
Jin Song, Xuemeng Wang, Zhipeng Zhao, Wei Li, Tian Zhi. A survey of neural network accelerator with software development environments[J]. Journal of Semiconductors, 2020, 41(2): 021403
- Journal of Semiconductors
- Vol. 41, Issue 2, 021403 (2020)
Abstract
1. Introduction
Recent years, artificial intelligence (AI) developed at an explosive speed. With the great progress made by the neural network (NN) algorithms, the application scenarios also widely spread, including image processing[
Inspired by biological NNs, artificial NNs are proposed to solve artificial intelligent problems. Initially, McCulloch and Pitts proposed the concept, that a single neuron, the basic element in NN, receives inputs, processes and generates outputs[
Recently, with the continuous decline of process nodes, the deep learning[
However, a deeper NN model may not perform better than a shallower model. Besides the increase of computation, the gradient vanishment also affects the training effect. By adjusting the structure of NN model, the training effect, convergence speed and model accuracy can be increased. He et al. developed residual blocks[
And with the efforts of the researchers, there is not only the structure of the NN model has improved, but the computation pattern of the NN layer also evolved. Yu and Koltun[
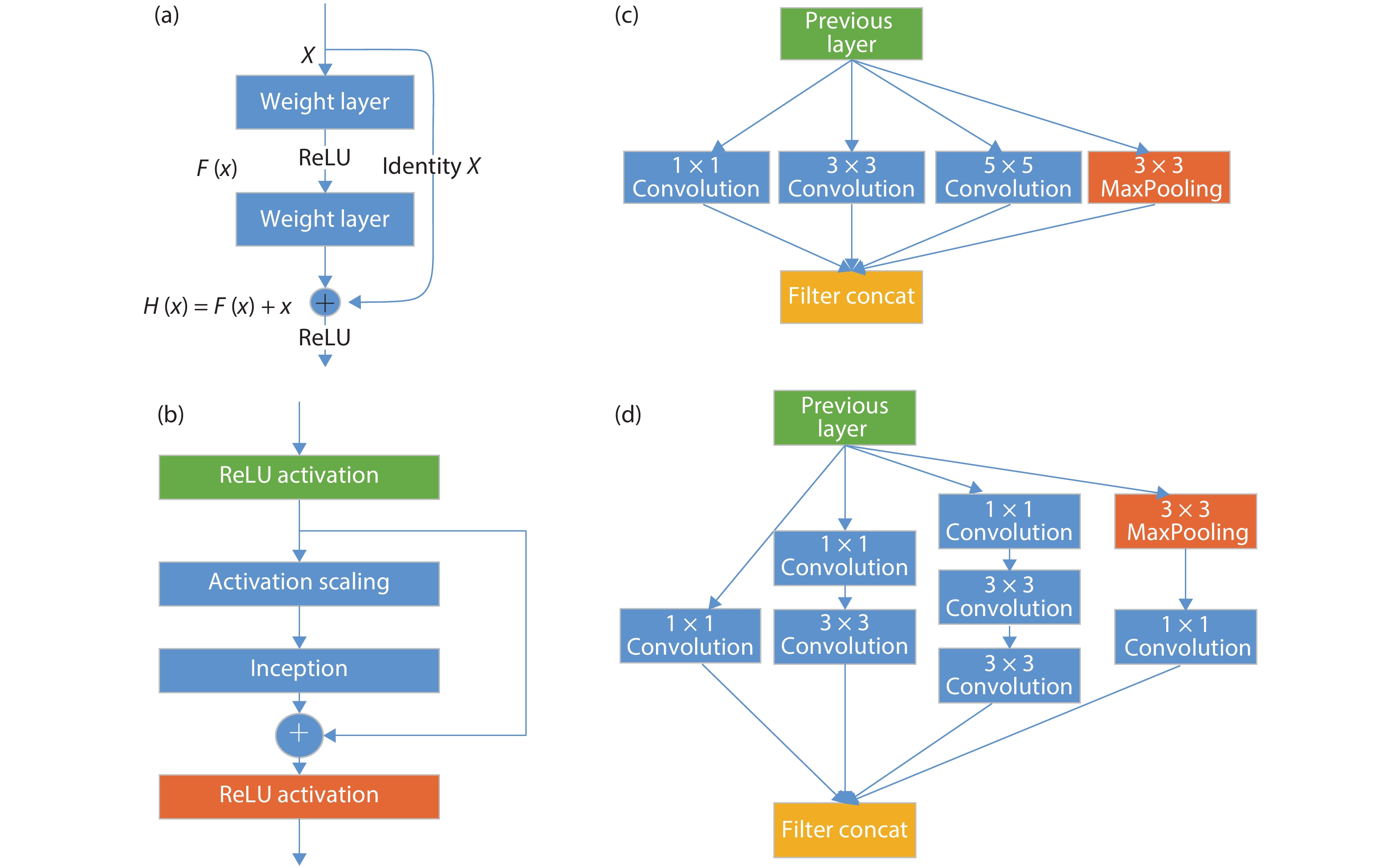
![]()
Figure 1.(Color online) Classical CNN model architectures. There are four fixed combination of layers in the figure. Among them, (a) stands for residual net in ResNet series networks, (b) expresses Inception-ResNet combination structure, (c) represents naïve inception structure, and (d) shows an upgraded version of inception with dimension reduction feature.
