AI Video Guide
AI Video Guide  AI Picture Guide
AI Picture Guide AI One Sentence
AI One Sentence
With the continuous development of three-dimensional (3D) acquisition equipment such as 3D Lidar, 3D point cloud data has recently become more accurate and easier to obtain. As the most important representation of 3D data, 3D point cloud is widely used in visual tasks in the fields of autonomous driving, robotics, remote sensing, cultural relic restoration, augmented reality, and virtual reality, among others. Owing to the large amount of original point cloud data and the fact that the acquisition process is easily mixed with noise and outliers, the direct use of the original point cloud data is not effective. Therefore, it is critical to study the processing methods for 3D point clouds.
A point cloud is a collection of spatial sampling points of the target surface properties in the same coordinate system. The sampling points contain geometric information such as the 3D coordinates and size, as well as characteristic information such as the object color and texture features. Traditional 3D point cloud processing methods are based on geometric analyses. Point cloud data are processed by estimating the geometric information such as the normal vector, curvature, and density of the point cloud, and by combining traditional feature descriptors. Although its accuracy is high, it is not suitable for complex point cloud scenes such as large rotations, and the calculation function is extremely cumbersome. Classical machine-learning methods can process 3D data and learn effective feature information; however, machine learning is highly dependent on accurate manual identification features. Massive 3D data not only increase the number of manual labels but also make labeling significantly more difficult than two-dimensional (2D) images. Deep learning methods can train and calculate large-scale data, autonomously learn latent-space features and advanced laws in the input information, and are suitable for processing massive amounts of point cloud data. Although deep learning methods require a considerable time for training the samples to learn the parameter information, the test time is significantly shorter than that of machine learning methods, and the prediction results are more accurate. Considering the irregular, sparse, and uneven internal structure of 3D point clouds, the efficient implementation of 3D point cloud processing based on deep learning has recently become the focus of researchers.Therefore, this study reviews the research progress of deep learning-based 3D point cloud processing methods over the past six years and presents the future research trends, aiming to provide inspiration and ideas for researchers in point cloud processing.
In this study, we focus on deep learning-based 3D point cloud processing tasks and provide a development route for the most commonly used deep learning methods for four point cloud processing tasks over the past six years (Fig.1). The 3D point cloud mainly includes the following four types of processing tasks: 1) denoising and filtering, 2) compression, 3) super-resolution, and 4) restoration, completion, and reconstruction.
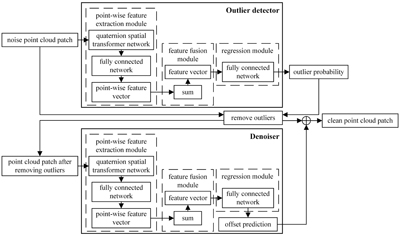
Deep learning methods for point cloud denoising and filtering tasks can be classified into the following five types: CNN-based, upsampling-based, filter-based, gradient-based, and others. PointProNet and GeoGCN learn feature differences based on convolutional networks to remove noise; however, point cloud information is lost during the preprocessing stage. DUP-Net, PUGeo-Net, and PU-GACNet are classic upsampling-based denoising methods that denoise by modifying the feature extractor and feature expander while ignoring certain local features. NPD and PointCleanNet combine filtering ideas with deep learning and can simultaneously achieve noise removal and point cloud geometric feature retention. The Score-based method constructs a gradient field according to the distribution characteristics of the noise point cloud, and the robustness is enhanced; however, relatively few studies have been conducted. NoiseTrans draws on the idea of a Transformer to achieve the effective extraction and retention of fine features in point clouds. Table 2 presents a comparison of the advantages and disadvantages of the common methods.
Deep learning methods for point cloud compression tasks are generalized. According to lossless and lossy compression, they are divided into two categories and analyzed (Tables 3 and 4). The point cloud lossless compression methods, OctSqueeze and VoxelDNN, improve the accuracy of point cloud probability prediction; however, part of the point cloud information is lost. PCGCv2, TransPCC, and SparsePCGC are the typical point cloud lossy compression methods. The point cloud feature is learned through a network structure, which prevents the loss of detailed information and improves the quality of the reconstructed point cloud.
Subsequently, deep-learning methods for point cloud super-resolution tasks are outlined. Classification and comparative analyses are performed for the following four methods: convolutional neural network (CNN), graph convolutional neural network (GCN), generative adversarial network (GAN), and other structures (Table 5). PU-Net and PU-GCN extract rich detailed features based on CNN and GCN, respectively; however, numerous calculations are required. PU-GAN exploits the dynamic adversarial optimization details of the generator and discriminator. MPU and PU-Transformers combine the idea of a 2D super-resolution algorithm with the PointNet structure, which is a new idea worth trying.
The deep learning methods for point cloud restoration, completion, and reconstruction tasks include three aspects, which are image-based, sampling-based, and completion-based, for which a comparative analysis is performed (Table 6). PCDNet reduces the number of computations by extracting 2D image features and deformations. Sampling-based methods use networks to generate dense and complete point clouds. PCN, TopNet, and SA-Net can fill in missing structures with input point clouds; however, completion-based methods are susceptible to incomplete point clouds.
Recently, KITTI, PCN, nuScenes, and other public point cloud datasets and performance indicators, such as CD, P2M, and RMSE, have significantly promoted the in-depth research of point cloud processing tasks (Tables 7 and 8).
3D point cloud processing methods based on deep learning have gradually become an important research direction in the field of computer vision. Although several positive achievements have been made, there is significant room for further development. The following aspects should be considered when conducting in-depth research: the combination of multiple processing tasks, point cloud data feature processing, low-cost network models and hardware devices, and adaptable datasets.