Large-scale linear operations are the cornerstone for performing complex computational tasks. Using optical computing to perform linear transformations offers potential advantages in terms of speed, parallelism, and scalability. Previously, the design of successive spatially engineered diffractive surfaces forming an optical network was demonstrated to perform statistical inference and compute an arbitrary complex-valued linear transformation using narrowband illumination. We report deep-learning-based design of a massively parallel broadband diffractive neural network for all-optically performing a large group of arbitrarily selected, complex-valued linear transformations between an input and output field of view, each with Ni and No pixels, respectively. This broadband diffractive processor is composed of Nw wavelength channels, each of which is uniquely assigned to a distinct target transformation; a large set of arbitrarily selected linear transformations can be individually performed through the same diffractive network at different illumination wavelengths, either simultaneously or sequentially (wavelength scanning). We demonstrate that such a broadband diffractive network, regardless of its material dispersion, can successfully approximate Nw unique complex-valued linear transforms with a negligible error when the number of diffractive neurons (N) in its design is ≥2NwNiNo. We further report that the spectral multiplexing capability can be increased by increasing N; our numerical analyses confirm these conclusions for Nw > 180 and indicate that it can further increase to Nw ∼ 2000, depending on the upper bound of the approximation error. Massively parallel, wavelength-multiplexed diffractive networks will be useful for designing high-throughput intelligent machine-vision systems and hyperspectral processors that can perform statistical inference and analyze objects/scenes with unique spectral properties.
Computing plays an increasingly vital role in constructing intelligent, digital societies. The exponentially growing power consumption of digital computers brings some important challenges for large-scale computing. Optical computing can potentially provide advantages in terms of power efficiency, processing speed, and parallelism. Motivated by these, we have witnessed various research and development efforts on advancing optical computing over the last few decades.1–32 Synergies between optics and machine learning have enabled the design of novel optical components using deep-learning-based optimization,33–44 while also allowing the development of advanced optical/photonic information processing platforms for artificial intelligence.5,20–32,45
Among different optical computing designs, diffractive optical neural networks represent a free-space-based framework that can be used to perform computation, statistical inference, and inverse design of optical elements.22 A diffractive neural network is composed of multiple transmissive and/or reflective diffractive layers (or surfaces), which leverage light–matter interactions to jointly perform modulation of the input light field to generate the desired output field. These passive diffractive layers, each containing thousands of spatially engineered diffractive features (termed as “diffractive neurons”), are designed (optimized) in a computer using deep-learning tools, e.g., stochastic gradient descent and error backpropagation. Once the training process converges, the resulting diffractive layers are fabricated to form a passive, free-space optical processing unit that does not consume any power except the illumination light. This framework is also scalable, since it can adapt to changes in the input field of view (FOV) or data dimensions by adjusting the size and/or the number of diffractive layers. Diffractive networks can directly access the 2D/3D input information of a scene or object and process the optical information encoded in the amplitude, phase, spectrum, and polarization of the input light, making them highly suitable as intelligent optical front ends for machine-vision systems.
Diffractive neural networks have been used to perform various optical information processing tasks, including, object classification,22,46–57 image reconstruction,52,58,59 all-optical phase recovery and quantitative image phase imaging,60 class-specific imaging,61 super-resolution image displays,62 and logical operations.63–65 Employing successive spatially engineered diffractive surfaces as the backbone for inverse design of deterministic optical elements also enabled numerous applications, such as spatially controlled wavelength demultiplexing,66 pulse engineering,67 and orbital angular momentum multiplexing/demultiplexing.68
Sign up for Advanced Photonics TOC. Get the latest issue of Advanced Photonics delivered right to you!Sign up now
In addition to these task-specific applications, diffractive networks also serve as general-purpose computing modules that can be used to create compact, power-efficient all-optical processors. Recent efforts have shown that a diffractive network can be used to all-optically perform an arbitrarily selected, complex-valued linear transformation between its input and output FOVs with a negligible error when the number of trainable diffractive neurons () approaches , where and represent the number of pixels at the input and output FOVs, respectively.69 Using nontrainable, predetermined polarizer arrays within an isotropic diffractive network, a polarization-encoded diffractive processor was also demonstrated to accurately perform a group of distinct complex-valued linear transformations using a single system with ; in this case, each one of these four optical transformations can be accessed through a different combination of the input/output polarization states.70 This polarization-encoded diffractive system is limited to a multiplexing factor of , since an additional desired transformation matrix that can be assigned to a new combination of input–output polarization states can be written as a linear combination of the four linear transforms that are already learned by the diffractive processor.70 These former works involved monochromatic diffractive networks where a single illumination wavelength encoded the input information channels.
In this paper, we rigorously address and analyze the following question. Let us imagine an optical black-box (composed of diffractive surfaces and/or reconfigurable spatial light modulators): how can that black-box be designed to simultaneously implement, e.g., independent linear transformations corresponding to different matrix multiplications (with different independent matrices) at different unique wavelengths? More specifically, here we report the use of a wavelength multiplexing scheme to create a broadband diffractive optical processor, which massively increases the throughput of all-optical computing by performing a group of distinct linear transformations in parallel using a single diffractive network. By encoding the input/output information of the target linear transforms using different wavelengths (i.e., ), we created a single-broadband diffractive network to simultaneously perform a group of arbitrarily selected, complex-valued linear transforms with negligible error. We demonstrate that diffractive neurons are required to successfully implement complex-valued linear transforms using a broadband diffractive processor, where the thickness values of its diffractive neurons constitute the only variables optimized during the deep-learning-based training process. Without loss of generality, we numerically demonstrate wavelength-multiplexed universal linear transformations with , which can be further increased to based on the approximation error threshold that is acceptable. We also demonstrate that these wavelength-multiplexed universal linear transformations can be implemented even with a flat material dispersion, where the refractive index () of the material at the selected wavelength channels is the same, i.e., for . The training process of these wavelength-multiplexed diffractive networks was adaptively balanced across different wavelengths of operation such that the all-optical linear transformation accuracies of the different channels were similar to each other, without introducing a bias toward any wavelength channel or the corresponding linear transform.
