Author Affiliations
Institute of Remote Sensing and Geographic Information System, School of Earth and Space Sciences, Peking University, Beijing 100871, Chinashow less
Fig. 1. Network architecture proposed by Laina et al.[27]
Fig. 2. Schematics of up-projections. (a) Up-projection; (b) fast up-projection
Fig. 3. Replacing tranditional 5×5 convolution kernels with four small convolution kernels
Fig. 4. Long-tail distributions on depth and semantic labels. (a) Pixel-depth distribution of NYU Depth V2 dataset; (b) pixel-depth distribution of KITTI dataset; (c)(d) pixel-semantic label distributions of NYU Depth V2 dataset (all categories/40 categories)
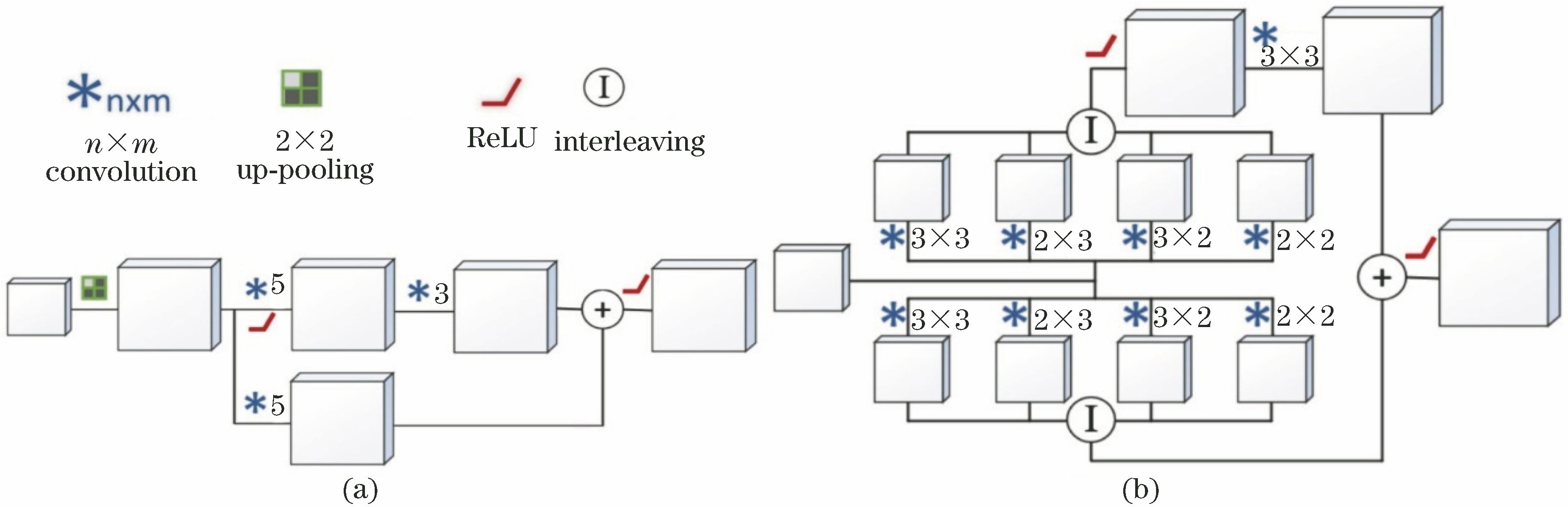
Fig. 5. Schematic of network architecture proposed by Jiao et al.[42]
Fig. 6. Schematics of proposed LSU and SUC connections. (a) LSU; (b) SUC
Fig. 7. Schematic of network architecture proposed by Fu et al.[47]
Fig. 8. Structural schematic of full-image encoders
Fig. 9. Overall flow chart of algorithm proposed by Garg et al.[30]
Fig. 10. Schematics of network architecture proposed by Godard et al[31]. (a) Sampling strategy with left-right consistency; (b) loss function
Fig. 11. Schematic of semi-supervised network architecture and loss function proposed by Kuznietsov et al.[53]
Fig. 12. Schematic of network frame of video depth estimation based on view synthesis[32]
Fig. 13. Schematic of GeoNet network architecture proposed by Yin et al.[59]
| Method | Year | Type | eAbs | eRMS | elg | δ<1.25 | δ<1.252 | δ<1.253 |
|---|
| Method in Ref. [23] | 2014 | Sup. | 0.215 | 0.907 | - | 0.611 | 0.887 | 0.971 | | Method in Ref. [26] | 2016 | Sup. | 0.213 | 0.759 | 0.087 | 0.650 | 0.906 | 0.976 | | Method in Ref. [27] | 2016 | Sup. | 0.127 | 0.573 | 0.055 | 0.811 | 0.953 | 0.988 | | Method in Ref. [61] | 2017 | Sup. | 0.121 | 0.586 | 0.052 | 0.811 | 0.954 | 0.987 | | Method in Ref. [47] | 2018 | Sup. | 0.115 | 0.509 | 0.051 | 0.828 | 0.965 | 0.992 | | Method in Ref. [42] | 2018 | Sup. | 0.098 | 0.329 | 0.040 | 0.917 | 0.983 | 0.996 | | Method in Ref. [45] | 2018 | Sup. | 0.139 | 0.505 | 0.058 | 0.820 | 0.960 | 0.989 | | Method in Ref. [10] | 2019 | Sup. | 0.128 | 0.523 | 0.059 | 0.813 | 0.964 | 0.992 |
|
Table 1. Quantitative evaluation of selected algorithms on NYU Depth V2 dataset
| Method | Year | Type | eAbs | eRMS | elg | δ<1.25 | δ<1.252 | δ<1.253 |
|---|
