tasks for quantum information protocols and technologies.
Quantum-state engineering of high-dimensional states is a pivotal task in quantum information science.1–4 However, many existing protocols are platform-dependent and lack universality.5–10 Conversely, a scheme to engineer arbitrary quantum states, relying on quantum walk (QW) dynamics, was showcased in Ref. 11. QWs are a particularly simple class of quantum dynamics that can be considered to generalize classical random walks.12 QWs have been implemented in experimental platforms ranging from trapped ions13,14 and atoms15 to photonics circuits.16–23 In particular, engineering of arbitrary qudit states has been experimentally demonstrated with QWs in orbital angular momentum (OAM) and polarization degrees of freedom of light.11,24,25
In the paraxial approximation, the angular momentum of light can be decomposed in spin angular momentum, also referred to as polarization in this context, and OAM, which is related to the spatial transverse structure of the electromagnetic field.26–28 In the classical regime, OAM finds application in particle trapping,29 microscopy,30,31 metrology,32 imaging,33–35 and communication.36–40 On the other hand, in the quantum regime, OAM provides a high-dimensional degree of freedom, useful, for example, to encode large amounts of information in single-photon states. Applications include quantum communication,41–45 computing,3,4,46 simulation,47,48 and cryptography.49,50
Optimization algorithms have been proven to be useful tools in tasks such as detection of qudit states51 and quantum state engineering.52,53 Machine learning and genetic algorithms have also found many uses in photonics,54,55 including the use of generative models,56 quantum state reconstruction,57,58 automated design of experimental platforms,59–61 quantum-state and gate engineering,52,53,62–65 and the study of Bell nonlocality.66–68 Moreover, genetic algorithms have been employed to design adaptive spatial mode sorters using random scattering processes.69 Between these types of algorithms, those based on a black box approach have the advantage that they do not rely on specific knowledge of the underlying experimental apparatus. These algorithms are built to tune a set of control parameters based on the information acquired from their environment, without having a notion of what the parameters represent in the experimental platform. This makes such approaches flexible and easier to apply in several scenarios.
Sign up for Advanced Photonics TOC. Get the latest issue of Advanced Photonics delivered right to you!Sign up now
In this paper, we showcase the use of RBFOpt,70,71 a gradient-free global optimization algorithm based on radial basis functions (RBFs),72–74 to learn how to engineer specific quantum states by efficiently tuning the parameters of a given experimental apparatus. The algorithm seeks to optimize cost function , with a set of real parameters determining the state produced by the apparatus. With cost function , we use the quantum state fidelity between the target and current states, as estimated from a given finite number of measurement samples. This makes the cost function inherently stochastic and thus its optimization potentially more complex. As shown in Refs. 70 and 71, RBFOpt is particularly suited to optimize problems with few parameters, with a focus on operating regimes where only a small number of function evaluations are allowed. This is fully appropriate for our scenario, where functions evaluations involve the generation and measurement of photonic states and are thus relatively costly.
