
Chunyou Su, Sheng Zhou, Liang Feng, Wei Zhang. Towards high performance low bitwidth training for deep neural networks[J]. Journal of Semiconductors, 2020, 41(2): 022404
- Journal of Semiconductors
- Vol. 41, Issue 2, 022404 (2020)
Abstract
1. Introduction
The past years have seen a great success of deep neural network (DNN), especially when it comes to using the CNNs for typical computer vision tasks, such as image classification, pattern recognition, object detection and so forth. However, one commonly ignored fact is that, in the most cases, such remarkable performance is obtained at the cost of huge consumption of computing resources. With the topology of neural network going deeper, the case could be even worse. Take the CNN model from ILSVRC[
Recent works on model compression basically lie in two categories: pruning and quantization. Pruning means that there is sufficient redundancy in common DCNN models[
As for quantization, instead of using single-precision floating-point format, it represents weights (W), activations (A) and gradients (G) with limited numerical bit-width. In this way, quantized networks are enabled to replace the time-consuming floating-point processing elements with integer-based arithmetic units, therefore the amount of operations can be dramatically reduced. In the meanwhile, as a byproduct of limited bit-width representation, the demand for storage will shrink greatly, which is quite an appealing feature since the size of parameters in recent networks can be as large as ~10 M. Based on the way of generating quantized neural network parameters, related works can be further classified into two types: quantizing with pre-trained networks and training from scratch[
In the era of IoT, deep learning techniques have been expected to be applied in wide industrial scenarios, yet high power demand and poor energy efficiency remain main barriers for its popularization. Quantized neural networks provide a promising solution to solve the problem. In this work, we aim to develop a quantized training flow with most of the parameters quantized to 8 bits and train the network from scratch under a very limited classification accuracy degradation. Our contributions can be summarized as follows:
(1) We achieve quantized neural networks for training from scratch with limited classification accuracy degradation for CNN.
(2) We evaluate the quantization scheme on a RNN model and obtain very similar outcome to its single-precision counterpart.
(3) We develop a FPGA prototype to validate the feasibility of the proposed scheme and evaluate the resource usage.
A lot of experiments are performed on prevalent state-of-the-art DNNs and datasets. It is demonstrated that we achieve 0.12% top-1 accuracy drop for ResNet-20 on Cifar-10 dataset. We achieve 0.42% top-1 accuracy drop for AlexNet. We achieve 1.31%, 1.92% top-1 accuracy drop for ResNet-50 and Inception V3 models, respectively. As for the prototype, the synthesis results show that we reduce the DSP usage by ×106, we reduce the BRAM usage by ×1.97, we reduce the FF usage by ×6.23, we reduce the LUT usage by ×2.9. Besides, for translation models, we achieve an 8-bit GNMT model with 24.05 BLEU, which is close to 24.46 achieved by a single-precision model.
2. Quantization methods
Among all quantization methods, the basic procedure to quantize a given vector (or tensor) x is to perform a transform function
In this section, firstly, the details of the DFP quantization algorithm are provided, including the basic principles of updating scale integers and the bit-width settings in the MAC operations and back propagation datapath. Secondly, some other typical quantization methods are introduced and analyzed to form a comparison to DFP. The strengths and weaknesses of different quantization methods are pointed out respectively.
2.1. Dynamic fixed-point (DFP)
2.1.1. Algorithm description
Among all types of layers in DCNN, convolution layer and fully-connected layer account for more than 90% of the computing time[
Given the scale e, the original tensor in 32-bit floating-point format is quantized to 8-bit DFP by approximating each floating-point number to the closest representable DFP number, i.e.
The scale integer
Algorithm 1 Dynamic fixed-point
Inputs: tensor x to be quantized, scale integer ei w.r.t x in the ith iteration, overflow rate rmax
Output: updated scale integer
1: compute the overflow rate
2: compute the overflow rate
3: if
4:
5: else if
6:
7: else
8:
9: end if
To be more concrete, we set the overflow rate
Then, with the quantization bit-width n, let S denote the interval
Similarly, one can compute the overflow rate of 2x. In this way, DFP guarantees that the scale integer
2.1.2. Bit-width settings
Both convolution and fully-connected layers are based on the multiply-and-accumulate (MAC) operation. Although designing an algorithm that performs both multiplication and accumulation in 8-bit is certainly beneficial, we choose to perform 8-bit multiplication and 32-bit floating-point accumulation. Since quantized networks mainly aim to reduce the consumption of computing resources, the priority lies in the optimization of 32-bit multiplications, while the overhead of 32-bit addition is significantly smaller and thus acceptable. In this way, useful information can be preserved with a minimized computation workload to enable effective network learning.
