
Xu Chen, Dongliang Peng, Yu Gu. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electronic Engineering, 2022, 49(3): 210372-1
- Opto-Electronic Engineering
- Vol. 49, Issue 3, 210372-1 (2022)
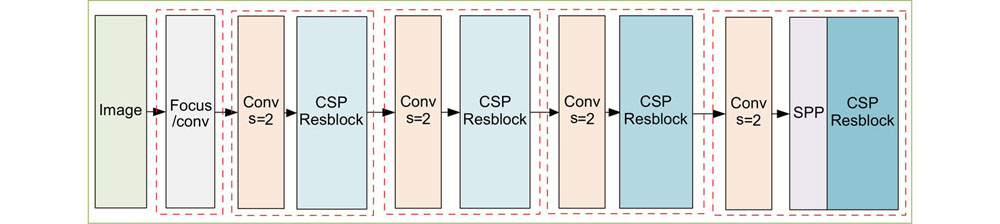
Fig. 1. YOLOv5 backbone network architecture diagram
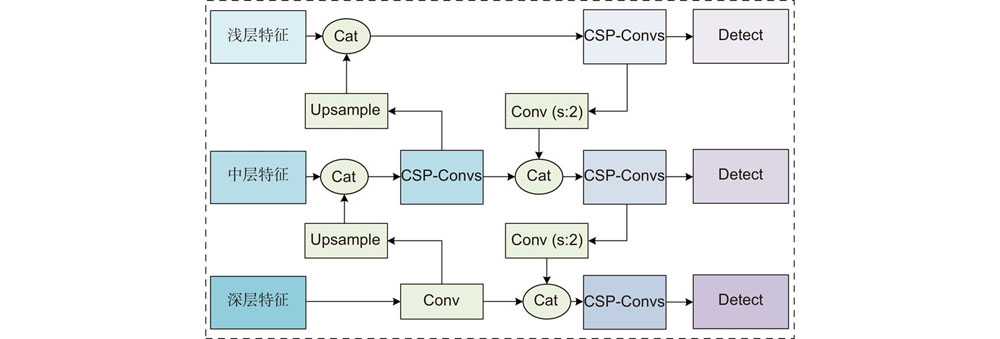
Fig. 2. Structure diagram of feature fusion module
Fig. 3. (a) Res-DConv module; (b) Receptive field mapping
Fig. 4. Improved module structure
Fig. 5. YOLOv5sm+ model architecture
Fig. 6. (a) Total number of category instances on the VisDrone dataset; (b) Classes confusion matrix of YOLOv5m algorithm
Fig. 7. The detection examples of different algorithms in the VisDrone UAV scene. (a) YOLOv5m model; (b) YOLOv5sm+ model; (c) YOLOv5s model
Fig. 8. Comparison of the detection effects of three algorithms in dense vehicle scenes. (a) YOLOv5m; (b) YOLOv5s; (c) YOLOv5sm+
Fig. 9. Detection comparison of improved algorithm in DIOR dataset. (a) YOLOv5s; (b) YOLOv5sm+
|
Table 1. Receptive field analysis table
|
Table 2. Pre-setting anchors in response to the receptive field and down-sampling
|
Table 3. Statistics of different types of objects
|
Table 4. Performance comparison experiment results of depth and width models
|
Table 5. Verification experiment results on Res-Dconv module
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 6. The ablation experiment results of our algorithm modules on the VisDrone dataset
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 7. Detection performance of different algorithms on VisDrone dataset
| ||||||||||||||||||||||||
Table 8. Detection performance of different algorithms on DIOR dataset


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20