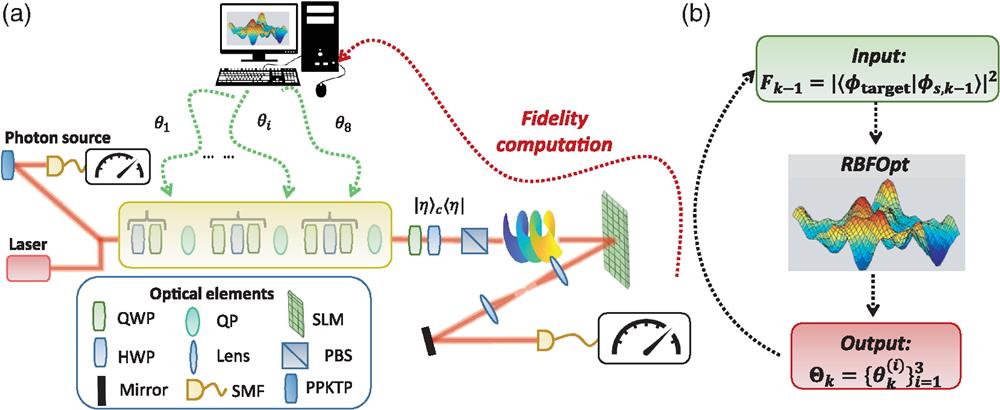
We apply the proposed protocol to an experimental apparatus implementing discrete-time one-dimensional QWs in the OAM and polarization degrees of freedom of light, using a platform based on polarization-controlling waveplates and q-plates (QPs):75 devices able to couple polarization and OAM degrees of freedom. This platform was shown to be able to engineer arbitrary target quantum states.11,24 Such an approach, however, requires full knowledge of the inner workings of the underlying experimental apparatus. This feature makes it harder to flexibly adapt a protocol to the perturbations arising in realistic noisy conditions. On the other hand, an adaptive algorithm operating in a black-box scenario, capable of finding the ideal control parameters independently of the physical substratum it operates in, is intrinsically more resilient to varying environmental and experimental circumstances. To ensure that the performance of our protocol is mostly independent of the specific task to which we apply it here, we avoided fine-tuning of the associated hyperparameters, using the default values presented in Refs. 76 and 77. To further verify the resilience of the learning process, we also performed numerical simulations introducing some noise.
In Sec. 2, we introduce the general optimization framework and the QW model underlying our experimental architecture and showcase the performance of the RBFOpt algorithm in numerical simulations with noise that mimics the experimental conditions. In Sec. 3, we describe the experimental platform and report how our optimization pipeline fares when operating directly on the experimental data. In Sec. 4, we analyze the performance of the protocol when applied to recover the optimal control parameters following sudden changes due to possible external perturbations in order to probe its flexibility under different scenarios. Finally, in Sec. 5, we summarize the results and relate our conclusions.
2 Quantum-State Engineering Process as a Black-Box and Simulated Optimization
In order to study the effects of noise on the RBFOpt algorithm and its feasibility to engineer target quantum states, we apply it to numerically simulated data, reproducing the most likely sources of noise in our experimental apparatus. We study, in particular, the effects of binomial and Poissonian fluctuations on the cost function used by the algorithm.
Generating arbitrary qudit states is a pivotal and ubiquitous task in quantum information science and quantum technologies, with applications ranging from quantum communications1,78–82 to quantum computation.3,4,46,83 The general quantum state engineering scenario we consider can be modeled with a parameterized unitary operation for some set of real parameters . Given a pair of initial and target states and , the state engineering task consists of finding values such that .
To achieve this, we employ a numerical optimization algorithm to minimize the cost function , where is the fidelity between current and target states. The optimization is performed in a fully black-box scenario, meaning we want the optimization procedure to be independent of the specifics of the particular optimization task. In particular, the optimization algorithm can control and optimize only the generation parameters , even if it has no knowledge about both generation of the output state and computation of the cost function . More specifically, we use RBFOpt,70,71 which works by building an approximated model of the objective function—referred to as a surrogate model in this context—using a set of RBFs. RBFs are real-valued functions that depend only on the distance from some fixed point: for some . The goal of the surrogate model used in RBFOpt is to optimally exploit the information collected on the objective function from a limited number of function evaluations. Based on the current estimation of the surrogate model, the algorithm selects new values of the control parameters to improve its current estimation of the model (see Appendix A for further details). This algorithm is an extension of RBF algorithms72–74,84,85 whose performances are enhanced by providing an improved procedure to find an optimal surrogate model. A comparison of its performances with basic gradient-free algorithms is proposed in Appendix C.
In our case, is the evolution corresponding to a one-dimensional discrete-time QW with time-dependent coin operations. In this model, one considers states in a bipartite space , where is a high-dimensional Hilbert space encoding the possible states of the walker degree of freedom, and is a two-dimensional space accommodating the coin degree of freedom. The dynamics are defined as a sequence of iterations, where each iteration is composed of a coin operation followed by a controlled-shift operation . To simulate the experimental conditions, the operators are defined as where , , , and are the control parameters tuned by the algorithm. This parameterization arises from the sequence of three polarization waveplates used to implement each coin operation. The case in which there are only two waveplates, as in the first step (Fig. 1), is simply obtained from having and optimizing the values of and . Denoting with the free parameters characterizing the coin operation at the ’th step, the full set of parameters characterizing an -step QW dynamics is then . The overall evolution operator corresponding to steps is then . Following the engineering protocol presented in Refs. 11 and 24, we project the coin degree of freedom at the end of the evolution so that our target state is .