In terms of the back-propagation data path, all parameters are kept in 32-bit floating-point for gradient descent and update. However, following the spirit of minimizing computation complexity, we ensure that the operands of tensor multiplication are represented in 8-bit DFP. For example, considering the gradient with respect to the weight in a convolution layer, which can be generated by the following formula[
Here, the activation
To sum up, DFP algorithm is hardware-friendly because the quantized tensors can be represented with pure integers, which serve as the operands in MAC operations, while the quantization process itself introduces no complex floating-point operations like multiplications or divisions.
2.2. Comparison with other quantization methods
Apart from DFP, various quantization methods have been emerging over these years. In some quantization methods, the numerical resolution between adjacent symbols of the codebook is fixed, whilst in some others, it varies according to the mapping function. Accordingly, a method can be categorized as either linear quantization or non-linear quantization.
2.2.1. Linear quantization
The linear quantization is a method where the resolution is fixed under the input tensor x. Intuitively, to approximate x with a finite codebook, the discrete values can be uniformly appointed over the range between its smallest and biggest entries. This can be expressed as the following formula[
Here, Round() is the rounding function, which will be explained in Section 3. step is the fixed interval value between adjacent discrete values and is computed given the input tensor x and the quantization bit-width n:
Apparently, such a basic linear quantization method enables to fit the value of input tensor automatically without the extra concern about dealing with an overflow. However, the method is inevitably sensitive to any outlier in the input tensor. For instance, if the biggest entry deviates from the second biggest entry too much, the above-mentioned method will suffer from severe quantization noise.
2.2.2. Non-linear quantization
In contrast, the interval values between adjacent discrete symbols are different in non-linear methods. Logarithmic quantization[
Here, the quantization function performs element-wise operations. That is, for each entry of the input tensor x, the function treat it respectively. The sign function
The ultimate goal of logarithmic quantization is to replace the complicated MAC operation with simple bit-shift, which is extremely cheap in digital circuit design. Undoubtedly, logarithmic quantization helps to speed up the MAC operations greatly, however, according to the experimental results reported by Ref. [13], the drop of classification accuracy is typically greater than other methods. Moreover, the logarithmic arithmetic itself is intrinsically not hardware-friendly, which sets a barrier for deployment in embedded systems.