It is important to emphasize that the goal of this work is not to train the broadband diffractive network to implement the correct linear transformations for only a few input–output field pairs. We are not aiming to use the diffractive layers as a form of metamaterial that can output different images or optical fields at different wavelengths. Instead, our goal is to generalize the performance of our broadband diffractive processor to infinitely many pairs of input and output complex fields that satisfy the target linear transformation at each spectral channel, thus achieving universal all-optical computing of multiple complex-valued matrix–vector multiplications, accessed by a set of illumination wavelengths ().
Moreover, we would like to clarify that the wavelength multiplexing scheme used for our framework in this paper should not be confused with other efforts that integrated wavelength-division multiplexing (WDM) technologies to optical neural computing, such as in Refs. 71–73. In these earlier work, WDM was utilized to encode the 1D input/output information to perform a vector–matrix multiplication operation, where the optical network was designed to perform only one linear transformation based on a single input data vector, producing a single output vector that is spectrally encoded. However, in our work, we use the wavelength multiplexing to perform multiple independent linear transformations () within a single optical network architecture, where each of these complex-valued linear transformations can be accessed at distinct wavelengths (simultaneously or sequentially). Also the input and output fields of each one of these linear transformations in our framework are spatially encoded in 2D at the input/output FOVs using the same wavelength, rather than being spectrally encoded, as demonstrated in earlier WDM-based designs.71–73 This unique feature allows our diffractive network to all-optically perform a large group of independent linear transformations in parallel by sharing the same 2D input/output FOVs.
Compared to the previous literature, this paper has various unique aspects: (1) this is the first demonstration of a spatially engineered diffractive system to achieve spectrally multiplexed universal linear transformations; (2) the level of massive multiplexing that is reported through a single wavelength-multiplexed diffractive network (e.g., ) is significantly larger compared to other channels of multiplexing, including polarization diversity,70 and this number can be further increased to with more diffractive neurons () used in the network design; (3) deep-learning-based training of the diffractive layers used adaptive spectral weights to equalize the performances of all the linear transformations assigned to different wavelengths; (4) the capability to perform multiple linear transformations using wavelength multiplexing does not require any wavelength-sensitive optical elements to be added into the diffractive network design, except for wavelength scanning or broadband illumination with demultiplexing filters; and (5) this wavelength-multiplexed diffractive processor can be implemented using various materials with different dispersion properties (including materials with a flat dispersion curve) and is widely applicable to different parts of the electromagnetic spectrum, including the visible band. Furthermore, we would like to emphasize that since each dielectric feature of this wavelength-multiplexed diffractive processor is based on material thickness variations, it simultaneously modulates all the wavelengths within the spectrum of interest. This means that each wavelength channel within the set of unique wavelengths has a different error gradient with respect to the optical transformation that is assigned to it, and therefore, the diffractive layer optimization spanning wavelengths deviates from the ideal optimization path of an individual wavelength. Since the diffractive layers considered here do not possess any spectral selectivity, we used a training loss function, simultaneously taking into account all the wavelength channels that were used to find a locally optimal intersection set among all the wavelengths to accurately perform all the desired transformations. This behavior is quite different from the earlier generations of monochromatic diffractive processors69 that optimized the phase profiles of the diffractive layers for only one wavelength assigned to one optical transformation.
Based on the massive parallelism exhibited by this broadband diffractive network, we believe that this platform and the underlying concepts can be used to develop optical processors operating at different parts of the spectrum with extremely high computing throughput. Its throughput can be further increased by expanding the range and/or the number of encoding wavelengths as well as by combining wavelength multiplexing with other multiplexing schemes such as polarization encoding. The reported framework would be valuable for the development of multicolor and hyperspectral machine-vision systems that perform statistical inference based on the spatial and spectral information of an object or a scene, which may find applications in various fields, including biomedical imaging, remote sensing, analytical chemistry, and material science.
2 Results
2.1 Design of Wavelength-Multiplexed Diffractive Optical Networks for Massively Parallel Universal Linear Transformations
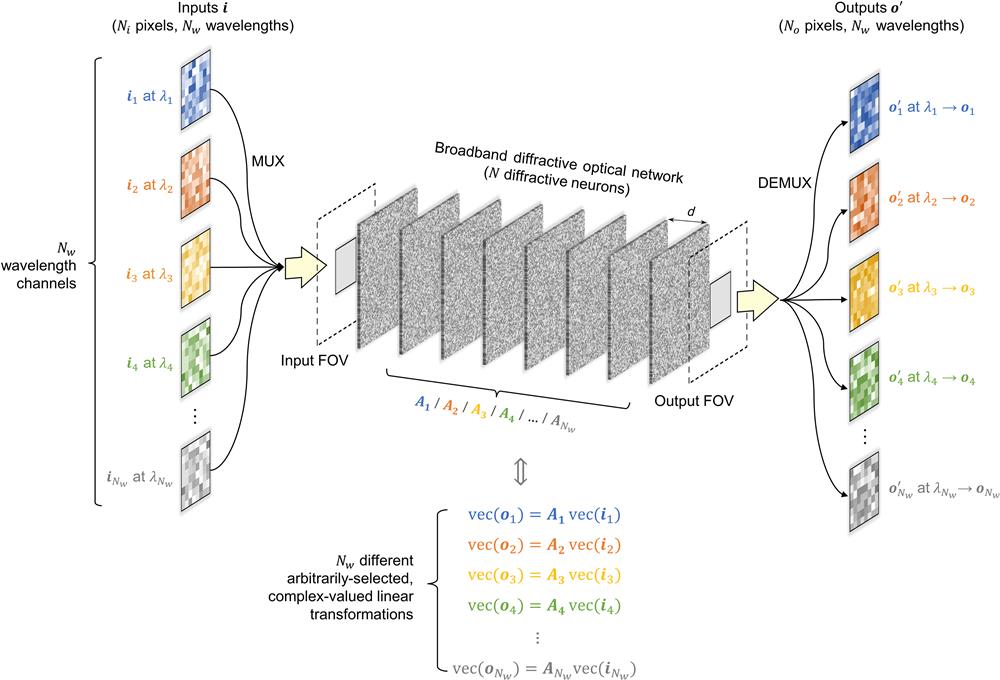
Throughout this paper, the terms “diffractive deep neural network,” “diffractive neural network,” “diffractive optical network,” and “diffractive network” are used interchangeably. Figure 1 illustrates the schematic of our broadband diffractive optical network design for massively parallel, wavelength-multiplexed all-optical computing. The broadband diffractive network, composed of eight successive diffractive layers, contains in total diffractive neurons with their thickness values as learnable variables, which are jointly trained to perform a group of linear transformations between the input and output FOVs through parallel wavelength channels. More details about this diffractive architecture, its optical forward model, and training details can be found in Sec. 4. To start with, a group of different wavelengths, , are selected to be used as the wavelength channels for the broadband diffractive processor to encode different input complex fields and perform different target transformations (see Fig. 1). For the implementation of the broadband diffractive designs in this paper, we fixed the mean value of this group of wavelengths , i.e., and assigned these wavelengths to be equally spaced between and . Unless otherwise specified, we chose to be 0.8 mm in our numerical simulations, as it aligns with the terahertz band that was experimentally used in several of our previous works.50,52,58,59,61,62,66,67 Without loss of generality, the wavelengths used for the design of the broadband diffractive processors can also be selected at other parts of the electromagnetic spectrum, such as the visible band, for which the related simulation results and analyses can be found in Sec. 3 to follow. Based on the scalar diffraction theory, the broadband optical fields propagating in the diffractive system are simulated at these selected wavelengths using a sampling period of along both the horizontal and vertical directions. We also select as the size of the individual neurons on the diffractive layers. With these selections, we include in our optical forward model all the propagating modes that are transmitted through the diffractive layers.
