
Cheng Luo, Man-Kit Sit, Hongxiang Fan, Shuanglong Liu, Wayne Luk, Ce Guo. Towards efficient deep neural network training by FPGA-based batch-level parallelism[J]. Journal of Semiconductors, 2020, 41(2): 022403
- Journal of Semiconductors
- Vol. 41, Issue 2, 022403 (2020)
Abstract
1. Introduction
Deep neural networks (DNNs) have achieved remarkable achievements on various demanding applications including image classification[
However, most of the existing FPGA accelerators are designed for inference with low-precision DNN models, which are trained on high-precision models (e.g. 32/64-bit floating point models) separately on GPU or CPU. Since DNNs employ different precision formats for training and inference, they often need further fine-tuning to achieve acceptable accuracy. The separate training/inference processes make existing FPGA accelerators difficult to support, for example, systems requiring continual learning[
In this paper, we explore the benefits and drawbacks of employing CPU, GPU and FPGA platforms for low-precision training. An novel FPGA framework is developed to support DNN training on a single FPGA with a low-precision format of 8-bit integer (int8). Our objective is to determine if the fine-grained customizability and flexibility offered by FPGAs can be exploited to outperform cutting-edge GPUs in low precision training in terms of speed and power consumption.
To meet our objective, the following challenges should be addressed.
(1) The training process, compared to inference process, brings additional computations and different operations performed in backward propagation[
(2) Existing FPGA accelerators for inference usually exploit image-level and layer-level parallelism for efficient computing. On contrast, FPGA accelerators for training need to proceed with batches of training examples in parallel. Therefore, effective exploitation of the batch-level parallelism should contribute significant acceleration.
(3) Throughput is the primary performance metric of concern for training, while inference is latency sensitive. This cause batch-level parallelism to be neglected at inference accelerators.
To solve these problems, this paper proposes a novel FPGA architecture for DNN training by introducing a batch-oriented data pattern which we refer to as channel-height-width-batch (CHWB) pattern. The CHWB pattern allocates training samples of different batches at adjacent memory addresses, which enables parallel data transfer and processing to be achieved within one cycle. Our architecture can support the entire training process inside a single FPGA and accelerate it with batch-level parallelism. A thorough exploration of the design space with different levels of parallelism and their corresponding architectures with respect to resource consumption and performance is also presented in this paper.
Moreover, we propose DarkFPGA, an FPGA-based deep learning framework with a dataflow architecture. Our approach is built on Darknet framework[
(1) A novel accelerator for a complete DNN training process. A dataflow architecture that explores batch-level parallelism for efficient FPGA acceleration of DNN training is developed, providing a power-efficient and high-performance solution for efficient training.
(2) A deep learning framework for low-precision training and inference on FPGAs called DarkFPGA. We perform extensive performance evaluations for our framework on the MAX5 platform for the training of several well-known networks.
(3) An automatic optimization tool for the framework to explore the design space to determine the optimal parameters for a given network specification.
Additionally, this paper contributes as follows:
(1) Toward the timing problems caused by batch-level parallelism, the pipelining registers are inserted to reduce fan-out, while the super-logic region allocation is proposed to avoid long-wires interconnection.
(2) Training with INT8 weights, instead of ternary weights, is proposed to maintain stable training performance for low-precision model.
The organization of this paper is organized as follows. Section 2 reviews the training and inference processes and some existing FPGA-based accelerators. Section 3 introduces the deep learning algorithm training using low-bits number system. Section 5 proposes the dataflow accelerators designed for GEMM operations. Section 6 discusses the design space exploration for optimizing accelerator design. Section 7 presents our framework of DarkFPGA. Section 8 shows the experimental results, and we conclude the whole paper on Section 9.
2. Background
This section provides a background information of DNN training, emphasizing its difference from inference. Meanwhile, the cutting-edge FPGA accelerators for deep neural network are also introduced here.