Figure 1.Experimental apparatus. (a) The engineering protocol has been tested experimentally in a three-step discrete-time QW encoded in the OAM of light with both single-photon inputs and classical continuous wave laser light (CNI laser PSU-III-FDA) with a wavelength of 808 nm. The single-photon states are generated through a type-II spontaneous parametric down-conversion process in a periodically poled KTP crystal. The input state is characterized by a horizontal polarization and OAM eigenvalue . Each step of the QW is made by a coin operator, implemented through a set of waveplates (QWP–HWP–QWP), and the shift operator, realized by a QP. To obtain the desired state in the OAM space, a suitable projection in the polarization space is performed through a quarter-waveplate, a half-waveplate, and a polarizing beam-splitter. The measurement station of the OAM-state is composed by an SLM followed by a single-mode fiber, and the coupled signal is measured through a power meter, in the classical regime, or an avalanche-photodiode detector, in the quantum one. In particular, in quantum optimizations, pairs of photons are generated, and heralded detection is performed, computing the two-fold coincidences between the detectors clicks from the QW evolved photon and the trigger one. The RBFOpt ignores the features of the experimental implementation that is seen as a black box. The algorithm has access only to the parameters of the coin operators and to the computed fidelity. (b) During the iterations of the algorithm, the RBFOpt samples the black-box function to construct a surrogate model that is employed in the optimization. In the ’th iteration, the algorithm receives as input the fidelity computed in the previous iteration and uses it to improve the surrogate modeling. Moreover, the new parameters are computed based on the optimization process. This procedure is repeated for each iteration of the algorithm.
We apply RBFOpt to optimize a three-step QW, where in the first iteration only two free parameters are used. This corresponds to a total of eight control parameters: with . Importantly, the algorithm does not use the information of the correct model of the evolution. This feature permits us to use the present approach in conditions where a model of the experimental setup and noise processes is lacking.
In order to simulate the experimental calculation of the fidelity of a given target state, an orthonormal basis , where is the dimension of the target state and , is built through the Gram–Schmidt algorithm. This approach to estimate the cost function is used to simulate the experimental statistics collection process. Furthermore, we consider both Poissonian [] and binomial [] fluctuations. Poissonian fluctuations are introduced to take into account laser oscillations, whereas binomial fluctuations reflect the probabilistic nature of the measurement setup.
The number of events of the binomial distribution is extracted from a Poissonian distribution with a parameter , while the probability is equal to the fidelity between the state proposed by the algorithm in the ’th iteration and the specific element of the basis. Therefore, for each element of the orthonormal basis, the number of detected events is extracted from the binomial distribution. The noisy fidelity between the proposed state and the target state is then calculated as the ratio between the counts for the element and the total number of counts.
We apply the optimization protocol to 10 random four-dimensional target states, repeating the optimization 10 times for each state. In Fig. 2, we show the value of the cost function—i.e., the infidelity between current and target states—obtained at different stages of the algorithm, up to the fixed maximum number of 1000 iterations. For each iteration number, we report the infidelity obtained as the mean over the average behavior of each of the 10 states. The obtained trend demonstrates that, also in noisy conditions, the algorithm manages to minimize the function, and promising results are obtained. Moreover, we also investigate the scalability of the proposed approach when the number of parameters increases. In particular, we simulated QWs of up to 17 steps (50 parameters) and observed in the investigated regime a linear increase in the mean number of iterations needed to achieve a fidelity value of at least 98%. Further details are reported in Appendix B.
Figure 2.Simulated optimization: infidelity obtained at different stages of the optimization. We test the algorithm on 10 random target states, repeating the optimization 10 times for each. The reported results are obtained as the mean over the average behavior for each of the 10 states. The highest average fidelity obtained is . The shaded area represents the standard deviation of the mean.
