
Yanan Lu, Leibo Liu, Jianfeng Zhu, Shouyi Yin, Shaojun Wei. Architecture, challenges and applications of dynamic reconfigurable computing[J]. Journal of Semiconductors, 2020, 41(2): 021401
- Journal of Semiconductors
- Vol. 41, Issue 2, 021401 (2020)
Abstract
1. Introduction
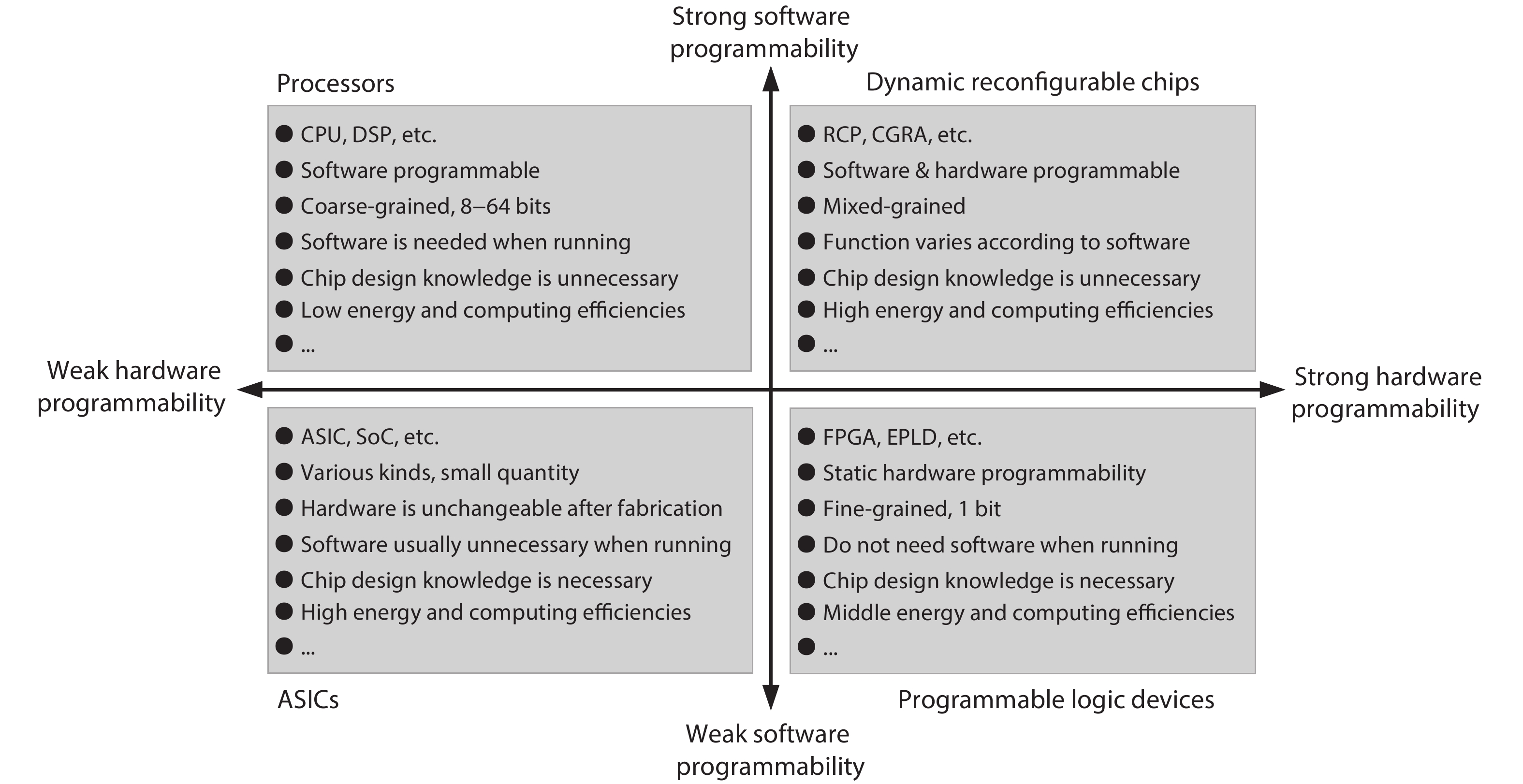
Reconfigurable computing has drawn wide attention in both academia and industry in the past decade, and respective commercial products are quickly emerging[
![]()
Figure 1.Programmability comparisons among different chips.