In the network structure design, in addition to the sequential execution of the direct connection of the NN layer, there are also ring topology. The recurrent neural network (RNN) is a class of NN model with recurrent connections. And due to the ring topology and internal state of the cyclic structure, it has significance on processing and predicting sequential data by overcoming many limitations of input and output data in traditional NN algorithms.
But after many layers of RNNs, the gradient tends to vanish in most cases. Long-short time memory (LSTM) network is a widely used recurrent structure network architecture in practical applications, which was proposed by Hochreiter[
In addition, transformer can increase to a very deep depth, fully exploit the characteristics of DNN model, require significantly less time to train, and improve the accuracy of the model. In 2018, Devlin et al. proposed bidirectional encoder representations from transformer (BERT)[
From a functional point of view, the convolution layers are usually placed at the front of the NN model to extract features. The number of channels is increased by sliding the filters over the input data, doing multiplication and addition. The pooling layer is usually following after convolution layers to reduce spatial dimension information, to avoid over-fitting, and improve the fault tolerance of the NN model. By exploiting data reuse pattern and calculation order of the NN layer in the network structure, a corresponding optimization method can be designed in hardware accelerator or software algorithm. And from a computation point of view, most part of computation in a NN model is occupied by the multiplications and additions in convolution layers and in fully-connected layers. Naturally, accelerating these types of layers is a key point to reduce the execution time of the whole network.
From the above methods, in the past few decades, lots of researchers have proposed many NN accelerator architectures, and put efforts from algorithm to hardware. From algorithm view, researchers use methods such as sparseness[
From a point of software view, programming system of NN accelerators includes the programming method of NNs, compilation and optimization. The design of the NN accelerator software stack is a bridge between programmers and the underlying hardware. Many deep learning frameworks have put efforts to simplify the deployment of NN algorithms on NN accelerators and maximize the performance end-to-end. Some frameworks are versatile and some are designed for NN accelerators. Section 3 reviews the detailed design of software stack of NN accelerator.
Section 4 comments the challenges and future trends of the development and implementation of the NN accelerator whole programming system. At the end, we summarize in Section 5.
2. Neural network accelerator and programmable hardware design
2.1. Neural network accelerator
In 2012, Chen et al.[
Researchers have proposed diverse accelerator schemes by utilizing the characteristics of the computing patterns in NN algorithms.
Some accelerators propose lower-bit precision computation and sparse representation. In 2009, Farabet et al. proposed an FPGA-based convolutional NN accelerator CNP[
Some accelerators design pipeline structure for NN. In 2016, Shafiee et al. designed a pipelined architecture, define new data encoding techniques and many supporting digital components, exploring the balance between memristors, ADCs, and eDRAMs[
DNN models are computationally and memory intensive, and their efficiency and scalability have been severely restricted by the limited memory bandwidth. Near-data processing is an effective way of addressing the above issue. Since 2014, Chen et al. have proposed the DianNao series of ASIC deep learning accelerators[
Some accelerators use reconfigurable architectures, considering programmability and flexibility. The concept of reconfiguration was first put forward by Professor Gerald Estrion in his article in 1960[
In 2012, Cadambi et al. presented a massively parallel, energy efficient programmable accelerator that can execute multiple learning and classification algorithms[
2.2. Accelerator hardware design summarization
Generally, NN accelerators have been implemented on various hardware platforms, which can be mainly divided into three categories.