The capability of manipulating the OAM of light enabled effective experimental implementations of high-dimensional discrete-time QWs. Therefore, to test experimentally the optimization procedure, we exploit a setup based on the scheme proposed in Ref. 11. In particular, we implemented three steps of a discrete-time QW encoding the coin state in the photon polarization and the walker in the OAM degree of freedom. At each iteration, the coin operation is implemented as a set of polarization waveplates, while the controlled-shift occurs via a QP, a device that acts on the OAM conditionally on the polarization state of light:75where is the OAM value, and and are the right and left circular polarizations, respectively. We implement arbitrary coin operations using two quarter-waveplates (QWPs) interspaced with a half-waveplate (HWP). The output OAM state is then obtained performing a suitable projection on the polarization. This is implemented with a set of waveplates followed by a polarizing beam-splitter [cf., Fig. 1(a)].
To measure the fidelity of the output states, we use a measurement apparatus composed of a spatial light modulator (SLM)86,87 and a single-mode fiber. Since the SLM modulates the beam shape through computer-generated holograms, the operation of this measurement station is equivalent to a projective measurement on the state encoded in the employed hologram. To characterize an incident beam, we thus display on the SLM the hologram corresponding to each element of an orthonormal basis, obtaining the corresponding fidelities. The optimization speed is mainly limited by the measurement process, since significant statistics have to be collected for each projected hologram. Therefore, the use of algorithms able to limit the objective function evaluations, such as those based on the building of a surrogate model, is preferable.
The computed fidelities are then fed to the RBFOpt algorithm to tune the waveplate parameters . To achieve this, the algorithm does not require knowledge on the final target state or on the generation and measurement functioning, as shown in Fig. 1(b). However, since the algorithm has no control over the measurement station, the parameters of the latter have been fine-tuned a priori, and we are confident of the correctness of this step. Therefore, through a dynamic control of the waveplates’ orientation, the algorithm is able to optimize the fidelity value in real time.
To showcase the efficiency of the protocol on our experimental platform, we applied it to engineer different kinds of target states in both the classical and quantum regimes. In Fig. 3, we show the results of running the optimization algorithm on nine different classical states. In particular, we focus our analysis on the elements of the computational basis with and on the balanced superposition of two OAM values. We considered both real and complex superpositions , where with . Moreover, to verify the efficiency of the protocol, we optimize the engineering of a randomly extracted state () in the four-dimensional Hilbert space with no zero coefficients corresponding to each basis element. As shown in Fig. 3(a), optimal average values are obtained in 600 algorithm iterations. In particular, the reported infidelity is computed, averaging over all the experimentally engineered states, and the minimization is compatible with the numerical results reported in Fig. 2. In Fig. 3(b), we report, for each engineered state, the ratio between the fidelities found by the RBFOpt algorithm and those found using the method presented in Ref. 24 to find the optimal values of the parameters. Indeed, as demonstrated in Ref. 24, it is possible to find coin parameters resulting in an arbitrary target state—albeit possibly with different projection probabilities—regardless of the experimental conditions. We find the fidelities reached by RBFOpt to always be higher than the ones computed using the direct method presented in Ref. 24. This is due to the dynamical learning algorithm we employ, which shows higher performances in compensating experimental imperfections. This showcases the advantages of real-time optimization algorithms for quantum state engineering in realistic scenarios. Notably, we extended the experimental demonstration of the protocol, also in the quantum regime of single photon states. We showcased the engineering of the superposition state , and we repeated the optimization 5 times, considering only 100 iterations. No differences are expected between the employment of the laser and single-photon states. In Fig. 3(c), we compared the two performances and observed a good agreement between the approaches. In particular, we reported the optimization curves obtained in the quantum regime plotting the raw data, corresponding to coincidences, and by subtracting the accidental counts. This allows us to distinguish the contribution to the cost function given by either the engineering or the measurement system. The corresponding maximum mean fidelities are and , respectively. In conclusion, since very high fidelities are reached in only 100 steps, the proposed approach can be efficiently applied to quantum situations.