Other non-linear quantization methods introduce different ways to establish the mapping from the symbols of the "codebook" to real values. Some use explicit functions, like the tanh function that is used to quantize weights in DoReFa-Net[
In general, although non-linear methods have their unique advantages, the incurred non-linear operations are too expensive in most cases. Under a fixed quantization bit-width, linear methods could bring a better trade-off between the performance and hardware resources cost.
3. Stochastic rounding
Obviously, with the reduction of bit-width, the numerical resolution inevitably goes down to some extent. In fact, the quantization function can be conceptually decomposed into two separate steps. In the first step, as is aforementioned in Section 2, the vector x is mapped to a proper interval via scaling
Following the notation of the Number Theory, we divide the scaled tensor
Actually, the integer part
After re-scaling the original tensor
3.1. Rounding function
Apparently, the most intuitive way to approximate a fraction value is nearest rounding (NR), which means the outcome will be the closest representable discrete value:
However, nearest rounding may incur severe quantization noise, which can be the major factor influencing the performance of quantized networks. To address this issue, Stochastic Rounding (SR)[
Generally, the target of rounding functions is to convert the scaled vector
3.2. Stochastic rounding: implementation
Despite the fact that SR is not hard to understand, to implement it could be another problem, as a 1-bit random number generator with a floating-point possibility value will be needed. Needless to say, such a module would be a huge challenge for hardware designers, especially for those who wish to get rid of floating-point arithmetic. However, if we think about the SR carefully, the randomness within rounding possibilities can be exploited in another equivalent way. Consider a random value that obeys the uniform distribution:
Then the SR function can be equivalently expressed as[
It should be noted that the equivalence can be easily proved statistically. Consider the value of
In this way, the SR function can be further expressed as following:
This is exactly the same as the original definition. To some degree, the merit of adopting additive uniform noise
3.3. Stochastic rounding analysis
Recently, stochastic rounding has been widely accepted as an effective strategy to acquire better performance in quantized DCNNs[
As is claimed in DoReFa-Net[
To better understand the mechanism, consider a toy example where
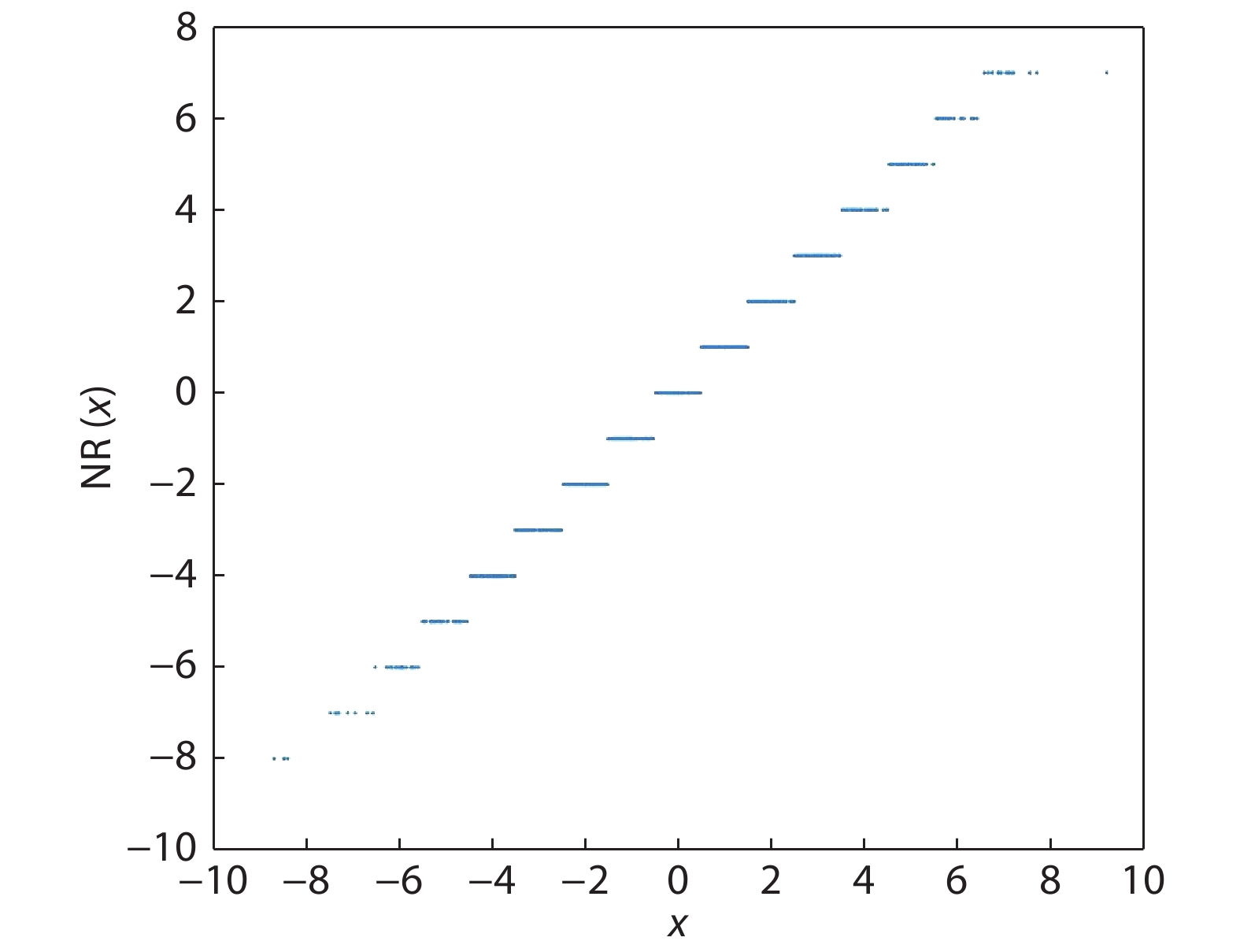
We take X as an example to simulate the scaled parameters within the quantized DCNN. Assume that the quantization bit-width is 4, so we have 16 discrete outcome in total. During simulation, we generate 1000 value according to the normal distribution which are then taken as the input of both NR and SR. Figs. 1 and 2 summarize the results of simulation.