Figure 1.Schematic of massively parallel, wavelength-multiplexed diffractive optical computing. Optical layout of the wavelength-multiplexed diffractive neural network, where the diffractive layers are jointly trained to perform different arbitrarily selected, complex-valued linear transformations between the input field and the output field using wavelength multiplexing. The optical fields at the input FOV, , are encoded at a predetermined set of distinct wavelengths , respectively, using a wavelength multiplexing (“MUX”) scheme. At the output FOV of the broadband diffractive network, wavelength demultiplexing (“DEMUX”) is performed to extract the diffractive output fields at the corresponding wavelengths , respectively, which represent the all-optical estimates of the target output fields , corresponding to the target linear transformations (). Through this diffractive architecture, different arbitrarily selected complex-valued linear transformations can be all-optically performed at distinct wavelengths, running in parallel channels of the broadband diffractive processor.
Let and be the complex-valued, vectorized versions of the 2D input and output broadband complex fields at the input and output FOVs of the diffractive network, respectively, as shown in Fig. 1. We denote and as the complex fields generated by sampling the optical fields at the wavelength within the input and output FOVs, respectively, and then vectorizing the resulting 2D matrices in column-major order. According to this notation, and represent the input and output of the wavelength channel in our wavelength-multiplexed diffractive network, respectively. In the following analyses, without loss of generality, the number of pixels at the input and output FOVs is selected to be the same, i.e., .
To implement target linear transformations, we randomly generated complex-valued matrices , each composed of entries, to serve as a group of unique arbitrary linear transformations to be all-optically implemented using a wavelength-multiplexed diffractive processor. All these matrices, , are generated using unique random seeds to ensure that they are different; we further confirmed the differences between these randomly generated matrices by calculating the cosine similarity values between any two combinations of the matrices in a given set (see e.g., Fig. S1 in the Supplementary Material). For each unique matrix , we randomly generated a total of 70,000 complex-valued input field vectors and created the corresponding output field vectors by calculating . We separated these input–output complex field pairs into three individual sets for training, validation, and testing, each containing 55,000, 5000, and 10,000 samples, respectively. By increasing the size of these training data sets to input–output pairs of randomly generated complex fields, it is possible to further improve the transformation accuracy of the trained broadband diffractive networks; since this does not change the general conclusions of this work, it is left as future work. More details on the generation of the training and testing data can be found in Sec. 4.
Based on the notations introduced above, the objective of training our wavelength-multiplexed diffractive processor is that, for any of its wavelength channels operating at , the diffractive output fields computed from any given inputs should provide a match to the output ground-truth (target) fields . If this can be achieved for any arbitrary choice of , this means that the all-optical transformations performed by the trained broadband diffractive system at different wavelength channels constitute an accurate approximation to their ground-truth (target) transformation matrices , where .
As the first step of our analysis, we selected the input/output field size to be and started to train broadband diffractive processors with , 4, 8, 16, and 32 wavelength channels. Results and analysis of implementing more wavelength channels (e.g., ) through a single diffractive processor will be provided in later sections. For this task, we randomly generated a set of 32 different matrices with dimensions of , i.e., , with their first eight visualized (as examples) in Fig. 2(a) with their amplitude and phase components. Figure S1a in the Supplementary Material also reports the cosine similarity values between these randomly generated 32 matrices, confirming that they are all very close to 0. For each mentioned above, we also trained several broadband diffractive designs with different numbers of trainable diffractive neurons, i.e., ∈ {3900; 8200; 16,900; 32,800; 64,800; 131,100; 265,000}, all using the same training data sets {(, )}, randomly generated based on the target transformations () and the same number of training epochs.
Figure 2.All-optical transformation performances of broadband diffractive networks using different numbers of wavelength channels. (a) As examples, we show the amplitude and phase of the first eight matrices in that were randomly generated, serving as the ground truth (target) for the diffractive all-optical transformations. See Fig. S1 in the Supplementary Material for the cosine similarity values calculated between any two combinations of these 32 target linear transformation matrices. (b) The mean values of the normalized MSE between the ground-truth transformation matrices () and the corresponding all-optical transforms () across different wavelength channels are reported as a function of the number of diffractive neurons . The results of the diffractive networks using different numbers of wavelength channels are encoded with different colors, and the space between the simulation data points is linearly interpolated. ∈ {1, 2, 4, 8, 16, and 32}, ∈ {3.9k, 8.2k, 16.9k, 32.8k, 64.8k, 131.1k, 265.0k} and . (c) Same as (b) but the cosine similarity values between the all-optical transforms and their ground truth are reported. (d) Same as (b) but the MSE values between the diffractive network output fields and the ground-truth output fields are reported.
To benchmark the performance of these wavelength-multiplexed diffractive networks for each , we also trained monochromatic diffractive networks without using any wavelength multiplexing as our baseline, which can approximate only one target linear transformation using a single wavelength (i.e., ). Here we simply select as the operating wavelength of this baseline monochrome diffractive network used for comparison.