Reconfigurable computing is not a new concept. As early as the 1960s, Prof. Gerald Estrin of UCLA proposed that computers can be composed of a main processor and an array of reconfigurable hardware[
From the perspective of implementation, reconfigurable architectures mainly include FPGAs and coarse-grained reconfigurable arrays (CGRAs). FPGA is an early form of reconfigurable computing whose development continues today. Xilinx developed the world’s first FPGA in 1986[
There are many previous surveys on reconfigurable computing[
2. Architecture
As mentioned earlier, the implementation forms of reconfigurable computing mainly include FPGAs and CGRAs. Since FPGAs are relatively mature and their architecture is well known, this section focuses on the architecture of CGRAs.
2.1. Architecture model
The basic architecture model of CGRAs is shown in Fig. 2. It consists mainly of two parts: a reconfigurable controller (RCC) and a reconfigurable datapath (RCD). Both RCC and RCD contain memory for storing configuration and data, respectively. It can be seen that this architecture is a variant of the von Neumann computing architecture. The main difference from an instruction processor is that RCC controls the behavior of RCD through configuration rather than instructions. RCD can be reconfigured because it integrates abundant basic arithmetic units (such as adders, multipliers, etc.) and logical units (such as AND, OR, NAND, XOR, etc.), and RCC can select and organize these computing units to achieve specific structures and functions according to configuration. The hardware structures of RCC and RCD are introduced next.
![]()
Figure 2.An architecture model of reconfigurable computing.
2.2. Reconfigurable controller
The hardware structure of RCC consists of three parts: configuration management unit, memory module and configuration interface (as shown in Fig. 3). The configuration management unit receives configuration context from the outside and parses it to get the internal control signals and configuration context. The internal configuration context is stored in the memory module and transferred to RCD by the configuration interface as needed. The configuration interface is used to send configuration context and control signals to RCD.
![]()
Figure 3.The structure of RCC.
The RCC is responsible for the organization and management of the configuration of RCD. Controllers in traditional single-core processors focus on timing scheduling in single node. Since the instruction stream is repeatedly executed on a single node, many parallelization techniques such as pipelining are employed, thus the timing requirement of the controller is high. In contrast, reconfigurable computing processors are mostly implemented in the form of arrays, which are oriented to computing resource scheduling of multi-nodes. processing elements (PEs) are usually not as complex as a single-core processor, and the node control timing of the controller is relatively simple. The overall efficiency of spatial and temporal utilizations is more important than node scheduling, which presents new design requirements for the controller. In the case of a large amount of configuration, it is conceivable to add a customized accelerator or even a control unit array into RCC.
2.3. Reconfigurable datapath
The RCD generally includes four parts: a processing element array (PEA), a memory, a data interface, and a configuration interface (as shown in Fig. 4). The configuration interface obtains control signals and configuration context from RCC, while it sends out states. The configuration interface then parses the configuration context, configures the function of the PEA, and schedules the execution order of tasks on PEA. After the PEA is configured, it starts to execute in a set time, driven by dataflow, just like an ASIC. The input data of the PEA is obtained from the data interface, and the intermediate data is buffered in the memory. In addition to completing the access and write back of external data, the data interface can also accept signals from the configuration interface to shape and transform (such as transposition, splicing operation, etc.) the data to cooperate with the execution of the PEA.
![]()
Figure 4.The structure of RCD.
The basic structure of the PEA is shown in Fig. 5. A large number of PEs are combined together under a certain connection for parallel computing. A PE is generally composed of an arithmetic logic unit (ALU) and a group of registers. For parallel computing, the main bottleneck limiting the performance lies in the external memory interface when computing resources are sufficient, which is referred to as throughput computing. Therefore, the caching and prefetching of data is very important, which can effectively reduce the dependence on external memory. In a PEA, a hierarchical and distributed memory structure is usually employed. Except the multi-layer design of the memory module in Fig. 4, a large number of distributed memories—such as an interface buffer, an array-level cache, an internal PE memory—are also required inside the PEA.