2.1. Training versus Inference
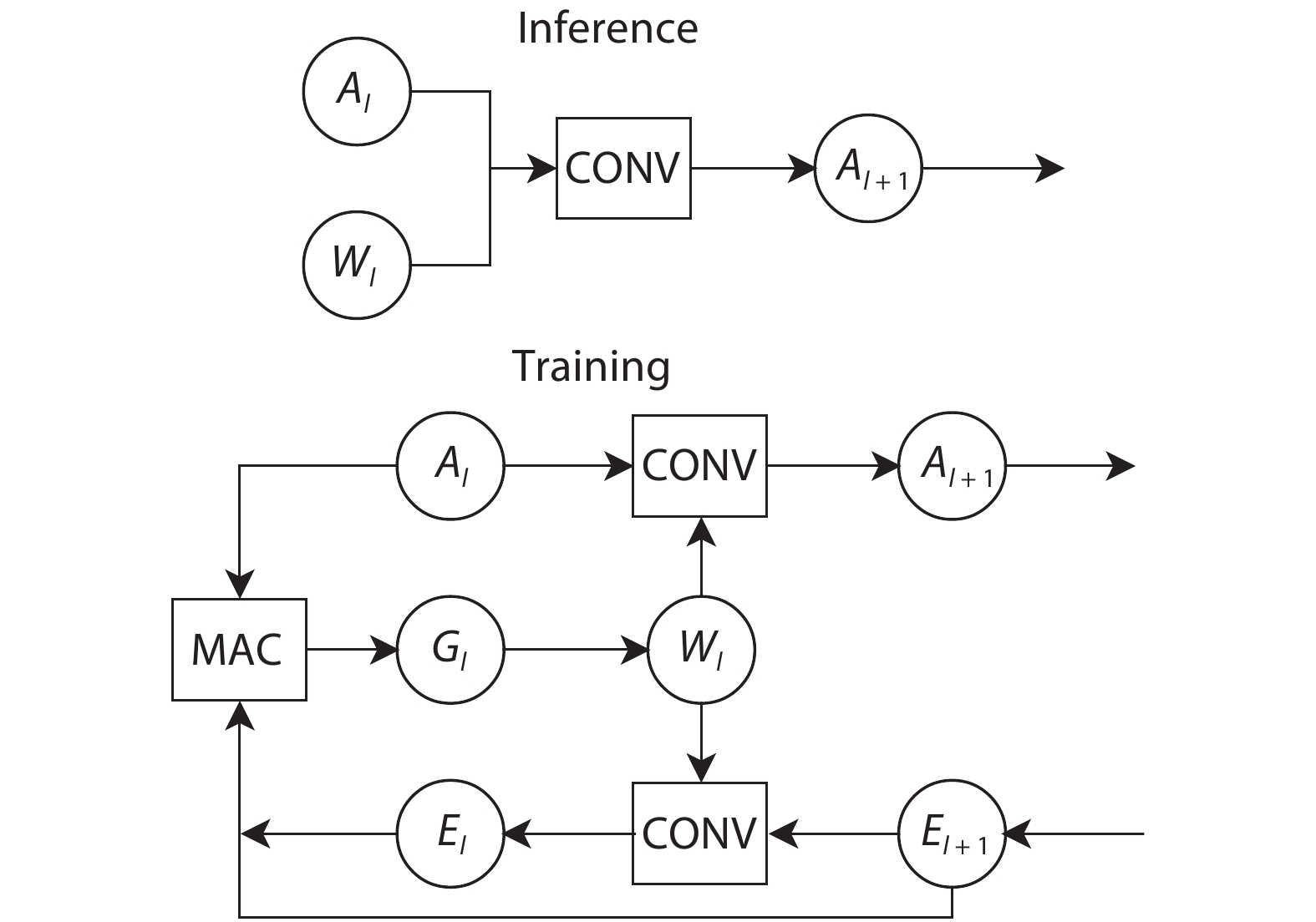
The training consists of forward propagation to compute the loss of the cost functions, and backward propagation to compute the gradients of the cost function, subsequently using gradients to update the model weights for learning desirable behavior. Unlike inference with only forward propagation, training with backward propagation is more computationally expensive and introduce additional operations for backward propagation.
Fig. 1 illustrates the overview of the inference and training of a convolutional layer. For a specific layer
![]()
Figure 1.A overview of inference and training processes on the convolutional layer.