The first is general purpose hardware platform, such as GPU, CPU, DSP and other processors belong to this type. They are based on Von Neumann structure that takes arithmetic logic units (ALU) as its computing core in general, and follow the workflow of fetching, decoding and executing instructions. Due to its versatility, the CPU needs to deal with various application scenarios, which may include complex types of branch jumps and interrupts. So that the control logic and cache hit ratio are the key factors that affect instruction throughput. Specialized optimization within a specific domain is an option. GPU tremendously reduces the space of control logic and cache, and adds a large number of single instruction multiple data (SIMD) computing unit, which greatly improves the parallelism of processor computing, making it suitable for large-scale, similar-type and repetitive computing applications. But its power consumption is high. General Purpose Processor with small buffer capacity and only supporting basic operations, and the complex arithmetic operations are composed of a series of basic operations. Thus, frequent data exchange between registers and memory, also between on-chip cache and off-chip storage is required, which not only reduces performance but also increases energy consumption of NN. Researchers began to design special accelerators for NN algorithms.
The second category is the application-specific integrated circuit (ASIC). ASIC is a special processor designed for specific applications, which has the advantages of small size, low power consumption, fast calculation speed and high reliability. ASIC adopts hardware circuit paths for fixed type computing tasks, so ASIC can achieve very high energy-efficiency ratios at very low power consumption generally (down to milliwatts). Therefore, it is a good choice in the scenario where the NN algorithm and application requirements are relatively fixed. However, ASIC has low flexibility, and its fixed hardware structure makes it lack of scalability. As long as the application requirements change slightly or NN algorithm begins to evolve, the whole hardware circuit needs to be redesigned. In addition, ASIC requires a long development cycle and the cost is high.
The third kind is based on reconfigurable devices, including field-programmable gate array (FPGA) and coarse-grained reconfigurable array (CGRA). FPGA can provide a large amount of computing and storage resources for computing-intensive applications (such as CNN, DNN, etc.). The programmable and reconfigurable features of this class of processors allow users to customize the processor structure according to their needs, and can complete the design evaluation in a very short time, thus shortening the development cycle. Because the FPGA sacrifices too much chip area and computing speed, CGRA is proposed. CGRA integrates the computing part into configurable processing elements (PE), and changes the link between PE and memory by configuring information, thereby realizing the dynamic configuration of the hardware structure. Because CGRA solidifies the internal hardware circuitry of PE and reduces the additional cost of its interconnect configuration, it can be closer to the ASIC in terms of energy efficiency, and the power consumption can be controlled at the milliwatt level.
Combined with the analysis above, we can get the comparison of different hardware acceleration platforms as Table 1 displays. In summary, the reconfigurable devices represented by FPGA have achieved a compromise in flexibility and performance between general hardware platform and ASIC.
In the aspect of programmability of NN, there are more research work. Liu et al. put forward a new instruction set architecture for NN accelerators, called Cambricon[
3. Software design and optimization of NN accelerator
This section mainly reviews the NN accelerator programming environments. We summarize the methods to improve NN programming performance, which are mainly based on the characteristics of NN algorithms and the architectures of NN accelerators.
3.1. Overview
In the NN accelerator design, it is not enough to consider the hardware features of the memory access and parallel of neural network computing, but also the entire programming system. The computing performance and energy efficiency of the hardware platform is only the premise of speeding up the neural network algorithm. The execution of neural network application also needs the cooperation of the software stack to enhance hardware efficiency. In actual application scenarios, regardless of the cloud servers, the IP in the mobile devices, or the cameras in embedded environment, the use of the neural network accelerator in any scenario is inseparable from the programming system. The hardware-based optimization in the software stack, directly determines the overall system workload and performance of the application. On the other hand, when the user deploys the application on the NN accelerator (especially the accelerator in ASIC form), the software stack and development environment must be adapted to the particularity of the hardware architecture. So, the design of the whole programming system directly determines the agility of front-end development, and influences the friendliness of the testing and debugging process. The portability of NN accelerator programming system is an important factor of the application, which can transplant or deploy to the target platform. Developers prefer not to re-debug or re-fine-tuned the network after the transplantation. And with the original NN model, the correctness and accuracy of the output should not be affected at all. In the ideal situation, the program after porting could fully utilize the acceleration performance of the accelerator.