During the training of these diffractive networks, mean squared error (MSE) loss is calculated per wavelength channel to make the diffractive output fields come as close to the ground-truth (target) fields as possible. However, in the wavelength-multiplexed diffractive models, treating all these channels equally in the final loss function would result in the all-optical transformation accuracies being biased, since longer wavelengths present lower spatial resolution. To address this issue and equalize the all-optical transformation accuracies of all the wavelengths within the selected channel set, we devised a strategy by adaptively adjusting the weight coefficients applied to the loss terms of these channels during the training process (see Sec. 4 for details).
After the deep-learning-based training of the broadband diffractive designs introduced above is completed, the resulting all-optical diffractive transformations of these models are summarized in Figs. 2(b)–2(d). We quantified the generalization performance of these broadband diffractive networks on the blind testing data set for each transformation using three different metrics: (1) the normalized transformation MSE (), (2) the cosine similarity (CosSim) between the all-optical transforms and the target transforms, and (3) the MSE between the diffractive network output fields and their ground-truth output fields ().53,69 More details about the definitions of these performance metrics are provided in Sec. 4. For the diffractive designs with different numbers of wavelength channels (, 2, 4, 8, 16, and 32), we report these performance metrics in Figs. 2(b)–2(d) as a function of the number of trainable diffractive neurons (). These performance metrics reported in Fig. 2 refer to the mean values calculated across all the wavelength channels, whereas the results of the individual wavelength channels are shown in Fig. 3.
Figure 3.All-optical transformation performances of the individual wavelength channels in broadband diffractive network designs with and . The output field errors for the all-optical linear transforms achieved by the wavelength-multiplexed diffractive network models with (a) 2-channel wavelength multiplexing (), ; (b) 4-channel wavelength multiplexing (), ; (c) 8-channel wavelength multiplexing (), ; (d) 16-channel wavelength multiplexing (), ; and (e) 32-channel wavelength multiplexing (), . The standard deviations (error bars) of these metrics are calculated across the entire testing data set.
In Fig. 2(b), it can be seen that the transformation errors of all the trained diffractive models show a monotonic decrease as increases, which is expected due to the increased degrees of freedom in the diffractive processor. Also the approximation errors of the regular diffractive networks without using wavelength multiplexing, i.e., , approaches 0 as approaches . This observation confirms the conclusion obtained in our previous work,69,70 i.e., a phase-only monochrome diffractive network requires at least diffractive neurons to approximate a target complex-valued linear transformation with negligible error. On the other hand, for the wavelength-multiplexed diffractive models with different wavelength channels that are trained to approximate unique linear transforms, we see in Fig. 2 that the approximation errors approach 0 as approaches . This finding indicates that compared to a baseline monochrome diffractive model that can only perform a single transform, performing multiple distinct transforms using wavelength multiplexing within a single diffractive network requires its number of trainable neurons to be increased by -fold. This conclusion is further supported by the results of the other two performance metrics, CosSim and , as shown in Figs. 2(c) and 2(d): as approaches , CosSim and of the wavelength-multiplexed diffractive models approach 1 and 0, respectively.
To reveal the linear transformation performance of the individual wavelength channels in our wavelength-multiplexed diffractive processors, in Fig. 3, we show the channel-wise output field errors of the wavelength-multiplexed diffractive networks with , 4, 8, 16, and 32 and . Figure 3 indicates that the of these individual channels are very close to each other in all the designs with different , demonstrating no significant performance bias toward any specific wavelength channel or target transform. For comparison, we also show in Fig. S2 in the Supplementary Material, the resulting of the diffractive model with and when our channel balancing training strategy with adaptive weights was not used (see Sec. 4). There appears to be a large variation at the output field errors among the different wavelength channels if adaptive weights were not used during the training; in fact, the channels assigned to longer wavelengths tend to show much inferior transformation performance, which highlights the significance of using our balancing strategy during the training process. Stated differently, unless a channel balancing strategy is employed during the training phase, longer wavelengths suffer from relatively lower spatial resolution and face increased all-optical transformation errors compared to the shorter wavelength channels.
To visually demonstrate the success of our broadband diffractive system in performing a group of linear transformations using wavelength multiplexing, in Fig. 4, we show examples of the ground-truth transformation matrices (i.e., ) and their all-optical counterparts (i.e., ) resulting from the diffractive designs with and . The amplitude and phase absolute errors between the two ( and ) are also reported in the same figure. Moreover, in Fig. 5 and Fig. S3 in the Supplementary Material, we present some exemplary complex-valued input–output optical fields from the same set of diffractive designs with and , respectively. These results, summarized in Figs. 4 and 5 and Fig. S3 in the Supplementary Material, reveal that, when , the all-optical transformation matrices and the output complex fields of all the wavelength channels match their ground-truth targets very well with negligible error, which is also in line with our earlier observations in Fig. 2.
Figure 4.All-optical transformation matrices estimated by two different wavelength-multiplexed broadband diffractive networks with and . The first broadband diffractive network has trainable diffractive neurons. The second broadband diffractive network has trainable diffractive neurons. The absolute differences between these all-optical transformation matrices and the corresponding ground-truth (target) matrices are also shown in each case. diffractive design achieves a much smaller and negligible absolute error due to the increased degrees of freedom.
Figure 5.Examples of the input/output complex fields for the ground-truth (target) transformations along with the all-optical output fields resulting from the 8-channel wavelength-multiplexed diffractive design using . Absolute errors between the ground-truth output fields and the all-optical diffractive network output fields are negligible. Note that indicates the wrapped phase difference between the ground-truth output field and the normalized diffractive network output field .
2.2 Limits of : Scalability of Wavelength-Multiplexing in Diffractive Networks
We have so far demonstrated that a single broadband diffractive network can be designed to simultaneously perform a group of arbitrary complex-valued linear transformations, with , 4, 8, 16, and 32 (Figs. 2 and 3). Next, we explore the feasibility of implementing a significantly larger number of wavelength channels in our system to better understand the limits of . Due to our limited computational resources available, to simulate the behavior of larger values, we selected and . Accordingly, we generated a new set of 184 different arbitrarily selected complex-valued matrices with dimensions of , i.e., , as the target linear transformations to be all-optically implemented. The cosine similarity values between these randomly generated matrices are reported in Fig. S1b in the Supplementary Material, confirming that they are all very close to 0. We also created training, validation, and testing data sets based on these new target transformation matrices following the same approach as in the previous section: for each transformation matrix, we randomly generated 55,000, 5000, and 10,000 field samples for the training, validation, and testing data sets, respectively. Then using the training field data sets, we trained broadband diffractive designs with different wavelength channels, where the target transforms were taken from the first matrices in the randomly generated set . For each choice, we also trained diffractive models with different numbers of diffractive neurons, including , , and .