For better understanding, the pseudocode for training a convolutional layer is presented on Algorithm 1, which provides a precise description for the training process. The meaning of the notations can be found in Table 1, where the same set of notation is also followed in the rest of this paper.
2.2. Related works
Most FPGA accelerators mainly focus on the DNN inference acceleration[
Recently, some researchers[
With the objective of speeding up training, this paper studies the acceleration of entire training on a single FPGA, explores the parallelism in training batches, and provides an architecture suitable for bidirectional propagation. We propose a low-precision DNN training framework accelerated on a single FPGA platform. Compared to other frameworks, our proposed customizable FPGA design achieves about 10 times speedup over a CPU-based implementation and is about 2.5 times more energy efficient than a GPU-based implementation.
3. Low-precision DNN training algorithm
Our low-precision training algorithm is developed based on WAGE[
The basic idea of WAGE[
3.1. Shift-based linear mapping
In order to quantize floating-point numbers to fixed-point number, k-bit linear mapping is adopted on WAGE[
Here round function maps quantized floating-point number to nearest fixed-point number. Clip is the saturation function to clip unbounded values to
Considering large hardware implementation overhead for floating-point operations, mathematical equivalent integer operations are introduced in our implementation, where the linear mapping is transformed into shifting from large data format (32-bit integers) to small integers (
Here we replace division operations used in float-point equations d with shift operations with an additional monolithic scaling factor shift for shifting values distribution to an appropriate order of magnitude. The scaling factor shift is obtained in WAGE[
With complex logarithm and exponential operation, the shift(x) requires extensive resources to be implemented on FPGA. To handle this problem, we fine-tune this formula, which is used to obtain the nearest power-of-two value from input
After fine-tuning, the shift factor is obtained from smallest power-of-two value greater than
Here leading1 function detects the position of the most significant "important" bit and return the index of the most significant "important" bit only. After detailed experiments, the fine-tuning has no effect on the convergence of network training but more hardware-friendly for FPGA implementation.
3.2. Quantization details
The quantization operations consist of four operations
3.2.1. Weight QW
Weights are initialized on software platform based on the initialization method of He et al.[
where
3.2.2. Activation QA
For activation, the bitwith of activation would increase after computation. A filter-wise scaling factor
This factor is pre-defined constant for each layer determined by the network structure. Using this factor we can obtain the quantized activation using the following equation:
3.2.3. Error QE
Experiments from WAGE[
where
where
3.2.4. Gradient QG
Since we only preserve the relative value of the error after shifting, the gradients are shifted consequently. Here we first rescale the gradient
where
Bernoulli[
where
4. Date pattern and tilling technique
4.1. CHWB Pattern
For DNN training, the weights, activations, errors and gradients are too large to be stored completely in the on-chip memory, where only a portion of data can be cached on-chip while the remaining is kept off-chip. As the bandwidth between the on-chip and off-chip memory is limited, exploring an optimal data access pattern to for efficient bandwidth utilization is necessary for training.
Currently, the most widely-used data pattern for training on GPUs is referred as batch-channel-height-width (BCHW), which depicts the order of data dimensions in the memory space[
![]()
Figure 2.(Color online) Comparison of BCHW and CHWB patterns.
To handle the problem, we develop the channel-height-width-batch (CHWB) pattern to explore batch-level parallelism without compromising bandwidth utilization on FPGAs. As shown in Fig. 2(b), the elements from adjacent batches are allocated consecutively, which allows the memory interface to simultaneously read multiple training examples. In this manner, CHWB data pattern enables our accelerator to acquire all necessary input data with a single DRAM burst access, and greatly improve bandwidth utilization for FPGA accelerator.
4.2. Tiling
Tiling is a common optimization technique to improve bandwidth utilization for DNN acceleration on resource-limited FPGA devices[
For the CHWB pattern, we consider tiling along four data dimensions: batch tile
Taking convolution to explain how tiling technique works. In Fig. 3, the input matrix is stored using CHWB pattern 3-dimensions
![]()
Figure 3.(Color online) The tiling flow for convolution.