The design of the programming system is mainly divided into two parts, the NN programming and the NN model compilation and optimization. The programming method of NN is the first level of interface that the programmer uses to develop on the specific accelerator hardware. The structured description is directly proposed by user to describe the NN model. The compilation of the network model is to translate the different levels of representation of the NN model to a series of machine code of the specific accelerator. Generally, the computational graph will be converted into assembly instructions. Since different accelerators may use different instruction set architectures (ISA), the compilation method is inexhaustible for different accelerators. So specialized optimizations can be made for the specific hardware architectures to maximize the benefits of hardware.
3.2. Programming of neural network
The programming of NNs is one of the first issues to be considered in NN model design. At present, the NN algorithm is still developing rapidly, and the scale and complexity of the NN model are increasing. All of these lead higher requirements on NN programming. Currently there are two methods of programming, one is using the NN frameworks (Fig. 2) and the other one is directly implemented in high-level programming language by programmers.
![]()
Figure 2.(Color online) Programming system hierarchy diagram.
3.3. Compilation and optimization of NN accelerator
The compilation and optimization of NN models are the core of the NN accelerator programming system, and also the bridge connecting the software application and the underlying hardware. Compilation of the NN model is to generate the instructions running on the NN accelerator based on the input NN model description. During compiling, the code can be optimized according to the characteristics of the model structure, the memory access pattern, and the architecture of the accelerator. Therefore, the software application can efficiently utilize hardware resources to achieve better performance and less power consumption.
![]()
Figure 3.(Color online) (a) TVM and (b) XLA compiling optimization stack overview diagram.
4. Future development trend
We have already reviewed some NN accelerator schemes in this paper. Some of them are implemented on the general-purpose chip platform, including supporting low-precision computing, supporting more NN frameworks, and designing for accelerated convolution operation. The implementation includes improved arithmetic storage structure, optimized data flow and design specific NN instruction set architecture, data level parallelism and data prefetching technology implemented on reconfigurable platforms. We also introduced the programming system of NN accelerators. With the concerted efforts of NN frameworks and compilers, developers can deploy and debug their NN algorithms efficiently and conveniently on accelerator hardware. While these designs have made significant advances in NN acceleration, there are still many challenges. In our view, the following five aspects are feasible directions for future research of NN accelerators and programming system.
(1)
(2)
(3)
(4)
(5)
With the development of NN algorithm, more NN operators need to be developed on the accelerator. In addition to optimizing the computation and memory access delay in hardware, the friendliness of programming and the efficiency of the library of NN accelerator should also be taken into account. So, the developers can spend less energy on the programming on the specific accelerator details and iterate faster. The automatic compile optimization of NN accelerator is a research direction. And the whole programming system may also consider of a heterogeneous computing platform for the performance end-to-end.
5. Conclusion
Nowadays, the NN accelerator has not only gained extensive attention in academic research, but has also been widely deployed in industrial applications. But as the applications of AI algorithms are becoming ubiquitous, the NN algorithm is also evolving. The variability of application scenarios, the diversity of algorithms and the huge amount of data put forward higher requirements for NN accelerators and their programming systems.
We sketch out the NN algorithms and NN accelerators. With the accelerator performance getting faster, hardware is no longer the bottleneck in the AI application. Meanwhile, implementing these algorithms on different software and hardware platforms and implementing them efficiently is still a huge challenge. It leads to the necessity and importance of acceleration as a whole entity. Then we review the latest development of from software aspects, including the implementation methods and compile optimization of the existing programming system for NN accelerators. We also comment the future development trend of NN accelerator, which direction must be the combination of software and hardware iteration, stimulating development.
Acknowledgments
This work is partially supported by the National Key Research and Development Program of China (under Grant 2017YFB1003101, 2018AAA0103300, 2017YFA0700900, 2017YFA0700902, 2017YFA0700901), the National Natural Science Foundation of China (under Grant 61732007, 61432016, 61532016, 61672491, 61602441, 61602446, 61732002, 61702478, and 61732020), Beijing Natural Science Foundation (JQ18013), National Science and Technology Major Project (2018ZX01031102), the Transformation and Transfer of Scientific and Technological Achievements of Chinese Academy of Sciences (KFJ-HGZX-013), Key Research Projects in Frontier Science of Chinese Academy of Sciences (QYZDB-SSW-JSC001), Strategic Priority Research Program of Chinese Academy of Science (XDB32050200, XDC01020000), Standardization Research Project of Chinese Academy of Sciences (BZ201800001), Beijing Academy of Artificial Intelligence (BAAI) and Beijing Nova Program of Science and Technology (Z191100001119093).