![]()
Figure 5.The structures of PEA and a PE.
The PEA can be classified into coarse-grained, medium-grained, fine-grained, mixed-grained reconfigurable arrays according to the granularity of the PEs. Higher computational efficiency can be achieved when the granularity matches the data width of the applications. For example, the fine-grained PEA is suitable for bit operations-based applications; the coarse-grained PEA which may include larger functional modules such as addition and multiplication units, performs better for graphic and image processing, as well as digital baseband operations. The mixed-grained PEA combines multiple granularities and is more flexible, making it suitable for various data widths.
2.4. Configuration
The configuration of a dynamic reconfigurable processor includes operator configuration, interconnection configuration and data transmission configuration[
The design of a configuration system for a dynamic reconfigurable processor is similar to the design of ISA in GPPs. It includes the design of the organizational structure of configuration information, the configuration storage scheme, and the configuration management scheme. Consequently, it belongs to the category of architecture. In the design of organizational structure, the configuration information is allocated to different layers but organized as a whole. In the design of configuration storage scheme, corresponding storage schemes are designed for the layer configuration and the information in each layer. The configuration information is stored in the configuration memory. The configuration management scheme is designed based on the previous two steps. Unlike the static organizational structure, configuration management refers to the dynamic configuration flow, which reads out the various kinds of configuration information from configuration memory and writes into the corresponding hardware modules to complete the configuration.
2.5. Implementation instance: HReA
To explain the architecture of a dynamic reconfigurable processor clearly, this section will introduce an implementation instance: HReA[
![]()
Figure 6.The architecture of HReA.
Master micro-controller is the master-control unit and started up under the control of SYSCTL. It is responsible for configuring DMAC to transfer program package from DDR into the ESRAM. PEA micro-controller is dedicated to control the configuration and data for PEAs. It assigns tasks for PEAs via coprocessor interface. There are four PEAs (i.e, PEA_0, PEA_1, PEA_2, and PEA_3) and they are the key components to implement task acceleration. They can be dynamically combined according to the requirements of calculation so as to achieve algorithm-level parallelism and can also be turned off individually to save power. When completing tasks, PEAs notify PEA micro-controller via INTC.
The main functionality of a PEA is to fetch, process, store and export data driven by control and configuration flows. The core part of a PEA is the 4 × 4 hybrid-grained PEs which are organized in a nearby manner. Based on configuration context, the interconnections between PEs can be dynamically reconfigured via configuring router connection. Each PEA also contains auxiliary components, including host interface, PEA controller, configuration controller and data controller, to prepare control signal, configuration, and operand data for the PE array. The host interface receives coprocessor instructions from PEA micro-controller and reserves data exchanged between PEA micro-controller and PE array in global register. The PEA controller enables calculation on PE array under the control of the host interface. The configuration controller, containing a context memory for configuration contexts, is responsible for scheduling the execution sequence. The data controller provides operand data to the PE array, with a shared memory for buffering input data, intermediate results, and final outputs.
PEs can be dynamically configured to execute arithmetic and logic operations under the control of configuration context. Each PE in HReA combines a 32-bit data path with a 1-bit data path to accommodate multiple computing granularities, providing up to 15 different operations—including logical operations, such as AND, OR, XOR, and so on—and arithmetic operations—such as adder, subtracter, multiplier, leading-zero detector, shifter, multiplexer, absolute, and so on. Based on configuration context stored in the context register, the PE controller is responsible for selecting operand data (i.e, ALU_input) and generating operation code (i.e, ALU_op) for the ALU. The calculation results of the ALU can be kept in the inner register file for short-term storage or can be sent to shared memory via load store unit (LSU) for long-term storage.
Based on the hybrid-grained PE structure, HReA can efficiently deal with both computing-intensive kernels and control-intensive kernels which involve various branches, loops, and sequential codes. Measured results on kernels from the 13-Dwarfs[
3. Compilation
Unlike GPPs and FPGAs, which compute temporally and spatially respectively, dynamic reconfigurable processors are both temporal and spatial computing fabrics. The compilation of a dynamic reconfigurable processor is very important and has a direct impact on performance. This section describes the compiler framework and presents the key compiling techniques for dynamic reconfigurable processors.