Figure 3.Experimental results: (a) minimization of the quantity averaged over the algorithm performances for different experimental states. The mean maximum value reached is . (b) Ratio between the maximum experimental values of the fidelities resulted after the optimization and the fidelities measured with the theoretical parameters . For each engineered state, the ratio is higher or compatible with the value 1 highlighted by the dashed line. This confirms that the adopted algorithm can reach performances compatible or even superior with respect to the one obtained with the direct method presented in Ref. 24 that considers ideal experimental platforms. In this sense, the algorithm can take into account and compensate for the experimental imperfections. All of the error bars reported are due to laser fluctuations affecting each measurement and are estimated through a Monte Carlo approach. (c) Comparison between the performances reached in 100 iterations using classical or single-photon input states. In yellow is reported the area between the best and worst optimization performed in the classical case. The blue and violet curves are associated with the minimization of the quantity averaged over five different optimizations for the state engineered in the quantum domain. In particular, the raw data are shown in violet, whereas the data after accidental counts subtraction are in blue.
4 Dynamical Learning Protocol with External Perturbations
In realistic conditions, noise is unavoidable, which makes the capability of an algorithm to adapt to real-world perturbations pivotal. To test the robustness of RBFOpt, we have thus added external perturbations to the experimental setup. In particular, we consider a scenario where a sudden perturbation on the parameters is introduced. The algorithm is then tasked with finding again the optimal parameters required to engineer the target state. We assess the performances of the algorithm throughout the optimization, to determine whether a perturbation occurred, and thus the control parameters need to be reoptimized. More specifically:
Therefore, within this approach, the surrogate model is discarded and rebuilt from scratch every time the quantity of interest deteriorates. We performed this check every 10 algorithm iterations in order to have a quick response to perturbations without excessively increasing the optimization time. Indeed, each function evaluation consists of a time-consuming projective measurement with the SLM. For each engineered state, the value of the threshold was fixed by analyzing the fluctuations in the value of the measured fidelity , and these values are reported in Table 1.
Target state
Perturbation probability
Restart threshold
0.0015
0.02
0.0015
0.02
0.008
0.02
0.004
0.02
0.0015
0.05
Random
0.0015
0.02
Table 1. The parameters used in the study of the optimization under perturbations for the engineered states. In the second column, we report the values of the perturbation occurrence probability , whereas in the third column, we report the threshold values used for deciding the algorithm restart.
The considered perturbations act on the HWP of the second step and on the first QWP of the third step. This disturbance consists of a permanent offset in the waveplates rotation of a quantity . In particular, at each iteration and with probability , the orientation of the waveplates optical axis is changed by the addition of an angle sampled from a normal distribution with mean and standard deviation []. We investigated the algorithm response using elements of the computational basis, balanced superpositions of such elements, and a random state. In these cases, several values for the parameter are used. The engineered states and the probability used for them are reported in Table 1.
An example of the dynamics under perturbations is reported in Fig. 4(a); here, the iteration in which a disturbance is introduced is highlighted by a vertical red or green line, respectively, for a shift on the HWP or on the QWP. Instead, the restart of the algorithm is indicated with a vertical orange line. As shown, after the perturbation, the minimum found by the algorithm is no longer the optimal solution, thus triggering a restart. The latter allows the algorithm to reach a new optimal solution in a different environmental condition. Moreover, in Fig. 4(b), the mean ratio between the best fidelity found before and after perturbation is reported for each analyzed state. Knowing that for each state more than one perturbation could be performed, the mean ratio is computed, averaging over all of them. Here, values close to or greater than 1 point out how, thanks to the restart, the algorithm is able to readapt its optimal solution and eventually improve the previously obtained fidelity.
Figure 4.Experimental perturbation results. (a) Optimization under external perturbation of the quantity for the state . The iterations in which a perturbation occurs are highlighted by a vertical red line (second step HWP) or by a vertical green line (third step QWP), and a vertical orange line highlights the iteration in which the algorithm is restarted. (b) Mean ratio between the best value obtained for the fidelity after () and before () the perturbation for the different engineered states. The ratio is close to or higher than 1 for all of them, which showcases that the algorithm is able to reobtain and eventually improve the best value sampled before the perturbation. All of the error bars reported are due to laser fluctuations affecting each measurement and are estimated through a Monte Carlo approach.
