
Zhenming Yu, Zhenyu Ju, Xinlei Zhang, Ziyi Meng, Feifei Yin, Kun Xu, "High-speed multimode fiber imaging system based on conditional generative adversarial network," Chin. Opt. Lett. 19, 081101 (2021)
- Chinese Optics Letters
- Vol. 19, Issue 8, 081101 (2021)
Abstract
1. Introduction
Endoscopes are the devices that acquire images or other information through thin tubular structures, which have gradually developed into popular tools in medical and industrial fields[
Some approaches developed from computational imaging[
Generative adversarial networks (GANs) are utilized to optimize the DNN method. GAN was first proposed to get the natural image distribution from a random vector[
Sign up for Chinese Optics Letters TOC. Get the latest issue of Chinese Optics Letters delivered right to you!Sign up now
2. Operating Principle
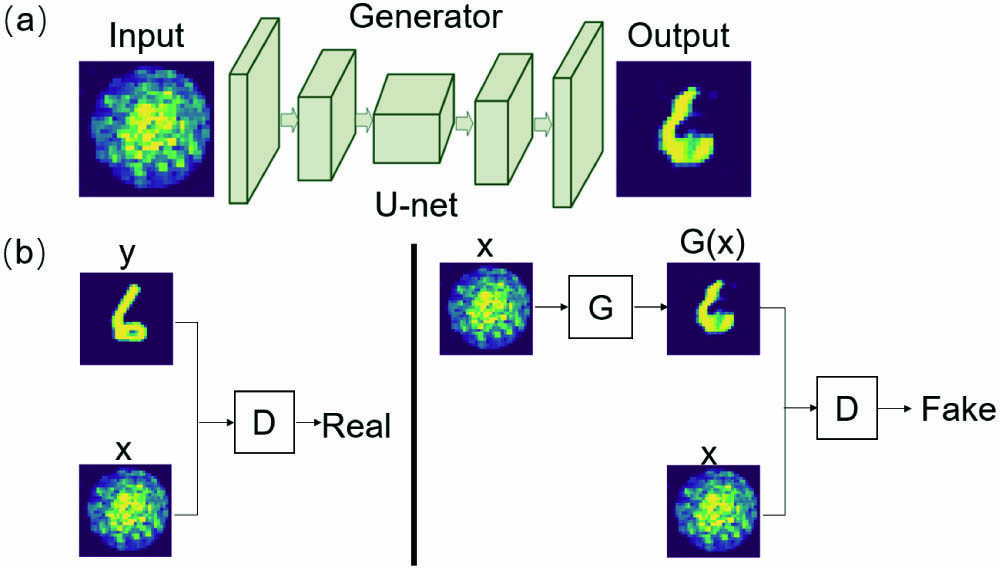
The structure of the conditional GAN is shown in Fig. 1. Figure 1(a) is the network of the generator, which is a U-net in essence. The sizes of the input layer and output layer are determined by the resolution of the input image. The generator is divided into a contraction path and an expansion path in the network structure setting. The discriminator is a convolutional neural network. The input of the discriminator is the ground truth or the output image of the generator splicing with a corresponding speckle pattern, which follows the idea of conditional GANs, as shown in Fig. 1(b). The generator is trained to confuse the discriminator, which aims to make the discriminator fail to distinguish the output of the generator from the real images, while the discriminator is trained to distinguish the output of the generator as fake as far as possible. Unlike the discriminator in the conventional GAN, which determines whether the image generated by the generator matches the distribution of the real sample set, the function of the discriminator in this conditional GAN is to determine whether the image generated by the generator is the same as the label image of the real sample set. The objective of the conditional GAN is defined as[
![]()
Figure 1.Structure of the conditional GAN; (a) architecture of the generator; (b) principle of the discriminator. G, generator; D, discriminator.
Therefore, the final objective is[
3. Experimental Setup and Results
The experiment setup is built as shown in Fig. 2 in order to get training data. A He–Ne laser (Thorlabs HNL210LB) operating at 632.8 nm generates a narrow laser beam. The laser beam illuminates a
![]()
Figure 2.Experiment setup. DMD, digital micromirror device; OBJ, microscope objective lens; MMF, multimode fiber; CCD, charge-coupled device.
The Modified National Institute of Standards and Technology (MNIST) database and Fashion-MNIST database are used as input datasets, respectively. The images with a resolution of
U-net has been proved to solve the image reconstruction problem with the MNIST dataset in MMF imaging system. In this conditional GAN, the structure of the generator is similar to the U-net, as shown in Fig. 3, which contains a down-sampling unit and an up-sampling unit. The down-sampling unit is made of several stride convolutional layers, which uses rectified linear units (ReLU) as the activation function. The features of the input image are concentrated in the bottleneck layer with a resolution of
![]()
Figure 3.Structures of generator in the (a) MNIST experiment and (b) Fashion-MNIST experiment.
The discriminator is a convolutional neural network, which is shown in Fig. 4. The input is the speckle pattern concatenated with the image generated by the generator or the ground truth. The
It is known that an image often has a low-frequency part and a high-frequency part.
| Number of Convolutional Layers | Kernel Size | Stride | Output Resolution | Receptive Field |
|---|---|---|---|---|
| 1 | 1 | |||
| 1 | 2 | |||
| 2 | 2 | |||
| 3 | 2 | |||
| 4 | 2 | |||
| 5 | 2 |
Table 1. Relationship between the Receptive Field and Convolutional Layer
Firstly, the networks are trained with different output resolutions and receptive fields of discriminators for 100 epochs. We collect 500 speckle patterns of the MNIST dataset. All of the programs are run in Python 3.7 environment with NVIDIA Geforce GTX1080 graphics processing unit (GPU). We train our networks with an Adam optimizer, and the learning rate is set as
In the MNIST experiment, reconstruction images with an
![]()
Figure 4.Structures of discriminator in the (a) MNIST experiment and (b) Fashion-MNIST experiment.