3.1. The compiler’s framework
To process the computing tasks of various applications, a corresponding target program must be generated by a compiler for the component units (i.e, RCC and RCD) of the reconfigurable processor. The compiler generates control codes for RCC and configurations for RCD via the processes of code transformation, task partition, task scheduling, mapping, and configuration generation.
Since the hardware structure of a reconfigurable processor is significantly different from that of a conventional GPP, the compilation flow and functions of a reconfigurable processor compiler are different from those of traditional compilers (such as GNU gcc compiler). A conventional compiler compiles input application codes to generate assembly language codes and corresponding machine codes for a target processor. However, a reconfigurable processor compiler performs code analysis on the input application, divides the application into software and hardware codes by using the software and hardware co-design method, and then respectively compiles the two kinds of codes to generate control codes for RCC and configurations for RCD.
Fig. 7 shows an example of dividing and executing a kernel on HReA. The two loops in the kernel consume most of the execution time and can be accelerated on PEAs, while the Pre-loop/Inter-loop/Post-loop codes are executed on PEA micro-controller. In a dynamic reconfigurable processor, multiple PEs in the array can achieve parallel processing or pipelined sequential processing. For the first loop which is iteration independent in Fig. 7, it can be fully unrolled. Thus, iteration 0, 1, 2, 3 can be executed in parallel on different PEs. In a spatial mapping, Stage 0-1, Stage 1-1, Stage 2-1, Stage 3-1 are mapped onto PE0, PE1, PE2, PE3, respectively, and Stage 0-2, Stage 1-2, Stage 2-2, Stage 3-2 are mapped onto PE4, PE5, PE6, PE7, respectively (PE4, PE5, PE6, PE7 are on the second row in PEA.). However, in a temporal mapping, Stage 0-2, Stage 1-2, Stage 2-2, Stage 3-2 are also mapped onto PE0, PE1, PE2, PE3 respectively. The second loop in Fig. 7 is iteration dependent. Assumed that the initiation interval is 1. Stage 1-4 mapped onto PE1 should be executed one cycle after Stage 0-4 mapped onto PE0.
![]()
Figure 7.Example of dividing and executing a kernel.
The compiler framework of a reconfigurable processor is shown in Fig. 8. First, the compiler needs to transform and optimize the code of an application to get the data flow graph (DFG). The DFG is then mapped to the reconfigurable processor. Owing to limited hardware resources, the DFG usually needs to be partitioned and divided into a series of interdependent subgraphs. These subgraphs will be scheduled by RCC and mapped to RCD for execution after task mapping and configuration generation.
![]()
Figure 8.The compiler framework of a reconfigurable processor.
The task mapping process includes register allocation, operator mapping and memory mapping. In a reconfigurable processor, registers and internal memory are designed for data interaction and transfer between subtasks. Therefore, necessary register and memory allocation besides operator mapping is required in compilation. The last process is configuration generation and optimization, which generates control codes and configuration information for RCC and RCD respectively. To improve the overall performance, the configuration information needs to be reasonably optimized by eliminating redundant information and compression.
3.2. Key techniques for compiling
There are several key techniques in the compilation of a dynamic reconfigurable processor, such as code transformation and optimization, temporal task partition, internal memory management, and configuration optimization. This section discusses these techniques.
3.2.1. Code transformation and optimization
For most reconfigurable processors, the application’s program codes are written in a high-level programming language (e.g, C), which is mostly procedure oriented and has few parallelizable code segments. The parallelism in code segments are not expressed explicitly in the program. To effectively improve the performance of an application, it is necessary to fully exploit the code blocks that have high parallelism in the program[
3.2.2. Temporal task partition
Dynamic reconfigurable computing architectures support changing their hardware functions by dynamically switching the configurations. When a task executed on the reconfigurable computing processor exceeds the hardware resources, it is usually divided into a series of small tasks (subtasks), which are scheduled and sequentially executed on the hardware through multiple times of configuration. Therefore, the same hardware can be configured multiple times and perform repeated execution[
The temporal task partition technique divides a task into a series of subtasks that are related to each other in the time domain. To execute tasks beyond the computing resources on the limited hardware, large tasks are divided into several subtasks and time-multiplexing the hardware resources are adopted. Fig. 9 shows an example of temporal task partition[
![]()
Figure 9.Temporal partition of task graph.