![]()
Figure 1.NR simulation.
![]()
Figure 2.SR simulation.
As is depicted in Figs. 1 and 2, SR enables an input scalar to have multiple corresponding symbols in the codebook, which essentially enhances the flexibility of quantization. Unlike NR which deterministically generates the outcome, SR randomly determines whether to round up or down. Most importantly, it should be noted that SR helps to compensate the vanished values, which is particularly significant in gradient quantization. Consider an item of a gradient tensor whose value lies in the interval (
To further evaluate the influence of different rounding functions, we carry out experiments on AlexNet and ResNet18 to compare the classification accuracy with NR and SR, respectively. In order to provide a fair comparison, we guarantee that all the training hyperparameters are the same and the only difference is the rounding function. The corresponding results are summarized in Table 1.
As is shown in Table 1, rounding function can affect the classification accuracy greatly in AlexNet, which is consistent with our analysis and simulation. We also notice that rounding function has a relatively slight impact on ResNet-18, which is probably the consequence of the residual block that enhances the gradient value in back propagation.
4. Experiments
In this section, the proposed fully quantized network is evaluated on several prevalent CNN models and datasets. Furthermore, we have performed evaluations on some translation models to study the feasibility of limited precision training on other tasks. Our implementation is released in PyTorch.
4.1. CIFAR-10
With 50 000 training images from 10 categories and 10 000 validation images, CIFAR-10 is chosen as a small-size dataset to test the performance of quantized models. We quantize all parameters (W, A, G) using 8-bit DFP in both forward pass and backward pass. All parameters are rounded with NR, except for the gradients exploiting SR. A single NVIDIA GeForce GTX 1080Ti GPU card is used for execution and the batch size is 128. The initial learning rate is 0.1, then decay in cosine annealing manner over 150 epochs. We adopt SGD optimizer with the momentum value being 0.9. We use weight decay as well and the value is set to
It can be concluded that fully quantized networks can achieve almost identical classification accuracy to its single-precision counterparts, even in deep networks like ResNet-56. We believe that such results mainly benefit from the small size of CIFAR-10 dataset and the corresponding limited number of classification categories. To test the stability and performance of fully quantized networks, the evaluation on a larger dataset would be more effective.
4.2. ImageNet
ImageNet (ILSVRC2012) is another benchmark chosen in our evaluations, which has ~1.28 × 106 training images from 1000 categories and 50 000 validation images. Similarly, we quantize all parameters (W, A, G) using 8-bit DFP in both forward pass and backward pass. All parameters are rounded with NR except for the gradients, which adopt SR. Since images in ImageNet dataset belong to as many as 1000 categories, the average predicted probabilities will be two orders of magnitude smaller than those in CIFAR-10. To cope with this issue, we set the quantization bit-width in the last fully-connected layer to 16-bit, such that the codebook is expanded significantly and the extremely small values can be approximated more precisely.
A group of 8 NVIDIA Tesla V100 GPU cards are used for execution and the batch size is 256 (
As can be observed from Table 3, fully quantized networks targeting ImageNet suffer from greater accuracy degradation. With the topology going deeper, the degradation could be even larger. Unfortunately, there are very few related works to compare with, since many works on low-precision networks are merely quantized on the inference phase. As for fully-quantized networks, some use very different bit-width for W, A and G.
We noticed that in DoReFa networks, there is one instance of AlexNet where W, A and G are all quantized with 8-bit and the ultimate accuracy drop is 2.9%. In our experiment, we achieve only 0.42% accuracy drop. Please note that in terms of full-precision AlexNet, our accuracy is slightly lower than that given by DoReFa-Net. The resaon is that our network is consistent with the official implementation from PyTorch library[
To be more specific, DoReFa-Net adopted linear quantization for the gradient, which is similar to the aforementioned linear method. In practice, such method can lead to significant deviation caused by some outliers, especially when it comes to the gradient. Consequently, the quantized gradient makes it more difficult to converge, which leads to higher drop in classification accuracy.
