
Tianbao Liu, Lingtao Zhang, Wentao Yu, Dongchuan Wei, Yijun Fan. Hierarchical LSTM-Based Audio and Video Emotion Recognition With Embedded Attention Mechanism[J]. Laser & Optoelectronics Progress, 2021, 58(2): 0210017
- Laser & Optoelectronics Progress
- Vol. 58, Issue 2, 0210017 (2021)
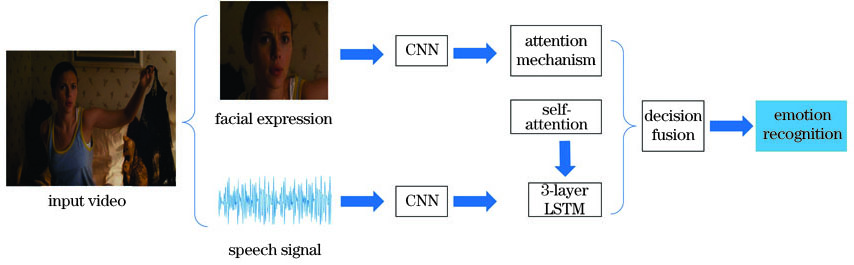
Fig. 1. Flow chart of audio and video emotion recognition system
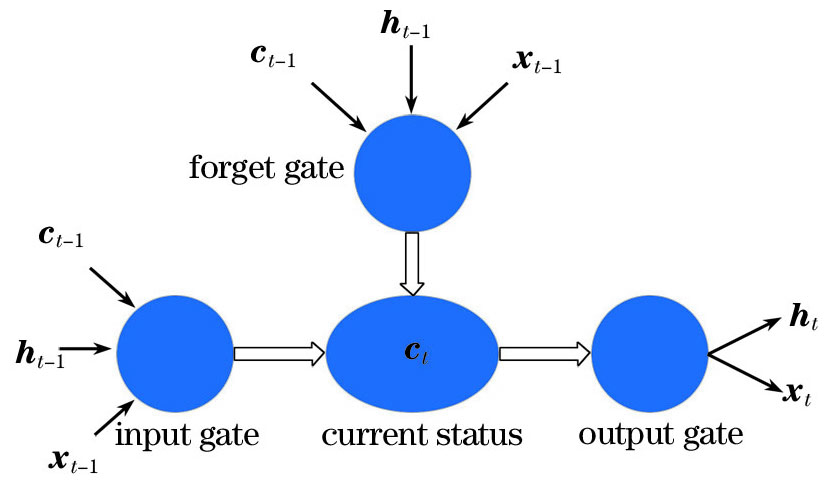
Fig. 2. Structure of recursive neuron
Fig. 3. Schematic of attention mechanism
Fig. 4. Schematic of stacking LSTM model with attention mechanism
Fig. 5. Diagram of video emotion recognition system
Fig. 6. Relationship between LSTM layers and recognition rate
Fig. 7. Performance comparison of different feature fusion algorithms
|
Table 1. Comparison of recognition rate in speech emotion recognition experiment
| ||||||||||||||
Table 2. Recognition rate comparison of hierarchical attention mechanism
|
Table 3. Recognition rate comparison under penalty items
|
Table 4. Recognition rate of facial expression
|
Table 5. Weight settings on three datasets

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20