3.2.3. Internal memory management
When multiple subtasks are executed on the same reconfigurable hardware in time-multiplexing manner, there are possibly data dependencies between these subtasks. Therefore, it is necessary to consider data interaction between subtasks through internal memory in the process of mapping and configuration generation.
Figs. 10(a) and 10(b) show the two main problems of internal data interaction that need to be addressed. The first problem comes from data interaction when an operator has multiple output targets, as shown in Fig. 10(a). A dynamic reconfigurable processor usually provides limited data manipulations due to hardware complexity. When there is more than one output targets (external output and internal data transfer between subtasks) for an operator in a subtask, the storage resources need to be effectively managed to reduce the occupancy rate and to ensure the correctness. Techniques such as variable life cycle analysis and operator reordering can be used to reduce the occupancy rate of storage resource and improve the computing performance. The second problem comes from the data interaction between subtasks. When a subtask requires much intermediate data as input and the storage locations of these data are scattered, it is necessary to rearrange these data for block operations. The rearrangement can extract the operation data required by the current subtask and improve the efficiency of memory access. Techniques such as subtask correlation analysis and data splicing can be used to improve the efficiency of memory access.
![]()
Figure 10.Illustration of internal memory management. (a) Multiple output targets. (b) Communication between subtasks.
3.2.4. Configuration optimization
As mentioned in the previous sections, the hardware function of a dynamic reconfigurable processor is changed by dynamically switching the configuration. For the configurations of multiple subtasks, eliminating the redundancy in configurations and compressing the configuration volume will greatly shorten the configuration loading time. The reason for the redundancy is that the operator connection graphs in different subtasks have similar structures. Two techniques can be used to eliminate the redundancy in configurations. First, by analyzing the statistical correlation in the bit rate of redundant information, traditional data compression methods can be utilized to reduce the configuration volume[
4. Challenges
Although there have been many successful CGRA designs, which are superior in terms of energy efficiency and flexibility, CGRA is still immature and far away from large-scale commercial utilization because there are still some key technologies and bottlenecks that have not been well resolved. Some of the existing technical challenges and proposed solutions follow.
4.1. Cooperation of temporal and spatial mapping
Mapping an application written in a high-level programming language to a reconfigurable chip is a complex issue. A variety of techniques can be used together in the mapping process. Ref. [49] proposed an aggressive pipelining method for irregular applications on reconfigurable hardware. For control flows in irregular applications that could not be predict by static analysis, the abundant spatial computing resources are used at runtime to aggressively execute tasks concurrently. Therefore, fine-grained parallelism in applications can be efficiently developed. After utilizing a combination of methods, the computing performance can be increased by an order of magnitude. A polyhedral model that is based mapping technology can also be adopted for performance optimization. Taking into account parameters such as dynamic reconfiguration, array calculation and cache access, and using a joint optimization method of affine transformation and loop tiling to establish a performance model and a power consumption model, the execution time of a task can be reduced by about 20%[
4.2. Control-intensive task parallelization
Reconfigurable computing architectures are effective for compute-intensive tasks, but how to perform control-intensive tasks is a difficult problem. Exploring the parallelization of control-intensive tasks on a centralized-controlled computing array is necessary. By giving a common mapping process and utilizing techniques such as merging branches and condition computation, configuration fusion, and configuration branch optimization, the configuration and execution time of control tasks can be reduced and the performance is improved by approximately 40%[
4.3. Optimization of configuration organization
Reconfigurable hardware needs continuous configuration to change the structure and function. It is important to consider the size of the configuration. Generally, the amount of a FPGA configuration is about a dozen megabytes or tens of megabytes, and the configuration time is several hundred milliseconds to a few seconds, which is too long for a dynamic reconfigurable CGRA. To achieve reconfiguration in a short time, the first thing is to reduce the amount of configuration information. Through analysis of the computational flow graph, Ref. [53] proposed a hierarchical configuration generation technology based on isomorphic similarity matching of subgraphs. The commonality of the DFG is extracted according to the similarity matching and cross index between subgraphs. The total amount of configuration information can be reduced by more than 70% and an optimized hierarchical organization of configuration is formed.