4.3. Translation model
To demonstrate that our quantized training framework can be applied to deep networks other than CNNs, we implement a recurrent neural network (RNN) using DFP. We consider a GNMT model[
5. FPGA prototyping
5.1. Whole structure
According to the proposed quantization algorithm, we implement the FPGA prototype using Vivado HLS. The design consists of a central controller and several modules corresponding to different layers. We adopt the layers in Caffe framework. There are totally eight types of layers, namely convolution, batch normalization, scale, relu, pooling, element-wise (eletwise), fully-connected, and softmax. For each type of layer, different modules handle the forward pass, backward pass, weight update and bias update, etc. The central controller coordinates the execution of all the modules in a layer-by-layer fashion. Fig. 3 shows all the modules we have implemented to support the popular neural networks. Totally 21 modules are implemented. Each kind of layer holds a forward module and a backward module for activation and gradient calculation in the forward pass and backward pass, respectively. Only convolution, fully-connected and scale layers have the additional weight and bias update modules since they are equipped with weights and bias. Only one module handles the softmax related calculation. The softmax module takes the activation from its preceding layer as input, calculates the gradients for back propagation according to the ground-truth labels, and generates the softmax outputs.
![]()
Figure 3.Execution modules.
The whole design structure is shown in Fig. 4. The instruction table defines the information for execution of each layer. During training, the central controller fetches the instruction for one layer each time and activates the corresponding modules. After the modules complete execution, the central controller fetches the instruction of the next layer, and coordinates the execution in such a layer-by-layer fashion. In the forward pass, the central controller fetches the instructions from smaller index to larger index, where the smaller index indicates the layer close to the beginning of the neural network. After the forward pass, the central controller will start the backward pass to fetch the instructions from larger index to smaller index, so that the layers can be executed reversely for back propagation. In the forward pass, the forward module is activated for the layer while in the backward pass, the backward module, weight update module and bias update module will be activated one by one. At a specific time spot, only one module is running in our design. During the execution of each module, the module will get the address offset for its related data from the central controller according to the corresponding instruction. The module loads and stores its related data, such as the activations, gradients, weights, bias, etc., from and to the off-chip DDR through the load and store interface during execution.
![]()
Figure 4.Whole design structure.
5.2. Instruction table
The instruction table is stored as an array to define the neural network structure, where each row of the array is one instruction and corresponds to one layer in the neural network. The content of the instruction indicates the specification of the layer. Each instruction specification contains the information for the type of the layer, the parameters of the layer including channel numbers, padding size, stride size, kernel size, etc., the top and bottom layer ID connected to this layer, etc. Through the top and bottom layer specification, the connections in the neural network can be defined. All the related data for each layer including the activations in the forward pass, the gradient in the backward pass, the weights and the biases are stored in the off-chip DDR with specific address offsets. The address offsets are also contained in the instruction table, so that the corresponding module can access the related data in the DDR. For the layers with direct connections, the address offset of their input and output data are the same, so that the data communications between layers are achieved in a shared memory way. We develop a compiler to compile the network specification from an Caffe prototxt file into the instruction table. A Caffe prototxt file defines the network structure with specified layers and their connection relationships. During the training, when the central controller activates each module, it will also set the required parameters for the module from the instructions, such as channel numbers, padding size, stride size, kernel size, etc.
5.3. Data format
According to our algorithm, we keep each weight and bias as two versions, floating-point and 8-bit dynamic fixed point. Floating-point version is used to be updated in the backward pass for the accuracy, then it is quantized to 8-bit for all the other computing with increased computing efficiency. The activations in forward pass and gradients in backward pass are represented in 8-bit dynamic fixed point for most layers, which is strictly in consistency with our PyTorch implementation. Therefore, in the forward pass and backward pass module, the inputs are all 8-bit dynamic fixed point data and the calculation can be simplified to 8-bit operations. Then the results are quantized back to 8-bit dynamic fixed point data as the output from the module. For each weight and bias update module, the gradients and activations used as the calculation input have been already quantized into 8-bit dynamic fixed point in previous forward pass and backward pass executions. These 8-bit data are used to calculate for updating the 32-bit floating point weights and bias. After the execution of weight and bias update modules, the corresponding floating point version weights and biases in the DDR will be updated. Then the corresponding weights and bias in 8-bit dynamic fixed point version will be also updated according to the updated floating point version.