The tiling parameters
5. FPGA accelerators for DNN training
In this section, we follow the idea of CHWB pattern and tiling technique to develop the architecture of our training accelerator.
5.1. System overview
A system overview of our FPGA-based training accelerator is presented on Fig. 4, which consists of a computation kernel, a global controller and a DDR controller for off-chip memory transfer. The computational kernel consists of a batch splitter, a set of processing elements (PEs) and a batch merger. When a stream of training batches arrives at the kernel, the splitter divides the stream into multiple parallel streams via shift registers to facilitate batch-level parallelism. The streams are then processed by the PEs in parallel. Each PE involves a general matrix multiplication kernel (GEMM kernel) or an auxiliary kernel to perform training operations. After processing, the streams are merged into a single output stream, then sent to the DDR controller. The global controller is responsible for controlling the behaviour of each computation kernel, including assigning memory addresses for loading/writing data through the DDR controller, enabling special operations required by particular layers, and controlling the direction of the data flow. The CPU sets the network configuration in the global controller before starting training.
![]()
Figure 4.(Color online) System overview.
5.2. Unified GEMM kernel
Fig. 5 presents the architecture of the GEMM kernel, which provides a unified datapath to support the convolutional and fully-connected computations of the forward and backward propagation, as well as the gradient generation. This unified approach employ matrix multiplication to implement for these computations, where only the input/output matrix to/from the kernel needs to be changed. Therefore, we can avoid time-consuming dynamic reconfiguration[
![]()
Figure 5.(Color online) Hardware architecture of GEMM kernel.
Before any computation, the input data streams are stored in the input buffers, which are organized as a double buffer in order to overlap the data transfer and matrix transposition with the computation. As shown in Fig. 6, when the
![]()
Figure 6.(Color online) Input double buffer supporting matrix transposition.
The GEMM kernel fetches data from the input buffers to perform tiled matrix multiplication. The intermediate values during each iteration are stored in the output buffers for the next iteration. The final results are post-processed by the batch merger then transferred back to the DRAM. The details of the tiled matrix multiplication are shown in Algorithm 2. Noted that the shift factor of forward propagation is pre-defined while the the shift factor of backward propagation is obtained from output results. Therefore, the quantization function can be attached after forward propagation to reduce output bandwidth. On contrast, the output results maintain Int32/Int16 format during backward propagation as well as gradients generations, which require quantization with the help of auxiliary kernels.
In order to support different modes of operations for the forward propagation, the backward propagation and the gradient generation, the global controller dynamically re-configures the buffers and data flow on the datapath. Under the control of global controller, the input buffer can be configured to perform on-the-fly matrix transposition for the computation of backward propagation. Furthermore, the multiplexer can be switched to feed the different input streams to their corresponding processing elements, and the demultiplexer can be switched to direct the output stream to the appropriate postprocessing unit.
5.3. Auxiliary kernels
The auxiliary kernels accelerate supplementary operations with batch-level parallelism including im2col, col2im, max-pooling, reshape, summation, nonlinear functions and quantization as well as their backward counterparts (if necessary). These supplementary operations processed independently since they have no learnable weights and occupy only a small amount of total computation.
For various supplementary operations, various types of separate processing units is implemented to support them. In particular, the maxpooling units are responsible for computing the maximum value and corresponding index over a number of neighbor pixels, whereas the backward maxpooling units propagate errors the to chosen index of subgraphs. The im2col expands the input feature map into column vectors, and col2im accumulate column the vectors back to input feature map. The quantization units are designed for casting intermediate variables of errors and gradients generated during backward propagation and gradients generation to low bit-width quantized data (8-bit integer in our design). The summation units simply add two flows together and the reshape units change the location of data in buffers.
6. Design space exploration
This section presents the design space exploration for optimizing the proposed DNN training accelerator. The performance of FPGA implementations is affected by factors including batch tiling size
6.1. Resource modeling
There are three kinds of hardware resources in FPGAs: LUT, Block RAM and DSP, which form the resource constraints of our design space. We present equations to estimate the utilization for each of them.