The black-box optimization paradigm we discussed is highly flexible, thus promising to be a powerful tool with the potential to be applicable to problems ranging from optimizations of quantum information platforms to the study of nonclassicality.
We have showcased how the RBFOpt global optimization algorithm allows us to dynamically learn the quantum state generation process. In particular, such an approach enables the optimization of target states engineering without having to devise ad hoc platform-dependent protocols. First of all, we dynamically tune the QW parameters in order to optimize the engineering of nine different experimental states in the classical domain. The obtained results turned out to be comparable to the preliminary ones achieved in our numerical simulations. Moreover, the RBFOpt results in higher fidelities than those computed using the direct method of Ref. 24. Therefore, the real-time optimization allows us to take into account and compensate for experimental imperfections. Moreover, we optimized an experimental state using a single-photon source as input to prove the equivalence between the performances reached in the classical and quantum regimes and extend the proposed approach. In order to carry out a complete analysis, and as the adaptation capability of an algorithm is pivotal in realistic conditions, we simulated the effect of real-world perturbations. We have thus applied the optimization algorithm to different states while adding permanent offsets to the orientation of two waveplates in a probabilistic manner. The algorithm manages to adapt itself so as to reach fidelities comparable to those obtained before the perturbation. Our results prove the advantages of adopting real-time optimization algorithms for experimental quantum state engineering protocols. Therefore, practical experimental quantum information experiments can benefit from our work, increasing the engineering performances and employing a real-time fine-tuning of the parameters. The proposed approach can be extended to many different tasks; for example, by suitably modifying the cost function, it is possible to optimize not only the fidelity but also the success probability to generate a target state after the coin projection (see Refs. 11 and 24). Moreover, since the algorithm does not require information on the function to be optimized and on the employed experimental platform, our scheme can find applications in different engineering protocols and quantum information tasks that make use of controllable devices parameters employing, in principle, arbitrary degrees of freedom. Furthermore, going beyond the fully black-box paradigm, in principle, the approach can be exploited also for different protocols. For instance in the theoretical design of experiments, it could be used to optimize the number of quantum gates needed for a specific desired task. Moreover, it could also be used in the calibration of complex optical circuits that find applications in tasks like boson sampling88–91 and in the engineering of multiphoton quantum states.92 In this case, it would be crucial to tailor a suitable cost function.
6 Appendix A: Description of the RBFOpt Algorithm
The RBFOpt optimization algorithm is based on the exploitation of a radial basis interpolant, called a surrogate model.70,71,84,85 Given distinct parameter points , where is a compact subset of , with corresponding cost function values , the associated surrogate model is defined as where is an RBF, , and is a polynomial of degree . This degree is selected based on the type of the RBF function used in the surrogate model. The possible RBF function choices and the degree of their associated polynomial are reported in Table 2. The hyperparameter present in the expression of the RBFs is set to 0.1 by default.76,77 Moreover, the RBFOpt algorithm automatically selects the RBF that appears to be the most accurate in the description of the problem. This selection is made using a cross-validation procedure, in which the performance of a surrogate model constructed with points for is tested at with .70,71
RBF
Polynomial degree
0
1
0
1
Table 2. The RBFs exploited by the RBF algorithm and the degree of the polynomial used in the construction of the surrogate model.70,71,84,85 When , the polynomial is removed from Eq. (3).
The value of the parameters with and the coefficients of the polynomial can be determined solving the following linear system:70,71,84,85where is the space of polynomials of degree less than or equal to , is the dimension of , and are a basis of the space.
At the beginning of the optimization procedure, the surrogate model is constructed from a set of parameter points tunable in number and sampled using a Latin hypercube design.76,77 After that, the interpolant is used to choose the next point, in which the cost function is computed. So, the evolution of the RBFOpt algorithm is composed by the repetition of following steps (say ’th step).
