
Weili LIU, Deli ZHU, Huahao LUO, Yi LI. 3D Object Detection with Fusion Point Attention Mechanism in LiDAR Point Cloud[J]. Acta Photonica Sinica, 2023, 52(9): 0912002
- Acta Photonica Sinica
- Vol. 52, Issue 9, 0912002 (2023)
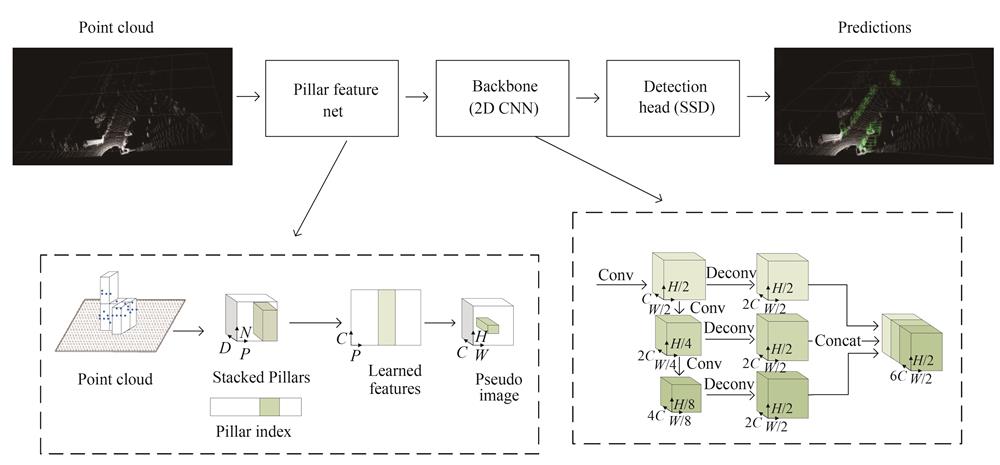
Fig. 1. Overall framework of PointPillars algorithm
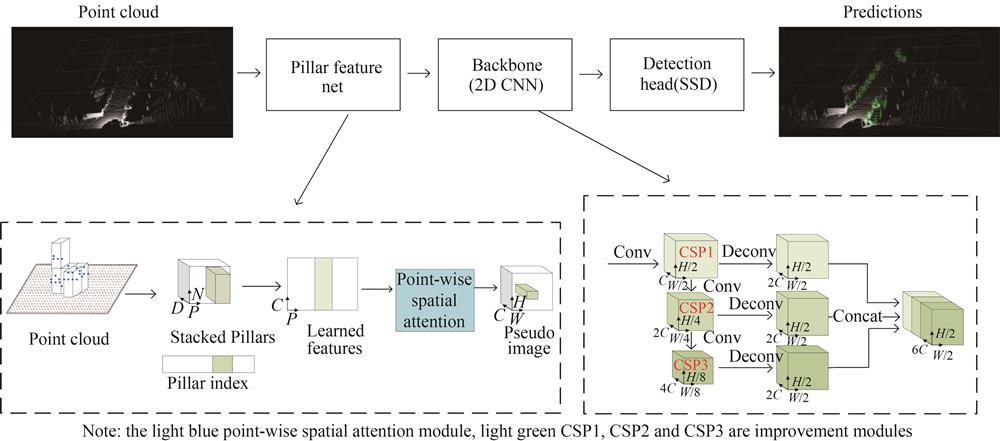
Fig. 2. The overall framework of the improved PointPillars algorithm
Fig. 3. Structure of point-wise spatial attention module
Fig. 4. 2D backbone network structure
Fig. 5. CSPNet,BottleNeck network structure
Fig. 6. Comparison of the visualization results of PointPillars and the algorithm in this paper
|
Table 1. CSPNet network structure of this paper
|
Table 2. Data division in three scenarios
|
Table 3. Experimental environment configuration
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 4. Comparison of AP for different methods(%)
|
Table 5. Inference speed comparison among different methods
| |||||||||||||||||||||||
Table 6. Average precision of 3D detection for ablation experiments in the KITTI test set(%)
| |||||||||||||||||||||||
Table 7. Average precision of detection in the BEV scenario of the KITTI test focused ablation experiment(%)

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20