4.4. Dynamically loading configuration
Although the amount of configuration is reduced, it still takes time to load the configuration onto the datapath. It is found that it is unnecessary to send configuration all the time, and some configuration may be resident in the memory. Ref. [54] proposed a correlation-aware caching strategy for configuration flow. An on-chip cache structure and the prefetching method have been designed for grouping the configuration according to the computing tasks. Redundant transmission of configuration flow in each layer is eliminated. The configuration sets are converged downwards by layer. The gap of configuration flow is optimized by using pipeline equalization. Consequently, the configuration amount is reduced and the configuration speed is increased, which results in a decrease in the configuration time.
These technologies relieve the problems of optimal generation, storage and loading of configuration information in dynamic reconfigurable chips. Through the maximum parallelization of configuration and execution, nanosecond-level function reconfiguration is realized, providing the foundation of both energy efficiency and flexibility for dynamic reconfigurable chips.
5. Applications
From the current successful application of CGRAs, it can be seen that they are more suitable for compute-intensive and data-intensive applications. The following classifications describe the current main applications of CGRAs.
5.1. Neural network
Since 2010, advances in neural networking technology have driven the development of artificial intelligence. Deep neural network (DNN), which is a basic supporting technology, requires complex calculations of large amounts of data with frequent inter-layer communication. Research shows that CGRA is a superior implementation of DNN because of its high throughput computing and on-chip communication capabilities. For example, Eyeriss[
Thinker[
5.2. Cryptography
Cryptographic processing is also a computing-intensive application, which is especially suited for CGRA-based implementations. Scholars have proposed many reconfigurable cryptographic processors based on CGRA structure. For example, Celator[
5.3. Multimedia
Multimedia (e.g, voice, image and video) usually need to code or decode abundant data. They are typical stream processing applications that deal with different data in the same way. These applications contain plenty of parallel calculations on macro blocks. CGRA performs well in stream processing because of its "switching configurations to adapt the application" and "one-time configuration, multi-time execution" features. There are a large number of CGRA structures for this type of application. For example, the classic ADRES has been applied to video processing (H.264/AVC decoding[
5.4. Signal processing
CGRAs can also be used in the field of signal processing where the most important algorithms are fast Fourier transform (FFT) and inverse FFT. For instance, ADRES has been applied to software-defined radio (SDR) signal processing (SDM-OFDM) receivers[
6. Conclusion
CGRA is the main form of dynamic reconfigurable computing fabric. This paper surveys the important aspects of CGRA, including the concept, architecture, compilation, existing challenges, and prospective applications. However, CGRA is not as mature as FPGA and still has some challenges to overcome. Since CGRA is superior in energy efficiency, area efficiency and flexibility, and does well in several important application domains, it is predicted that CGRA will become an alternative to some existing computing architectures.
Acknowledgments
This work is supported in part by the National Science and Technology Major Project of the Ministry of Science and Technology of China (Grant No. 2018ZX01028201), and in part by the National Natural Science Foundation of China (Grant No. 61672317, No. 61834002), and in part by the National Key R&D Program of China (Grant No. 2018YFB2202101).
References
[1] R Prabhakar, Y Zhang, D Koeplinger et al. Plasticine: a reconfigurable architecture for parallel paterns. ACM/IEEE International Symposium on Computer Architecture, 389(2017).
[2] T Nowatzki, V Gangadhar, N Ardalani et al. Stream-dataflow acceleration. ACM/IEEE International Symposium on Computer Architecture, 416(2017).
[3]
[4]
[5]
[6]
[7]
[8]
[9] M Suzuki, Y Hasegawa, Y Yamada et al. Stream applications on the dynamically reconfigurable processor. IEEE International Conference on Field-Programmable Technology, 137(2004).