| Method in Ref. [23] | 2014 | Sup. | 0.190 | 7.156 | 0.270 | 0.692 | 0.899 | 0.967 | | Method in Ref. [26] | 2016 | Sup. | 0.217 | 7.046 | - | 0.656 | 0.881 | 0.958 | | Method in Ref. [53] | 2017 | Semi. (stereo) | 0.113 | 4.621 | 0.189 | 0.862 | 0.960 | 0.986 | | Method in Ref. [31] | 2017 | Unsup. (stereo) | 0.114 | 4.935 | 0.206 | 0.861 | 0.949 | 0.976 | | Method in Ref. [47] | 2018 | Sup. | 0.072 | 2.727 | 0.120 | 0.932 | 0.984 | 0.994 | | Method in Ref. [42] | 2018 | Sup. | - | 5.110 | 0.215 | 0.843 | 0.950 | 0.981 | | Method in Ref. [45] | 2018 | Sup. | 0.113 | 4.687 | - | 0.856 | 0.962 | 0.988 | | Method in Ref. [33] | 2018 | Unsup. (video) | 0.109 | 4.750 | 0.187 | 0.874 | 0.958 | 0.982 | | Method in Ref. [62] | 2018 | Unsup. (stereo) | 0.095 | 4.316 | 0.177 | 0.892 | 0.966 | 0.984 | | Method in Ref. [59] | 2018 | Unsup. (video) | 0.153 | 5.737 | 0.232 | 0.802 | 0.934 | 0.972 | | Method in Ref. [57] | 2019 | Unsup. (video) | 0.139 | 5.160 | 0.215 | 0.833 | 0.939 | 0.975 |
|
Table 2. Quantitative evaluation of selected algorithms on KITTI dataset
| Method | Year | Type | Data type | Loss | Main contributions |
|---|
| Method in Ref. [23] | 2014 | Sup. | RGB+depth | Inference error(original) | First to use deep learning onmonocular depth estimation (MDE) | | Method in Ref. [27] | 2016 | Sup. | RGB+depth | Inference error(berHu loss) | Introduction of residual learning toMDE with optimized up-convolutions | | Method in Ref. [61] | 2017 | Sup. | RGB+depth | Inference error(square loss) | Achievement of end-to-end MDEwith CNN layers fused within CRF | | Method in Ref. [53] | 2017 | Semi. | Binocular RGB +sparse depth | Berhu loss (supervisedloss), image alignmenterror (unsupervisedloss), regularization loss | Introduction of a semi-superviseddeep learning approach of MDE | | Method in Ref. [47] | 2018 | Sup. | RGB+depth | Ordinal regression loss | Ordinal regression method forMDE with dilated convolutions | | Method in Ref. [59] | 2018 | Unsup. | Video | Wrapping loss, depthsmoothness loss,geometric consistency loss | Cascaded architecture to resolve rigidflow and object motion separately indepth estimation from monocular video | | Method in Ref. [33] | 2018 | Unsup | Video | Reconstruction loss, wrappingloss, depth smoothness lossobject size constraints | MDE in highly dynamic scenes withexplicit modeling of 3D motions ofmoving objects and camera itself |
|
Table 3. Summary of selected representative algorithms

![Network architecture proposed by Laina et al.[27]](/richHtml/lop/2019/56/19/190001/img_1.jpg)