The all-optical transformation performance metrics of the resulting diffractive networks on the testing data sets are shown in Fig. 6 as a function of . Figures 6(a)–6(c) reveal that the all-optical transformations of the diffractive designs with different show some increased error as increases. For the diffractive models with , the all-optical transformation errors at smaller appear to be extremely small and do not exhibit the same performance degradation with increasing ; only after we see an error increase in the all-optical transformations for . By comparing the linear transformation performance of the models with different , Fig. 6 clearly reveals that adding more diffractive neurons to a broadband diffractive network design can greatly improve its transformation performance, which is especially important to operate at a large .
Figure 6.Exploration of the limits of the number of wavelength channels that can be implemented in a broadband diffractive network. (a) The mean values of the normalized MSE between the ground-truth transformation matrices () and the all-optical transforms () across different wavelength channels are reported as a function of . The results of the broadband diffractive networks using different numbers of diffractive neurons () are presented with different colors: . Dotted lines are fitted based on the data points whose diffractive networks share the same . (b) Same as (a) but the cosine similarity values between the all-optical transforms and their ground truth are reported. (c) Same as (a) but the MSE values between the diffractive network output fields and the ground-truth output fields are reported. .
By having a linear fit to the data points shown in Figs. 6(a) and 6(c), we can extrapolate to larger values and predict an all-optical transformation error bound as a function of . With these fitted (dashed) lines shown in Figs. 6(a) and 6(c), we get a coarse prediction of the linear transformation performance of a broadband diffractive model with a significantly larger number of wavelength channels that is challenging to simulate due to our limited computer memory and speed. Interestingly, these three fitted lines (corresponding to diffractive designs with , , and ) intersect with each other at a point around with an of and an of . This level of transformation error coincides with the error levels observed at the beginning of our training, implying that a broadband diffractive model with , even after training, would only exhibit a performance level comparable to an untrained model. These analyses indicate that, for a broadband diffractive network trained with and a training data set of 55,000 optical field pairs, there is an empirical multiplexing upper bound of .
However, before reaching this ultimate limit discussed above, practically the desired level of approximation accuracy will set the actual limit of . For example, based on visual inspection and the calculated peak signal-to-noise ratio (PSNR) values, one can empirically choose a blind testing error of as a threshold for the diffractive network’s all-optical approximation error; this threshold corresponds to a mean PSNR value of , calculated for the diffractive network output fields against their ground truth (see Fig. S4 in the Supplementary Material). We marked this -based performance threshold in Fig. 6(c) using a black dashed line, which also corresponds to a transformation error of , which was also marked in Fig. 6(a) with a black dashed line. Based on these empirical performance thresholds set by and , we can infer that a broadband diffractive processor with can accommodate up to wavelength channels, where different linear transformations can be performed through a single broadband diffractive processor within the performance bounds shown in Figs. 6(a) and 6(c) (see the purple dashed lines). The same analysis reveals a reduced upper bound of for the diffractive network designs with (see the green dashed lines).
2.3 Impact of Material Dispersion and Losses on Wavelength-Multiplexed Diffractive Networks
In the previous section, we showed that a broadband diffractive processor can be designed to implement different target linear transforms simultaneously, and this number can be further extended to based on an all-optical approximation error threshold of . In this section, we provide additional analyses on material-related factors that have an impact on the accuracy of wavelength-multiplexed computing through broadband diffractive networks. For example, the selection of materials with different dispersion properties (i.e., the real and imaginary parts of the refractive index as a function of the wavelength) will impact the light–matter interactions at different illumination wavelengths. To numerically explore the impact of material dispersion and related optical losses, we took the broadband diffractive network design shown in Fig. 6 with and and retrained it using different materials. The first material we selected is a lossy polymer that is widely employed as a 3D printing material; this material was used to fabricate diffractive networks that operate at the terahertz part of the spectrum.52,66,67 The dispersion curves of this lossy material are shown in Fig. S5a in the Supplementary Material, which were also used in the design of the diffractive networks reported in the previous sections (with ). As a second material choice for comparison, we selected a lossless dielectric material, for which we took N-BK7 glass as an example and used its dispersion to simulate our wavelength-multiplexed diffractive processor design at the visible wavelengths with ; the dispersion curves of this material are reported in Fig. S5b in the Supplementary Material. As a third material choice for comparison, we considered a hypothetical scenario where the material of the diffractive layers had a flat dispersion at around , with no absorption and a constant refractive index () across all the selected wavelength channels of interest; see the refractive index curve of this “dispersion-free” material in Fig. S5c in the Supplementary Material.
After the training of the diffractive network models using these different materials selected for comparison, we summarized their all-optical linear transformation performance in Figs. 7(a)–7(c) (see the purple bars). These results reveal that all three diffractive models with different material choices achieved negligible all-optical transformation errors, regardless of their dispersion characteristics. This confirms the feasibility of extending our wavelength-multiplexed diffractive processor designs to other spectral bands with vastly different material dispersion features.
Figure 7.The impact of material dispersion and losses on the all-optical transformation performance of wavelength-multiplexed broadband diffractive networks. (a) The mean values of the normalized MSE between the ground-truth transformation matrices () and the all-optical transforms () across different wavelength channels are reported as a function of the material of the diffractive layers. The results of the diffractive networks trained with and without diffraction efficiency penalty are presented in yellow and purple colors, respectively. , , and . (b) Same as (a) but the cosine similarity values between the all-optical transforms and their ground truth are reported. (c) Same as (a) but the MSE values between the diffractive network output fields and the ground-truth fields are reported. (d) The mean diffraction efficiencies of the presented diffractive models across all the wavelength channels. (e) Diffraction efficiency of the individual wavelength channels for the broadband diffractive network model presented in (a)–(d) that uses the dielectric material without the diffraction efficiency-related penalty term in its loss function. (f) Same as (e), but the diffractive network was trained using a loss function with the diffraction efficiency-related penalty term.
