
Baurzhan Muminov, Altai Perry, Rakib Hyder, M. Salman Asif, Luat T. Vuong. Toward simple, generalizable neural networks with universal training for low-SWaP hybrid vision[J]. Photonics Research, 2021, 9(7): B253
- Photonics Research
- Vol. 9, Issue 7, B253 (2021)
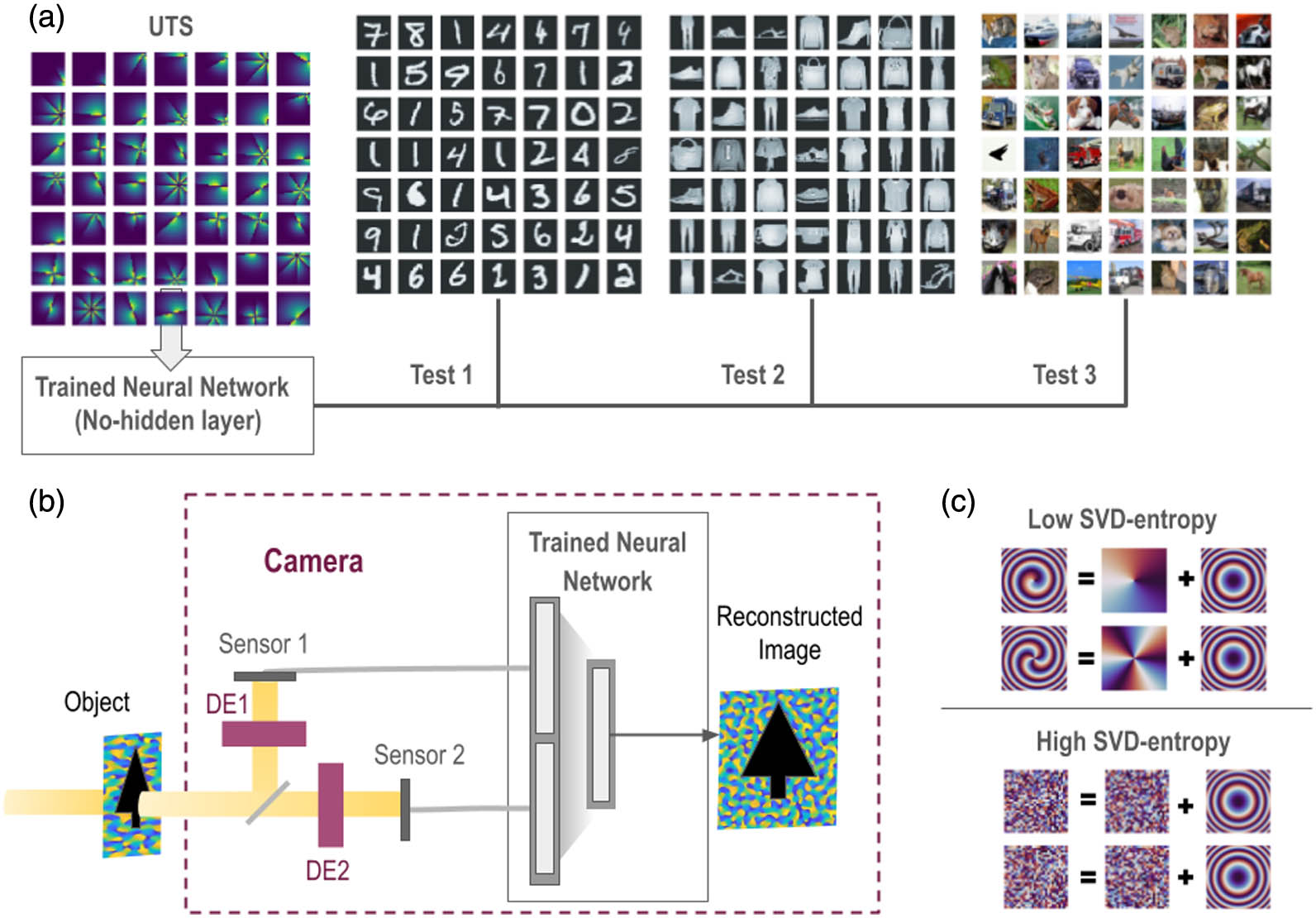
Fig. 1. (a) Project objective: design a generalized training set for a neural network, which can later be used for general image reconstruction without retraining and can operate in real time. (b) Schematic of hybrid vision camera where light from an object is transmitted through a diffractive encoder (DE). Sensors capture two transmitted images that are combined as inputs to the trained neural network, which reconstruct the object from the detector-plane images. (c) This project employs two pairs of diffractive encoders: one with low SVD-entropy (lens and topological charge m = 1

Fig. 2. Reconstructed images from (a), (b), (c) MNIST handwritten and (d), (e), (f) fashion MNIST datasets with random, Fourier, and vortex bases, respectively. The vortex basis provides edge enhancement for object detection. (g) Ground truth and (h) reconstructed images from the CIFAR-10 dataset using the vortex training bases and a vortex mask as the encoder.
Fig. 3. (a)–(c) Sample training images X R X F X V
Fig. 4. (a) Single “hot” pixel response of the random model and (b) single-pixel response of the vortex model, which demonstrates sharp edges and resolves high-contrast objects. (c) Comparison of reconstruction error for different levels of noise given high-entropy random UTS and random mask and lower SVD-entropy vortex UTS and vortex mask. This error corresponds to the scenario in which shot noise dominates the background noise.
Fig. 5. (a) SVD-entropy of a structured pattern composed of the phase of a vortex (modulus 0, 2π w 2 w 2 = 5 × 10 − 3 , 5 × 10 − 2 , 5 × 10 − 1 X V X F X R
Fig. 6. (a) Schematic of experimental reconstruction with UTS. There is no spatial filter or polarizer, images are noisy, and at this wavelength, the modulation dynamic range is only α = π

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20