Moreover, during the optimization, the algorithm executes a refinement step, the purpose of which is to improve the optimal solution doing a local search around it through variation of a trust region method.70,71 The refinement step is triggered at the end of point (3) with a frequency controlled by the hyperparameter refinement frequency, with default value equal to 3.76,77
Furthermore, in the study concerning the evolution under external perturbation, we add, as explained in Sec. 4, a new condition for triggering a restart. Beyond the default one, we analyzed the deterioration of the optimal value founded for the cost function and decided whether to restart the optimization. This further check was done every 10 iterations in order to have a faster response to perturbations without increasing excessively the number of function evaluations that experimentally are expensive in time.
7 Appendix B: Scalability of the Optimization Approach
In this section, we study the RBFOpt behavior as the number of parameters of the objective function increases. In particular, we simulated different experimental configurations with QW steps ranging from 3 to 17 and thus considered up to 50 parameters. In fact, with as the number of steps and considering only two waveplates in the first coin, the number of parameters follows the relation:
For each case, we generated at random 50 target states and investigated the optimization procedure stopping the process when a fidelity of at least 98% was reached. In all of the evolutions, we added the same Poissonian and binomial noises described in the main text to the fidelity between the target state and the one proposed by the algorithm.
The computational cost of performing a black-box optimization in high-dimensional spaces can be extracted analyzing how the mean number of iterations changes in relation to the number of parameters. The values obtained averaging over the 50 states considered in our study are reported in Fig. 5 for each simulated configuration. As can be seen from the plot, the RBFOpt algorithm appears to have linear scaling over the parameters number when applied to our implementation. This theoretically showcases the effectiveness of the proposed approach for the engineering of higher dimensional OAM states, and similar behaviors are expected experimentally taking into account the devices response time and adapting properly the related implementation. Finally, while similar behaviors are expected in the regime of a few parameters for higher orders of magnitude, the time needed to perform an iteration step increases drastically. In such regimes, a more refined version of the algorithm might be useful to improve its efficiency.
Figure 5.Scalability: the plot shows the mean number of RBFOpt algorithm iterations as a function of the black-box problem parameters. Here, the optimization process is interrupted when a value of the fidelity between the target state and the one proposed by the algorithm of at least 98% is reached. For each configuration, the iteration values are obtained by averaging more than 50 random target states and simulating experimental noise using binomial and Poissonian distributions. The uncertainty associated with each point is provided by the standard deviation of the mean.
8 Appendix C: Comparison Between RBFOpt and Basic Algorithms
In this section, we perform simulations to compare the RBFOpt algorithm with two basic gradient-free methods suitable to multi-parameter black-box optimization. In particular, we consider both nonadaptive and adaptive approaches.
Regarding the first class, among the simplest is the random search method. As suggested by the name, in each iteration of the optimization processes, the parameters are randomly extracted with a uniform distribution in the parameter space and independently from values assumed in previous steps. The second comparative algorithm is based upon the simplest gradient-free adaptive method known as the Powell method.93 It attempts to find the local minimum nearest to the starting point. Initially, a set of directions is defined, and the algorithm moves along one of them until a minimum is reached. This minimum becomes the uploaded starting point for the following minimization performed on the second direction. After repeating this procedure for each direction, a new direction is defined, and the algorithm proceeds to upload the set of directions.
Figure 6, shows the reported trends corresponding to each compared algorithm obtained from averaging the optimizations of 10 distinct states, each of which is repeated 10 times. The experimental conditions are simulated adding both Poissonian () and binomial fluctuations. As expected, both of the adaptive approaches results are advantageous with respect to the random approach for a considerable number of function evaluations. Moreover, since the RBFOpt spans the whole parameter space through the global steps, its performances are substantially better.
Figure 6.Comparison between different optimization algorithms: the plot reports the simulated performances of three different algorithms averaged over the optimization of 10 different states, each of which is repeated 10 times. Dotted blue, dashed green, and continuous orange lines report the trends corresponding to Powell, random search, and RBFOpt, respectively. RBFOpt is found to perform significantly better than the alternatives in most cases. All curves are generated simulating experimental noise with both Poissonian () and binomial fluctuations.