In addition to the all-optical transformation accuracy, the output diffractive efficiency () of these diffractive network models is also practically important. As shown in Fig. 7(d), due to the absorption by the layers, the diffractive network model using the lossy polymer material presents a very poor output diffraction efficiency compared to the other two diffractive models that used lossless materials. In addition to the absorption of light through the diffractive layers, a wavelength-multiplexed diffractive network also suffers from optical losses due to the propagating waves that leak out of the diffractive processor volume. This second source of optical loss within a diffractive network can be strongly mitigated through the incorporation of diffraction efficiency-related penalty terms52,66,67,69 into the training loss function (see Sec. 4 for details). The results of using such a diffraction-efficiency-related penalty term during training are presented in Figs. 7(a)–7(d) (yellow bars), which indicate that the output diffraction efficiencies of the corresponding models were improved by to 1479-fold compared to their counterparts that were trained without using such a penalty term [see Fig. 7(d)]. We also show in Figs. 7(e) and 7(f), the output diffraction efficiencies of the individual wavelength channels trained without and with the diffraction-efficiency penalty term, respectively. These results also revealed that the diffraction-efficiency-related penalty term used during training not only improved the overall output efficiency of the diffractive processor design but also helped to mitigate the imbalance of diffraction efficiencies among different wavelength channels [see Figs. 7(e) and 7(f)]. These improvements also come at an expense; as shown in Figs. 7(a)–7(c), there is some degradation in the all-optical transformation performance of the diffractive networks that are trained with a diffraction-efficiency-related penalty term. However, this relative degradation in the all-optical transformation performance is still acceptable, since a cosine similarity value of to 0.998 is maintained in each case [see Fig. 7(b), yellow bars].
2.4 Impact of Limited Bit Depth on the Accuracy of Wavelength-Multiplexed Diffractive Networks
The bit depth of a broadband diffractive network refers to the finite number of thickness levels that each diffractive neuron can have on top of a common base thickness of each diffractive layer. For example, in a broadband diffractive network with a bit depth of 8, its diffractive neurons will be trained to have at most different thickness values that are distributed between a predetermined minimum thickness and a maximum thickness value. To mechanically support each diffractive layer, the minimum thickness is always positive, acting as the base thickness of each layer. To analyze the impact of this bit depth on the linear transformation performance and accuracy of our wavelength-multiplexed diffractive networks, we took the channel diffractive design reported in the previous sections (trained using a data format with 32-bit depth) and retrained it from scratch under different bit depths, including 4, 8, and 12. Based on the same test data set, the all-optical linear transformation performance metrics of the resulting diffractive networks are reported in Fig. 8 as a function of . Figure 8 reveals that a 12-bit depth is practically identical to using a 32-bit depth in terms of the all-optical transformation accuracy that can be achieved for the target linear transformations. Furthermore, a bit depth of 8 can also be used for a broadband diffractive network design to maintain its all-optical transformation performance with a relatively small error increase, which can be compensated for with an increase in , as illustrated in Fig. 8. These observations from Fig. 8 highlight (1) the importance of having a sufficient bit depth in the design and fabrication of a broadband diffractive processor and (2) the importance of as a way to boost the all-optical transformation performance under a limited diffractive neuron bit depth.
Figure 8.All-optical transformation performance of broadband diffractive network designs with , reported as a function of and the bit depth of the diffractive neurons. (a) The mean values of normalized MSE between the ground-truth transformation matrices () and the all-optical transforms () across different wavelength channels are reported as a function of . The results of the diffractive networks using different bit depths of the diffractive neurons, including 4, 8, 12, and 32, are encoded with different colors, and the space between the data points is linearly interpolated. , and . (b) Same as (a) but the cosine similarity values between the all-optical transforms and their ground truth are reported. (c) Same as (a) but the MSE values between the diffractive network output fields and the ground-truth output fields are reported.
2.5 Impact of Wavelength Precision or Jitter on the Accuracy of Wavelength-Multiplexed Diffractive Networks
Another possible factor that may cause systematic errors in our framework is the wavelength precision or jitter. To analyze the wavelength encoding related errors, we used the four-channel wavelength-multiplexed diffractive network model with and that was presented in Fig. 3(b). We deliberately shifted the illumination wavelength used for each encoding channel away from the preselected wavelength used during the training (i.e., , , , and ). The resulting linear transformation performance of the channels using different performance metrics is summarized in Figs. 9(a)–9(c) as a function of the illumination wavelength. All of these results in Fig. 9 show that as the illumination wavelengths used for each encoding channel gradually deviate from their designed/assigned wavelengths (used during the training of the wavelength-multiplexed diffractive network), their all-optical transformation accuracy begins to degrade. To shed more light on this, we used the previous performance threshold based on as an empirical criterion to estimate the tolerable range of illumination wavelength errors, which revealed an acceptable bandwidth of for each one of the encoding wavelength channels. Stated differently, when a given illumination wavelength is within of the corresponding preselected wavelength assigned for that spectral channel, the degradation of the linear transformation accuracy at the output of the wavelength-multiplexed diffractive network will satisfy . In practical applications, this level of spectral precision can be routinely achieved by using high-performance wavelength scanning sources74,75 (e.g., swept-source lasers) or narrow passband thin-film filters.
Figure 9.The impact of the encoding wavelength error on the all-optical linear transformation performance of a wavelength-multiplexed broadband diffractive network; , , and . (a) The normalized MSE values between the ground-truth transformation matrices () and the all-optical transforms () for the four different wavelength channels are reported as a function of the wavelengths used during the testing. The results of the different wavelength channels are shown with different colors, and the space between the simulation data points is linearly interpolated. (b) Same as (a) but the cosine similarity values between the all-optical transforms and their ground truth are reported. (c) Same as (a) but the MSE values between the diffractive network output fields and the ground-truth output fields are reported. The shaded areas indicate the standard deviation values calculated based on all the samples in the testing data set.