We adopt the SGD optimizer with momentum for update, hence a historical value for momentum should be kept for each weight and bias, which is stored in single precision floating-point for accuracy. Through quantization to 8-bit dynamic fixed point, the multiply-and-add (MAC) operations in convolution, fully-connected and scale layers can be simplified to 8-bit calculation with better efficiency in both speed and resource. To further enhance the computing efficiency, the computation-intensive modules are executed with high parallelism in both batch dimension and output channel dimension. For example, in the forward pass module of convolution, the calculation for several images in the batch are executed simultaneously and the results for multiple number of output channels are executed at the same time. For the softmax and batch normalization layers, due to the complex exponential and square root functions, 32-bit floating point data is required to do both the forward pass and backward pass calculation. Since the activations and gradients are 8-bit, for these two layers, we first convert the 8-bit input back to floating point, do the calculation, and then convert the floating point data as 8-bit dynamic fixed point output.
5.4. Module design example
We explore the parallelism in the module design for computing efficiency. For main computing layers such as convolution, fully connected, scale, relu, etc., we perform the parallel execution in two dimensions, the batch dimension and output channel dimension. At the same time, we calculate for PARA number of output channels and calculate for all the images in the batch. Therefore, the parallelism is PARA × Batch Size is our case. Fig. 5 shows the basic structure for the convolution forward pass module as an example. Each execution unit (EU) is in charge of the calculation for one output channel. Inside each EU, Batch Size number of calculations are performed in parallel. Each EU calculates the output at the same (x,y) position in the image simultaneously, thus they can share the input data with different weights and bias. In this way, we can achieve high parallelism with reduced data load overhead. To support such parallelism and batch calculation, we organize the activations and gradients in [height, width, channel, batch] fashion to provide the data loading and storing with more locality for better efficiency. After the calculation, the output data will be passed to the quantization unit before to DDR. The quantization unit will quantize the 32-bit integer result from the MAC operation back to 8-bit dynamic fixed point. The design concept and overall structure of the other modules are basically the same as this example. For some layers, such as batch normalization and softmax, the quantization unit should be also designed at the input buffer to convert the 8-bit dynamic fixed point back to floating-point first for calculation. For the weight and bias update modules, both quantized output for 8-bit version and non-quantized output for the floating-point version will be sent to the DDR.
![]()
Figure 5.Module structure example.
5.5. Random number generator
The random number generators used in the quantization unit for the stochastic rounding are designed as a 16-bit linear-feedback shift register to generate pseudo random numbers with a given seed. The generator is shown in Fig. 6. The 16 bit data is first set to a seed value. Then each time the 16-bit value does a right-shift operation with the XOR result from four of its bits as the new leftmost bit value. Such a linear-feedback shift register can guarantee good randomness. In our design, different random number generators will get different random seeds. Moreover, at each training iteration, the seeds will be reset as different 16-bit random numbers to the whole design as a parameter, to further ensure the randomness. During the experiments, we have also verified the good randomness of the generated random numbers. The quantization follows the stochastic rounding strategy and dynamic fixed point representation. Since stochastic rounding is only needed in the backward pass, the random number generators are only set in the backward modules. After the main calculation of the module, such as the EU parts in the backward convolution module, the calculated results are sent to the quantization unit in a sequential manner. Each result will go through the stochastic rounding using one random number from a random number generator in the quantization unit. Totally, 7 random number generators are needed, which saves the resource usage and reduces design complexity. However, such a sequential quantization design may affect the whole throughput, which can be further improved in the future work.
![]()
Figure 6.Random number generator.
5.6. Implementation results
The whole FPGA design shows the same functionality as the python code, with the same outputs and training ability. We map the ResNet50 design from the Caffe prototxt file onto Vertix Ultrascale+ XCVU9P FPGA with the clock rate being 200 MHz. The observed peak throughput can be as large as 102 GOPS. The resource usage is as in the Table 4. The parallel degree of this implementation is 16 × 16, which means the parallelism is 16 in the batch dimension and 16 in the output channel dimension. All the modules for different layers are implemented on the FPGA at the same time while only one module is running at one time, therefore the peak throughput is limited. Pipelining among different layers in the layer-fusion style can be considered to further improve the design, although which is quite complicated and beyond the scope of this work. Without quantization, the design cannot achieve the parallelism of 16 × 16 due to the lack of DSPs since all the operations are in floating point with the demand of using DSP. Through quantization using 8-bit dynamic fixed point in our design, the resource usage demand is decreased by a large degree to enable larger parallelism.