Alessia Suprano is a PhD student in the Quantum Information Laboratory of Professor Fabio Sciarrino. Her current interests are focused on quantum optics for the implementation and exploitation of quantum walks in the orbital angular momentum degree of freedom of photons and for the study of nonlocality in networks. She graduated in October 2018 from the Sapienza Università di Roma.
Danilo Zia is a PhD student in the Quantum Information Laboratory of Professor Fabio Sciarrino. Currently, he is investigating the applications of quantum walk dynamics in the orbital angular momentum degree of freedom of the photons using machine learning techniques. He graduated in October 2020 from Sapienza Università di Roma.
Emanuele Polino graduated in November 2016 from the Sapienza Università di Roma and obtained his PhD in February 2020. Currently, he is working on photonic technologies for quantum foundations studies and quantum information tasks. In particular, he worked on fundamental tests on wave-particle duality of photons, study of nonlocality in different quantum networks, quantum metrology protocols, generation, transmission, and measurement of quantum states of light carrying orbital angular momentum, and realization of entangled photons sources.
Taira Giordani received her PhD in physics in 2020. She is currently a postdoc in the Physics Department of Sapienza University. Her research focuses on the experimental implementation of quantum walks in integrated photonic devices and the angular momentum of light. In this context, her efforts aim to develop machine learning and optimization methods for the certification and engineering of photonic quantum walk platforms.
Luca Innocenti received his PhD in physics in 2020 from Queen's University Belfast, with a thesis on applications of machine learning to quantum information science. He is currently a researcher in the Department of Physics at the University of Palermo. His research interests focus on devising ways to apply machine learning to quantum physics, with a focus on quantum optics and photonics.
Alessandro Ferraro received his PhD in physics from the University of Milan in 2005. Afterwards, he held fellowship and research positions at ICFO and UAB (Barcelona), UCL (London), and US (Sussex). He is now a senior lecturer and head of CTAMOP research Centre at QUB (Belfast), where he was appointed in 2013. His research focuses on the theory of quantum information with continuous variables and quantum optics, including quantum correlations and machine learning, thermodynamics, and many-body systems.
Mauro Paternostro received his PhD from Queen’s University Belfast before securing fellowships from Leverhulme Trust and EPSRC. He was appointed as a lecturer at Queen’s in 2008, reader in 2010, and professor in 2013. He is the head of the School of Maths and Physics and coleads the Quantum Technology group, where he works on quantum foundations and quantum technologies. His honors include a Royal Society Wolfson Fellowship. He has published more than 200 papers and attracted £20M+ in funding.
Nicolò Spagnolo received his PhD in 2012 in physical science of matter, with a thesis on experimental multiphoton quantum optical states. He is an assistant professor in the Department of Physics of Sapienza Università di Roma. His research interests have been focused on quantum computation, simulation, communication and metrology by employing different photonic platforms, such as orbital angular momentum and integrated photonics.
Fabio Sciarrino received his PhD in 2004 with a thesis in experimental quantum optics. He is a full professor and head of the Quantum Information Lab in the Department of Physics of Sapienza Università di Roma. Since 2013, he has been a fellow of the Sapienza School for Advanced Studies. His main field of research is quantum information and quantum optics, with works on quantum teleportation, optimal quantum machines, fundamental tests, quantum communication, and orbital angular momentum.
[71] G. Nannicini. On the implementation of a global optimization method for mixed-variable problems(2021).
[72] W. Light, M. J. D. Powell. The theory of radial basis function approximation in 1990. Advances in Numerical Analysis, Vol. II: Wavelets, Subdivision Algorithms and Radial Functions, 105-210(1992).
[73] M. W. Müller, M. J. D. Powell et al. Recent research at Cambridge on radial basis functions. New Developments in Approximation Theory, 215-232(1999).
[74] M. D. Buhmann. Radial Basis Functions: Theory and Implementations, Cambridge Monographs on Applied and Computational Mathematics(2003).