References
[1] W Huang, Z Jing. Multi-focus image fusion using pulse coupled neural network. Pattern Recogn Lett, 28, 1123(2007).
[2] J K Paik, A K Katsaggelos. Image restoration using a modified hopfield network. IEEE Trans Image Process, 1, 49(1992).
[3] X Li, L Zhao, L Wei et al. DeepSaliency: multi-task deep neural network model for salient object detection. IEEE Trans Image Process, 25, 3919(2016).
[4] Y Zhu, R Urtasun, R Salakhutdinov et al. segDeepM: exploiting segmentation and context in deep neural networks for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4703(2015).
[5] A Graves, A R Mohamed, G Hinton. Speech recognition with deep recurrent neural networks. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 6645(2013).
[6] O Abdelhamid, A Mohamed, H Jiang et al. Convolutional neural networks for speech recognition. IEEE/ACM Trans Audio Speech Language Process, 22, 1533(2014).
[7] R Collobert, J Weston. A unified architecture for natural language processing. International Conference on Machine Learning(2008).
[8] R Sarikaya, G E Hinton, A Deoras. Application of deep belief networks for natural language understanding. IEEE/ACM Trans Audio, Speech, Language Process, 22, 778(2014).
[9]
[10] W S McCulloch, W Pitts. A logical calculus of ideas immanent in nervous activity. Bull Math Biophys, 5, 115(1943).
[11] F Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain. Psycholog Rev, 65, 386(1958).
[12]
[13] G E Hinton, S Osindero, Y Teh. A fast learning algorithm for deep belief nets. Neur Comput, 18, 1527(2006).
[14]
[15] K He, X Zhang, S Ren et al. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770(2016).
[16] C Szegedy, W Liu, Y Jia et al. Going deeper with convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1(2015).
[17] C Szegedy, S Ioffe, V Vanhoucke et al. Inception-v4, Inception-ResNet and the impact of residual connections on learning. National Conference on Artificial Intelligence, 4278(2016).
[18]
[19] F Mamalet, C Garcia. Simplifying convnets for fast learning. international conference on artificial neural networks. International Conference on Artificial Neural Networks, 58(2012).
[20]
[21]
[22] S Hochreiter, J Schmidhuber. Long short-term memory. Neur Comput, 9, 1735(1997).
[23] A Vaswani, N Shazeer, N Parmar et al. Attention is all you need. Advances in Neural Information Processing Systems, 5998(2017).
[24]
[25]
[26]
[27] D D Lin, S S Talathi, V S Annapureddy. Fixed point quantization of deep convolutional networks. International Conference on Machine Learning, 2849(2016).
[28] J Xue, J Li, D Yu et al. Singular value decomposition based low-footprint speaker adaptation and personalization for deep neural network. IEEE International Conference on Acoustics(2014).
[29] E Park, J Ahn, S Yoo. Weighted-entropy-based quantization for deep neural networks. IEEE Conference on Computer Vision & Pattern Recognition(2017).
[30] L Song, Y Wang, Y Han et al. C-Brain: A deep learning accelerator that tames the diversity of CNNs through adaptive data-level parallelization. Design Automation Conference(2016).
[31] R J Kuo, Y L An, H S Wang et al. Integration of self-organizing feature maps neural network and genetic K-means algorithm for market segmentation. Expert Syst Appl, 30, 313(2006).
[32] T Roska, G Bártfai, P Szolgay et al. A digital multiprocessor hardware accelerator board for cellular neural networks: CNN-HAC. Int J Circuit Theory Appl, 20, 589(1992).
[33]
[34] A Page, A Jafari, C Shea et al. SPARCNet: a hardware accelerator for efficient deployment of sparse convolutional networks. ACM J Emerg Technolog Comput Syst, 13, 1(2017).
[35] T Chen, Y Chen, M Duranton et al. BenchNN: On the broad potential application scope of hardware neural network accelerators. 2012 IEEE International Symposium on Workload Characterization (IISWC), 36(2012).