[10]
[11] M Horowitz. Computing's energy problem (and what we can do about it). IEEE International Solid-state Circuits Conference (ISSCC), 10(2014).
[12] R Tessier, K L Pocek, A Dehon. Reconfigurable computing architectures. Proc IEEE, 103, 332(2015).
[13]
[14] T Nowatzki, V Gangadhar, K Sankaralingam et al. Pushing the limits of accelerator efficiency while retaining programmability. IEEE International Symposium on High Performance Computer Architecture (HPCA), 27(2016).
[15]
[16] G Estrin. Organization of computer systems—the fixed plus variable structure computer. Proceeding of Western Joint Computer Conference, 33(1960).
[17] R W Hartenstein, A G Hirschbiel, M Riedmuller et al. A novel ASIC design approach based on a new machine paradigm. IEEE J Solid-State Circuits, 26, 975(1991).
[18] D C Chen, J M Rabaey. A reconfigurable multiprocessor IC for rapid prototyping of algorithmic-specific high-speed DSP data paths. IEEE J Solid-State Circuits, 27, 1895(1994).
[19]
[20]
[21]
[22] J G Wingbermuehle, R K Cytron, R D Chamberlain. Superoptimized memory subsystems for streaming applications. International Symposium on Field-Programmable Gate Arrays(2015).
[23] A Putnam, G Jan, G Michael et al. A reconfigurable fabric for accelerating large-scale datacenter services. IEEE Micro, 35, 10(2015).
[24]
[25] J Coole, G G Stitt. Intermediate fabrics: Virtual architectures for circuit portability and fast placement and routing. The eighth IEEE/ACM/IFIP international conference on Hardware/software codesign and system synthesis(2010).
[26] H Singh, M Lee, G Lu et al. MorphoSys: an integrated reconfigurable system for data-parallel and computation-intensive applications. IEEE Trans Comput, 49, 465(2000).
[27] B Mei, S Vernalde, D Verkest et al. ADRES: an architecture with tightly coupled VLIW processor and coarse-grained reconfigurable matrix. International Conference on Field Programmable Logic and Application (FPL), 61(2003).
[28] V Baumgarte, G Ehlers, F May et al. PACT XPP—A self-reconfigurable data processing architecture. J Supercomput, 26, 167(2003).
[29] L Liu, C Deng, D Wang et al. An energy-efficient coarse-grained dynamically reconfigurable fabric for multiple-standard video decoding applications. IEEE Custom Integrated Circuits Conference, 1(2013).
[30] S A Chin, N Sakamoto, A Rui et al. CGRA-ME: A unified framework for CGRA modelling and exploration. IEEE 28th International Conference on Application-specific Systems, Architectures and Processors (ASAP), 184(2017).
[31]
[32] L Duch, S Basu, O M Pe et al. i-DPs CGRA: an interleaved-datapaths reconfigurable accelerator for embedded bio-signal processing. IEEE Embed Syst Lett, 11, 50(2019).
[33]
[34] H Amano. A survey on dynamically reconfigurable processors. IEICE Trans Commun, 89, 3179(2006).
[35] B Zain-ul-Abdin. Evolution in architectures and programming methodologies of coarse-grained reconfigurable computing. Microprocess Microsyst, 22, 161(2009).
[36] A Dehon. Fundamental underpinnings of reconfigurable computing architectures. Proc IEEE, 103, 355(2015).
[37] A Chattopadhyay. Ingredients of adaptability: a survey of reconfigurable processors. VLSI Design, 10(2013).
[38] Y Wang, L Liu, S Yin et al. Hierarchical representation of on-chip context to reduce reconfiguration time and implementation area for coarse-grained reconfigurable architecture. Sci Chin Inform Sci, 56, 1(2013).
[39] L Liu, Z Li, C Yang et al. HReA: an energy-efficient embedded dynamically reconfigurable fabric for 13-dwarfs processing. IEEE Trans Circuits Syst II, 65, 381(2017).
[40]
[41] C Y Yin, S Y Yin, L B Liu et al. Front end design of task compiler for reconfigurable multimedia processor. J Beijing Univ Posts Telecommun, 34, 108(2011).