First, the resource consumption of the global controller and the DRAM controller is independent of the design parameters, while they are defined as
Second, the resource consumption of the computational kernels is affected significantly by different design parameters. For example, BRAMs are utilized in the input buffers of GEMM kernels and their usage is given by:
where the constants 4 are contributed by the double buffers for both the normal matrix and the transposed matrix.
The multiply-and-add units utilize the DSPs as
where
Finally, an approximate regression model is proposed to estimate the resource consumption of LUT as it is difficult to predict statically:
where
6.2. Bandwidth modeling
There are three streams flowing from the DRAM to the GEMM kernels. In each cycle of convolution, one weight is read from the weight stream while
where
For the auxiliary kernel, the bandwidth requirements are relatively large compared to the small amount of computations performed. In general, it may take one or two input values to generate one or two output values, which handles up to 4 values in each cycle. As these operations benefit from batch-level parallelism, the bandwidth requirements have also multiplied
6.3. Performance modeling
In each clock cycle, a GEMM kernel can accomplish
However, the above formulae are only valid for the sequential case. In fact, in order to support parallel computing, tiled matrices are filled with zero values which may affect the actual computational time. Therefore, the computational time is estimated as:
where function
On the other hand, in each cycle of the auxiliary kernel, frames batches can be handled simultaneously, where the computational time of auxiliary kernels is:
Benefited from our dataflow architecture, the transmission time of the computational kernels can be overlapped by the communication time.
By evaluating the performance of every combination based on the above models, a single-objective optimization tool can be built for minimal execution time as:
where
7. The DarkFPGA framework
For our proposed dataflow architecture, we present DarkFPGA, a hardware/software co-designed FPGA framework for effective training. DarkFPGA framework is built with scalable accelerator architecture which is software-definable to support various DNN networks and different parallel levels through deploying different FPGA bitstreams, where a multi-level parallelism scalable FPGA design is developed. Moreover, a optimizing tool is included to produce optimised design for optimised performance based on user constraints.
We automate the process of exploring design parameters for the DarkFPGA framework, which accelerates the entire training process with a unified module on FPGA. Our tool can receive a network description and a training dataset to produce the most suitable parameters for the accelerator. The overview of our DarkFPGA framework and optimizing tool are illustrated in Fig. 7 with six stages:
![]()
Figure 7.(Color online) The DarkFPGA framework.
(1) Parse network description. The tool predicts optimized parameter values and selects a suitable FPGA bitstream to configure hardware.
(2) Allocate device DRAM space for the activations, weights, errors and gradients.
(3) Initialize weights and transfer them to DRAM.
(4) Fetch and transfer the training samples to DRAM. Data reorganization is used to convert training samples into the CHWB sequence.
(5) Launch FPGA acceleration.
(6) Train neural network iteratively. Transfer loss and accuracy information back to the host for each complete training batch.
8. Experimental result
We evaluate our framework on the Maxeler MAX5 platform, which consists of a Xilinx ultrascale+ VU9P FPGA. Three 16 GB DDR4 DIMMs are installed on the platform with a maximum bandwidth of 63.9 GB/s. Our hardware accelerator works at 200 MHz. Maxcompiler 2019.1 and Vivado 2018.3 are used for synthesis and implementation. The VGG-like network[
Noted while our implementation are able to achieve the massive parallelization with dataflow architecture, it may have difficulty in making the timing closure for a high clock frequency, or even passing the place and route. This is partly because these direct interconnects become long wires when the DSP blocks are distributed among the whole FPGA chip, and large-scale data reuse between DSP blocks introduces large fan-out[
8.1. Exploration of DarkFPGA performance
Based on the discussions in Section 5 and Section 6, the performance of DarkFPGA is significantly determined by the tile sizes (
The batch tile
The corresponding performance and resource consumption under different design parameters (
![]()
Figure 8.(Color online) Performance and resource consumption experiments under different design space using int8 weights. (a) Computational time. (b) Performance evaluation. (c) Resource consumption.