In summary, DFP quantization reduces the resource usage significantly. For example, for a convolution layer, our design with quantization reduces the number of DSP usage from 5124 to 48 (by 106x), reduces the BRAM block usage from 162 to 82 (by 1.97x), reduces the FF usage from 466926 to 74933 (by 6.23x), reduces the LUT usage from 412630 to 141828 (by 2.9x). Hence, with quantization, our low bitwidth training scheme can explore more parallelism with limited resource to boost the performance. The current FPGA prototyping is relatively simple without further optimization, since our work mainly focuses on the algorithm level. Further optimization of the hardware implementation are left as future work to further improve the throughput.
6. Discussion and future work
In this work, we develop and implement fully quantized DNN with minimum accuracy degradation. We find DFP to be an appropriate quantization method that is both hardware-friendly and well-performed in numerical approximation. Our FPGA based prototype proved that the design works correctly and the training scheme can be mapped to hardware efficiently. The required hardware resource can be dramatically decreased without noticeable drop in performance. However, there is large room to improve the design and hardware implementation in the future works.
7. Related works
The research regarding low precision neural networks has been attractive over last several years. BinaryConnect[
Such results naturally arouse a question: Which kind of parameters (i.e. W, A, G) in neural networks should we allocate more number of bits to prevent severe degradation in accuracy? DoReFa-Net[
In addition, Wage[
In terms of works closely related to stochastic rounding, HALP[
8. Conclusion
In this paper, we investigate various quantization methods to find DFP that is both effective and hardware-friendly. Additionally, stochastic rounding is analyzed through simulation and experiments to uncover the reason behind its success. Most importantly, we build fully quantized neural networks released in PyTorch and evaluated its performance. To the best of our knowledge, we are the first work to achieve 8-bit DCNN as deep as ResNet-50 and Inception V3 with less than 2% accuracy drop. In addition, an 8-bit GNMT model is developed to test its performance on machine translation applications. Compared to the full precision model whose BLEU is 24.46, we achieve a very close 24.05 BLEU on the test set. Moreover, we designed a simple prototype on FPGA by Vivado HLS, which is an essential step towards ultimate deployment of quantized neural networks on hardware. It is demonstrated that our fully quantized network helps to reduce the computing resources significantly. Last but not the least, we realize that there remains problems to be solved, like theoretical analysis of rounding scheme, more effective quantization method, and hardware implementation optimization to be explored to realize an efficient mapping of the whole design on embedded platforms.
Acknowledgements
This work is supported by Huawei.
References
[1] O Russakovsky, J Deng, H Su et al. Imagenet large scale visual recognition challenge. Int J Comput Vision, 115, 211(2015).
[2] A Krizhevsky, I Sutskever, G E Hinton. Imagenet classification with deep convolutional neural networks. Adv Neural Inform Process Syst, 1097(2012).
[3] K He, X Zhang, S Ren et al. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770(2016).
[4] S Han, J Pool, J Tran et al. Learning both weights and connections for efficient neural network. Adv Neural Inform Process Syst, 1135(2015).
[5]
[6]
[7] H Li, S De, Z Xu et al. Training quantized nets: A deeper understanding. Adv Neural Inform Process Syst, 5811(2017).
[8]
[9]
[10]
[11]
[12]
[13]
[14] R Banner, I Hubara, E Hoffer et al. Scalable methods for 8-bit training of neural networks. Adv Neural Inform Process Syst, 5145(2018).
[15] I Hubara, M Courbariaux, D Soudry et al. Quantized neural networks: Training neural networks with low precision weights and activations. J Mach Learning Res, 18, 6869(2017).
[16] S Gupta, A Agrawal, K Gopalakrishnan et al. Deep learning with limited numerical precision. International Conference on Machine Learning, 1737(2015).
[17] Sa C De, M Feldman, C Ré et al. Understanding and optimizing asynchronous low-precision stochastic gradient descent. ACM SIGARCH Computer Architecture News, 45, 461(2017).
[18]
[19]
[20]
[21]
[22]
[23]
[24] M Courbariaux, Y Bengio, J P David. Binaryconnect: Training deep neural networks with binary weights during propagations. Adv Neural Inform Process Syst, 3123(2015).
[25] I Hubara, M Courbariaux, D Soudry et al. Binarized neural networks. Adv Neural Inform Process Syst, 4107(2016).
[26] M Rastegari, V Ordonez, J Redmon et al. Xnor-net: Imagenet classification using binary convolutional neural networks. European Conference on Computer Vision, 525(2016).
[27]
[28]

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20