2.6 Permutation-Based Encoding and Decoding Using Wavelength-Multiplexed Diffractive Networks
So far, we have demonstrated the design of wavelength-multiplexed diffractive processors that can allow a massive number of unique complex-valued linear transformations to be computed, all in parallel, within a single diffractive optical network. To exemplify some of the potential applications of this broadband diffractive processor design, here we demonstrate the permutation matrix-based optical transforms, which have significance for telecommunications (e.g., channel routing and interconnects), information security, and data processing (see Fig. 10). Similar to the approaches introduced earlier, we randomly generated eight permutation matrices, [see Fig. 10(b)] and trained a wavelength-multiplexed diffractive network with and ; this architecture has the same configuration as the one shown in Fig. 3(c), and Fig. 4 (middle column), except it uses these new permutation matrices as the target transforms. After its training, in Fig. 10(a), we show examples of permutation-based encoding of input images using the trained broadband diffractive network. After being all-optically processed by our wavelength-multiplexed diffractive network design, all the input images () are simultaneously permuted (encoded) according to the permutation matrices assigned to the corresponding wavelength channels, resulting in the output fields , which very well match their ground truth [see Fig. 10(a)]. Stated differently, the trained wavelength-multiplexed diffractive processor can successfully synthesize the correct output field for all the possible input fields , since it presents an all-optical approximation of for .
Figure 10.An example of a wavelength-multiplexed diffractive network (, ) that all-optically performs eight different permutation (encoding) operations between its input and output FOVs, with each target permutation matrix assigned to a unique wavelength. (a) Input/output examples. Each one of the wavelength channels in the diffractive processor is assigned to a different permutation matrix . The absolute differences between the diffractive network output fields and the ground-truth (target) permuted (encoded) output fields are also shown in the last column. (b) Arbitrarily generated permutation matrices that serve as the ground truth (target) for the wavelength-multiplexed diffractive permutation transformations shown in (a).
Similarly, we present in Fig. S6 in the Supplementary Material that the same wavelength-multiplexed permutation transformation network can be used to all-optically decode the encoded/permuted patterns. In this case, the input encoded fields are generated by transforming (permuting) the same input images using the inverse of the permutation matrices . The results shown in Fig. S6 in the Supplementary Material indicate that the wavelength-multiplexed diffractive network can all-optically perform simultaneous decoding of all the input images, very well matching their ground truth.
2.7 Experimental Validation of a Wavelength-Multiplexed Diffractive Network
Next, we performed a proof-of-concept experimental validation of our diffractive network using wavelength-multiplexed permutation operations. With a frequency-tunable continuous-wave terahertz (THz) setup shown in Fig. 11(a) (see Sec. 4 for its implementation details), we tested a wavelength-multiplexed diffractive network design with and , where the two wavelength channels were chosen as and . Each one of these two wavelength channels in this experimental design is assigned to a unique, arbitrarily generated target permutation matrix ( and , see Fig. S7 in the Supplementary Material), such that any spatially structured pattern at the input FOV can be all-optically permuted by the diffractive optical network to form different desired patterns at the output FOV, performing and under and illumination, respectively. For this, we used a diffractive network architecture with three diffractive layers, with each layer having diffractive features, each with a lateral size of 0.4 mm (). The axial spacing between any two of the adjacent layers (including the input/output planes) in this design was set as 20 mm (). During the training process, a total of 55,000 randomly generated input–output field pairs corresponding to the target permutation matrices ( and ) were used to update the thickness values of these diffractive layers. After the training converged, the resulting diffractive layers were fabricated using a 3D printer and mechanically assembled to form a physical wavelength-multiplexed diffractive optical permutation processor, as shown in Figs. 11(b)–11(d).
Figure 11.Experimental validation of a wavelength-multiplexed diffractive network with and . (a) Photograph of the experimental setup, including the schematic of the THz setup. (b) The fabricated wavelength-multiplexed diffractive processor. (c) The learned thickness profiles of the diffractive layers. (d) Photographs of the 3D-printed diffractive layers. (e) Experimental results of the diffractive processor for the two wavelength channels and using the fabricated diffractive layers, which reveal a good agreement with their numerical counterparts and the ground truth. .
To experimentally test the performance of this 3D-fabricated wavelength-multiplexed diffractive network, different input patterns from the blind testing set (never used in training) were also 3D-printed and used as the input test objects. The experimental test results are reported in Fig. 11(e), revealing that the output patterns for all these input patterns show a good agreement with their numerically simulated counterparts and the ground-truth images. The success of these experimental results further confirms the feasibility of our wavelength-multiplexed diffractive optical transformation networks.
3 Discussion
We demonstrated wavelength-multiplexed diffractive network designs that can perform massively parallel universal linear transformations through a single diffractive processor. We also quantified the limits of and the impact of material dispersion, bit depth, and wavelength precision/jitter on the all-optical transformation performance of broadband diffractive networks. In addition to these, other factors may limit the performance of broadband diffractive processors, including the lateral and axial misalignments of diffractive layers, surface reflections, and other imperfections introduced during the fabrication. To mitigate some of these practical issues, various approaches, such as high-precision lithography and antireflection coatings can be utilized in the fabrication process of a diffractive network. As demonstrated in our previous work,50,52,61 it is also possible to mitigate the performance degradation resulting from some of these experimental factors by incorporating them as random errors into the physical forward model used during the training process, which is referred to as “vaccination” of the diffractive network.
The reported wavelength-multiplexed diffractive processor represents a milestone in expanding the parallelism of diffractive all-optical computing, simultaneously covering a large group of complex-valued linear transformations. Compared to our previous work,70 where a monochromatic diffractive optical network was integrated with polarization-sensitive elements to achieve multiplexing of four independent linear transformations, the multiplexing factor of a wavelength-multiplexed diffractive network is significantly increased to more than 180, and can further reach , revealing a major improvement in the all-optical processing throughput. Moreover, the physical architecture of this wavelength-multiplexed computing framework is also relatively simple, since it does not rely on any additional optical modulation elements, e.g., spectral filters; it solely utilizes the different phase modulation values of the same diffractive layers at different wavelengths of light, also being compatible with different materials with various dispersion properties (including flat dispersion, as illustrated in Fig. 7). One could perhaps argue that, equivalent to a wavelength-multiplexed diffractive network that uses trainable diffractive features to compute independent target linear transformations, we could utilize a set of separately optimized monochromatic diffractive networks, each assigned to perform one of the target linear transforms using diffractive features. However, such a multipath design involving different monochromatic diffractive networks (one for each target transformation) would require bulky optical routing for fan-in/fan-out, which would introduce additional insertion losses, noise, and misalignment errors into the system, thus hurting the energy efficiency, performance, and compactness of the optical processor. Considering the fact that we covered in this work, such an approach of using separate monochromatic diffractive networks is not a feasible strategy that can compete with a wavelength-multiplexed design. Furthermore, if additional multiplexing schemes other than the wavelength multiplexing reported here were to be used, such as temporal multiplexing, switching between different diffractive networks, they would also require the use of additional optoelectronic control elements, further increasing the hardware complexity of the system, which would not be feasible for a large .