Therefore, we customize a DarkFPGA design to determine the optimal implementation of the training accelerator when
8.2. Heterogeneous versus homogeneous computing
Some of the existing FPGA accelerators rely on heterogeneous computing to handle auxiliary operations[
In this experiment, the tiling size is set to (
![]()
Figure 9.(Color online) Performance comparisons between homogeneous system and heterogeneous system.
Note that using multi-threaded or high-performance CPU can significantly improve heterogeneous computing performance. However their high power consumption brings a tough challenge for embedded DNN applications.
8.3. Performance comparison with GPU and CPU
Here we compare the performance of DarkFPGA with other platforms like GPU and CPU. All software results are running on an Intel Xeon X5690 CPU (6 cores, 3.47 GHz) and an NVIDIA GeForce GTX 1080 Ti GPU. After finishing the same number of batches, all platforms achieve similar accuracies. Unfortunately, GeForce GTX 1080 Ti does not have native int8 support, we evaluate the GPU performance by limiting the range of float32 number system, instead of actual GPU low-precision training.
Table 3 shows the performance and power consumption, as well as other important metric on different platforms. DarkFPGA can achieve over 200 times speedup over a CPU-based implementation of Darknet and is 2 times slower than a GPU-based implementation of Darknet on overall performance. The average power consumption (13.5 W) of FPGA is obtained by the Maxeler performance monitoring tools. By multiplying time and power consumption, our FPGA-based design is 5 times more energy efficient than GPU implementation of Darknet.
Note that Darknet is a lightweight neural network framework for fast iterative design, which limits the overall performance of GPU and CPU. For fair comparison, we evaluate the training performance on TensorFlow[
8.4. Performance comparison with other FPGA-based training system
Finally, comparisons between out DarkFPGA and other FPGA training accelerators are conducted, in terms of resource utilization, performance and throughput and on Table 4. Since many important matrices are not provided and the models for training are different, comparison between different FPGA-based training accelerator in a fair is extremely difficult and not straightforward. Even in such situation, our DarkFPGA accelerator still show desirable performance. Our design outperforms FPDeep[
These comparisons can somehow show that our DarkFPGA has the capacity to train deep neural network. Our analyses show that the improvement of performance comes from FPGA-based batch-level parallelism. In particular, the dataflow architecture allows us to fully exploit the advantages of batch-level parallelism and maximize throughput with the help of dataflow programming language[
9. Conclusion
This work proposes DarkFPGA, a novel FPGA framework for efficient training of deep neural networks, with a customized low-precision DNN training algorithm. The DarkFPGA accelerator explores batch-level parallelism, which provides efficient training acceleration for both forward and backward propagation on a homogeneous FPGA system. Optimization strategies such as batch-focused data sequence CHWB and tiling strategies are employed to improve overall performance. Furthermore, an optimization tool is developed for determining the optimal design parameters for a specific network description. Future work includes applying DarkFPGA to multi-FPGA clusters, exploring mixed precision and binarised training, and supporting cutting-edge network functions like group normalization and depthwise convolution.
References
[1] Y LeCun, L Bottou, Y Bengio et al. Gradient-based learning applied to document recognition. Proc IEEE(1998).
[2] O Russakovsky, J Deng, H Su et al. Imagenet large scale visual recognition challenge. IJCV(2015).
[3] S Ren, K He, R Girshick et al. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 91(2015).
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19] O Pell, O Mencer, K H Tsoi et al. Maximum performance computing with dataflow engines. High-performance computing using FPGAs(2013).
[20]
[21]
[22]
[23]
[24]
[25] C Zhang, G Sun, Z Fang et al. Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks. IEEE Trans Comput-Aid Des Integr Circuits Syst, 38, 2072(2019).
[26]
[27]
[28]
[29]
[30]
[31]
[32]
[33]
[34]
[35]
[36]
[37]
[38]
[39] M Matsumoto, T Nishimura. Mersenne twister: a 623-dimensionally equidistributed uniform pseudo-random number generator. ACM Trans Model Comput Simul, 8, 3(1998).
[40]
[41]
[42]
[43]
[44]
[45] S Krishnan, P Ratusziak, C Johnson et al. Accelerator templates and runtime support for variable precision CNN. CISC Workshop(2017).
[46]
[47]


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20