[42]
[43]
[44] A Beletska, W Bielecki, A Cohen et al. Coarse-grained loop parallelization: iteration space slicing vs affine transformations. Paral Comput, 37, 479(2011).
[45] Y C Jiang, J F Wang. Temporal Partitioning data flow graph for dynamically reconfigurable computing. IEEE Trans VLSI Syst, 15, 1351(2007).
[46]
[47] N Aslam, M Milward, A Erdogan et al. Code compression and decompression for coarse-grain reconfigurable architectures. IEEE Trans VLSI Syst, 16, 1596(2008).
[48] S Yin, C Yin, L Liu et al. Configuration context reduction for coarse-grained reconfigurable architecture. IEICE Trans Inform Syst, E95-D, 335(2012).
[49] Z Li, L Liu, Y Deng et al. Aggressive pipelining of irregular applications on reconfigurable hardware. ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 575(2017).
[50]
[51] J Zhu, L Liu, S Yin et al. A hybrid reconfigurable architecture and design methods aiming at control-intensive kernels. IEEE Trans VLSI Syst, 23, 1700(2015).
[52] L Liu, J Wang, J Zhu et al. TLIA: Efficient reconfigurable architecture for control-intensive kernels with triggered-long-instructions. IEEE Trans Paral Distrib Syst, 27, 1(2016).
[53] Y Wang, L Liu, S Yin et al. On-chip memory hierarchy in one coarse-grained reconfigurable architecture to compress memory space and to reduce reconfiguration time and data-reference time. IEEE Trans VLSI Syst, 22, 983(2014).
[54] C Yang, L Liu, K Luo et al. CIACP: a correlation-and iteration-aware cache partitioning mechanism to improve performance of multiple coarse-grained reconfigurable arrays. IEEE Trans Paral Distrib Syst, 27, 1(2016).
[55] Y H Chen, T Krishna, J S Emer et al. Eyeriss: an energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J Solid-State Circuits, 52, 127(2017).
[56] C Farabet, B Martini, B Corda et al. NeuFlow: A runtime reconfigurable dataflow processor for vision. Computer Vision and Pattern Recognition Workshops, 109(2011).
[57] S Yin, P Ouyang, S Tang et al. 0.6-to-5.09 TOPS/W reconfigurable hybrid-neural-network processor for deep learning applications. Symposium on VLSI Circuits, C26(2017).
[58] D Fronte, A Perez, E Payrat. Celator: a multi-algorithm cryptographic Co-processor. International Conference on Reconfigurable Computing and FPGAs, 438(2008).
[59] G Sayilar, D Chiou. Cryptoraptor: High throughput reconfigurable cryptographic processor. IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 155(2014).
[60] B Mei, F J VeredaS, B Masschelein. Mapping an H.264/AVC decoder onto the ADRES reconfigurable architecture. International Conference on Field Programmable Logic and Applications, 622(2005).
[61] M Hartmann, V Pantazis, T V Aa et al. Still image processing on coarse-grained reconfigurable array architectures. J Sign Proces Syst, 60, 225(2010).
[62] M K A Ganesan, S Singh, F May et al. H.264 decoder at HD resolution on a coarse grain dynamically reconfigurable architecture. International Conference on Field Programmable Logic and Applications, 467(2007).
[63] S Kim, Y H Park, J Kim et al. Flexible video processing platform for 8K UHD TV. Hot Chips 27 Symposium, 1-1(2016).
[64] D Novo, W Moffat, V Derudder et al. Mapping a multiple antenna SDM-OFDM receiver on the ADRES coarse-grained reconfigurable processor. IEEE Workshop on Signal Processing Systems Design and Implementation, 473(2005).
[65] M Palkovic, H Cappelle, M Glassee et al. Mapping of 40 MHz MIMO SDM-OFDM baseband processing on multi-processor SDR platform. IEEE Workshop on Design and Diagnostics of Electronic Circuits and Systems, 1(2008).
[66] X Chen, A Minwegen, Y Hassan et al. FLEXDET: flexible, efficient multi-mode mimo detection using reconfigurable ASIP. IEEE International Symposium on Field-Programmable Custom Computing Machines, 69(2012).

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20