[36] C Farabet, C Poulet, J Y Han et al. CNP: An FPGA-based processor for convolutional networks. International Conference on Field Programmable Logic and Applications(2009).
[37] S Zhang, Z Du, L Zhang et al. Cambricon-X: An accelerator for sparse neural networks. The 49th Annual IEEE/ACM International Symposium on Microarchitecture, 20(2016).
[38] Y Yu, T Zhi, X Zhou et al. BSHIFT: a low cost deep neural networks accelerator. Int J Paral Program, 47, 360(2019).
[39] A Shafiee, A Nag, N Muralimanohar et al. ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars. 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA)(2016).
[40] Y H Chen, T Krishna, J S Emer et al. Eyeriss: an energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J Solid-State Circuits, 52, 127(2017).
[41] N P Jouppi, C Young, N Patil et al. In-datacenter performance analysis of a tensor processing unit. 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 1(2017).
[42] Y Chen, T Chen, Z Xu et al. DianNao family: energy-efficient hardware accelerators for machine learning. Commun ACM, 59, 105(2016).
[43] T Chen, Z Du, N Sun et al. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine-learning. Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems(2014).
[44] Y Chen, T Luo, S Liu et al. Dadiannao: A machine-learning supercomputer. Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, 609(2014).
[45] Z Du, R Fasthuber, T Chen et al. ShiDianNao:shifting vision processing closer to the sensor. ACM/IEEE International Symposium on Computer Architecture(2015).
[46] D Liu, T Chen, S Liu et al. Pudiannao: A polyvalent machine learning accelerator. ACM SIGARCH Comput Architect News, 43, 369(2015).
[47] Z Du, K Palem, A Lingamneni et al. Leveraging the error resilience of machine-learning applications for designing highly energy efficient accelerators. 2014 19th Asia and South Pacific Design Automation Conference (ASP-DAC), 201(2014).
[48] G Estrin. Organization of computer systems: the fixed plus variable structure computer. Western Joint IRE-AIEE-ACM Computer Conference, 33(1960).
[49]
[50] A Majumdar, S Cadambi, M Becchi et al. A massively parallel, energy efficient programmable accelerator for learning and classification. ACM Trans Architect Code Optim, 9, 1(2012).
[51]
[52] K Ando, K Ueyoshi, K Orimo et al. BRein memory: a single-chip binary/ternary reconfigurable in-memory deep neural network accelerator achieving 1.4 TOPS at 0.6 W. IEEE J Solid-State Circuits, 53, 983(2017).
[53] J Lee, C Kim, S H Kang et al. UNPU: A 50.6TOPS/W unified deep neural network accelerator with 1b-to-16b fully-variable weight bit-precision. International Solid-State Circuits Conference, 218(2018).
[54] W You, C Wu. A reconfigurable accelerator for sparse convolutional neural networks. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 119(2019).
[55] S Liu, Z Du, J Tao et al. Cambricon: An instruction set architecture for neural networks. ACM SIGARCH Comput Architect News, 44, 393(2016).
[56] Y Zhao, Z Du, Q Guo et al. Cambricon-F: machine learning computers with fractal von neumann architecture. International Symposium on Computer Architecture, 788(2019).
[57] M Abadi, P Barham, J Chen et al. Tensorflow: A system for large-scale machine learning. 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), 265(2016).
[58] Y Jia, E Shelhamer, J Donahue et al. Caffe: Convolutional architecture for fast feature embedding. Proceedings of the 22nd ACM International Conference on Multimedia, 675(2014).
[59]
[60]
[61] H Lan, Z Du. DLIR: an intermediate representation for deep learning processors. IFIP International Conference on Network and Parallel Computing, 169(2018).
[62] W Du, L Wu, X Chen et al. ZhuQue: a neural network programming model based on labeled data layout. International Symposium on Advanced Parallel Processing Technologies, 27(2019).
[63]
[64]
[65] C Mendis, J Bosboom, K Wu et al. Helium: lifting high-performance stencil kernels from stripped ×86 binaries to halide DSL code. Program Language Des Implem, 50, 391(2015).
[66] J Song, Y Zhuang, X Chen et al. Compiling optimization for neural network accelerators. International Symposium on Advanced Parallel Processing Technologies, 15(2019).

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20