![]()
Figure 5.Reconstruction performances with different output resolutions of the discriminator in (a) the MNIST experiment and (b) the Fashion-MNIST experiment.
After training the conditional GAN, we compare its performance with that of U-net. The structure of U-net for comparison is similar to that of the generator. In the U-net of the MNIST experiment, the bottleneck layer is
![]()
Figure 6.Loss for training process of U-net and the conditional GAN in (a) the MNIST experiment and (b) the Fashion-MNIST experiment.
![]()
Figure 7.Reconstruction results of U-Net and the conditional GAN in (a) the MNIST experiment and (b) the Fashion-MNIST experiment.
The number of training datasets is an important parameter that affects the performance of networks. In order to compare the performance of the two networks with different numbers of training datasets, the conditional GAN and U-net are trained by different numbers of training sets for 100 epochs, respectively. Figure 8 shows the comparison of the reconstructions between our network and U-net in the test set evaluated by PSNR and SSIM. The horizontal axis is the size of different training sets. Generally, increasing the number of training sets in both networks can significantly improve the quality of image reconstruction. With the same number of training sets, the reconstruction quality of the conditional GAN is better than that of U-net, which is more obvious with the small training set and complex images. In other words, the conditional GAN only requires smaller training sets than U-net to achieve the same reconstruction quality. It can also be concluded that this conditional GAN has stronger capabilities for feature extraction than U-net.
![]()
Figure 8.PSNR and SSIM at each training set number by U-net and the conditional GAN in (a) the MNIST experiment and (b) the Fashion-MNIST experiment.
4. Conclusion
Considering the structure of the conditional GAN, the generator is essentially a U-net, while the additional discriminator can guide the training of the generator to converge faster. Moreover, the discriminator enables the generator to show better ability in discrimination and constraint for both high- and low-frequency parts of the image to improve the feature extraction ability of the generator. Therefore, smaller datasets can work in reconstruction with the conditional GAN. The experimental results show that this conditional GAN could reconstruct images with fewer training datasets and shows higher feature extraction capability compared with the conventional method of U-net. For both MNIST and Fashion-MNIST, hundreds of training images are reduced by using this conditional GAN in the case of achieving the same accuracy of reconstructed images. In addition, this conditional GAN also has higher feature extraction capability because of the discriminator and the advantage in high-frequency processing. However, the network only performs well for the samples similar to the training data. In the future, it is important to use stronger network or transfer learning methods to improve the generalization ability of models.
References
[1] M. Kyrish, T. S. Tkaczyk. Achromatized endomicroscope objective for optical biopsy. Biomed. Opt. Express, 4, 287(2013).
[2] M. Hughes, T. P. Chang, G.-Z. Yang. Fiber bundle endocytoscopy. Biomed. Opt. Express, 4, 2781(2013).
[3] T. Čižmár, K. Dholakia. Exploiting multimode waveguides for pure fibre-based imaging. Nat. Commun., 3, 1027(2012).
[4] C. Liu, L. Deng, D. Liu, L. Su. Modeling of a single multimode fiber imaging system(2016).
[5] H. Shen, J. Gao. Deep learning virtual colorful lens-free on-chip microscopy. Chin. Opt. Lett., 18, 121705(2020).
[6] X. Wang, H. Liu, M. Chen, Z. Liu, S. Han. Imaging through dynamic scattering media with stitched speckle patterns. Chin. Opt. Lett., 18, 042604(2020).
[7] I. N. Papadopoulos, S. Farahi, C. Moser, D. Psaltis. Focusing and scanning light through a multimode optical fiber using digital phase conjugation. Opt. Express, 20, 10583(2012).
[8] Y. Choi, C. Yoon, M. Kim, T. D. Yang, C. Fang-Yen, R. R. Dasari, K. J. Lee, W. Choi. Scanner-free and wide-field endoscopic imaging by using a single multimode optical fiber. Phys. Rev. Lett., 109, 203901(2012).
[9] D. B. Conkey, E. Kakkava, T. Lanvin, D. Loterie, N. Stasio, E. Morales-Delgado, C. Moser, D. Psaltis. High power, ultrashort pulse control through a multi-core fiber for ablation. Opt. Express, 25, 11491(2017).
[10] R. Di Leonardo, S. Bianchi. Hologram transmission through multi-mode optical fibers. Opt. Express, 19, 247(2011).
[11] B. Rahmani, D. Loterie, G. Konstantinou, D. Psaltis, C. Moser. Multimode optical fiber transmission with a deep learning network. Light: Sci. Appl., 7, 69(2018).
[12] N. Borhani, E. Kakkava, C. Moser, D. Psaltis. Learning to see through multimode fibers. Optica, 5, 960(2018).
[13] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley27th International Conference on Neural Information Processing Systems. Generative adversarial nets, 2672(2014).
[14] P. Isola, J.-Y. Zhu, T. Zhou, A. A. Efros. Image-to-image translation with conditional adversarial networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1125(2017).
[15] A. B. L. Larsen, S. K. Sønderby, H. Larochelle, O. Winther. Autoencoding beyond pixels using a learned similarity metric. International Conference on Machine Learning, 1558(2016).
[16] V. Dumoulin, F. Visin. A guide to convolution arithmetic for deep learning(2016).
[17] D. P. Kingma, J. Ba. Adam: a method for stochastic optimization(2014).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20