It is worth further emphasizing that even if multiple separately optimized monochromatic diffractive networks could be trained to individually perform different target linear transforms at different wavelengths, it is not possible to directly combine the converged/optimized layers of these diffractive networks to match the broadband operation of the wavelength-multiplexed diffractive network presented here. Since these monochromatic networks are individually trained using only a single illumination wavelength, the optimized modulation of each wavelength under broadband illumination would produce destructive patterns to other wavelengths, and their transformation accuracies would be collectively hampered. This, once again, highlights the significance of our wavelength multiplexing scheme: a wavelength-multiplexed diffractive optical network can be realized through the engineering of the surface profiles of dielectric diffractive layers with arbitrary dispersion properties, whereas these profiles should be designed by simultaneously taking into account all the wavelength channels, with phase modulation values that are mutually coupled to each other.
To the best of our knowledge, there has not been a demonstration of a design for the all-optical implementation of a complex-valued, arbitrary linear transformation using metasurfaces or metamaterials. In principle, having different diffractive metaunits placed on the same substrate to perform different transformations at different wavelengths could be attempted as an alternative approach to what we presented in this paper. However, such an approach would face severe challenges since (1) at large spectral multiplexing factors () shown in this work, the lateral period for each spectral metadesign will substantially increase per substrate, lowering the accuracy of each transformation; (2) at each illumination wavelength, the other metaunits designed for (assigned to) the other spectral components, will also introduce “cross-talk fields” that will severely contaminate the desired responses at each wavelength and cannot be neglected since ; (3) the phase responses of the spectrally encoded metaunits, in general, cover a small angular range, leading to low numerical aperture (NA) solutions compared to the diffractive solutions reported in this work, where NA = 1 (in air); the low NA of metaunits fundamentally limits the space-bandwidth product of each transformation channel; and (4) if multiple layers of metasurfaces are used in a given design, all of these aforementioned sources of errors associated with spectral metaunits will accumulate and get amplified through the subsequent field propagation in a cascaded manner, causing severe degradations to the final output fields, compared to the desired fields. Perhaps due to these significant challenges outlined here, metasurface or metamaterial-based diffractive designs have not yet been reported as a solution to perform universal linear transformations—neither an arbitrary complex-valued linear transformation nor a group of linear transformations through some form of multiplexing.
As we have shown in Sec. 2, a diffractive neuron number of is required for a wavelength-multiplexed diffractive network to successfully implement different complex-valued linear transforms. Compared to the previous complex-valued monochrome () diffractive designs,69 the additional factor of 2 in results from the fact that the only trainable degrees of freedom for a broadband wavelength-multiplexed diffractive design are the thickness values of the diffractive neurons, whereas the different target transformations are all complex-valued. Stated differently, the resulting modulation values of different wavelengths through each diffractive neuron are mutually coupled through the dispersion of the material and depend on the neuron thickness.
Finally, we would like to emphasize that this presented framework can operate at various parts of the electromagnetic spectrum, including the visible band, so that the set of wavelength channels used to perform the transformation multiplexing can match with the light source and/or the spectral signals emitted from or reflected by the objects. In practice, this massively parallel linear transformation capability can be utilized in an optical processor to perform distinct statistical inference tasks using different wavelength channels, bringing in additional throughput and parallelism to optical computing. This wavelength-multiplexed diffractive network design might also inspire the development of new multicolor and hyperspectral machine-vision systems, where all-optical information processing is performed simultaneously based on both the spatial and spectral features of the input objects. The resulting hyperspectral or multispectral diffractive output fields can enable new optical visual processing systems that can identify or encode input objects with unique spectral properties. As another possibility, novel multispectral display systems can be created using these wavelength-multiplexed diffractive output fields to reconstruct spectroscopic images or light fields from compressed or distorted input spectral signals.62 All these possibilities enabled by wavelength-multiplexed diffractive optical processors can inspire numerous applications in biomedical imaging, remote sensing, analytical chemistry, material science, and many other fields.
4 Appendix: Materials and Methods
4.1 Forward Model of the Broadband Diffractive Neural Network
A wavelength-multiplexed diffractive network consists of successive diffractive layers that collectively modulate the incoming broadband optical fields. In the forward model of our numerical simulations, the diffractive layers are assumed to be thin optical modulation elements, where the feature on the layer at a spatial location represents a wavelength-dependent complex-valued transmission coefficient given by where and denote the amplitude and phase coefficients, respectively. The diffractive layers are connected to each other by free-space propagation, which is modeled through the Rayleigh–Sommerfeld diffraction equation:22,46where is the complex-valued field on the pixel of the layer at at a wavelength of , which can be viewed as a secondary wave generated from the source at ; and and . For the layer (, assuming the input plane is the layer), the modulated optical field at location is given by where denotes all the diffractive neurons on the previous diffractive layer.
For the diffractive models used for numerical analyses, we chose as the smallest sampling period for the simulation of the complex optical fields and also used as the smallest feature size of the diffractive layers. In the input and output FOVs, a binning is performed on the simulated optical fields, resulting in a pixel size of for the input/output fields. The axial distance () between the successive layers (including the diffractive layers and the input/output planes) in our diffractive processor designs is empirically selected as , where represents the lateral size of each diffractive layer.
The diffractive thickness value of each neuron of a diffractive layer is composed of two parts and as follows: where denotes the learnable thickness parameters of each diffractive feature and is confined between and for all the diffractive models used for numerical analyses in this paper. When a modulation with -bit depth is applied to the diffractive model, will be rounded to the nearest number that corresponds to one of different equally spaced levels within the range of [0, ]. The additional base thickness is a constant, which is chosen as to serve as substrate support for the diffractive neurons. To achieve the constraint applied to , an associated latent trainable variable was defined using the following analytical form:
Note that before the training starts values of all the diffractive neurons were randomly initialized with a normal distribution (a mean value of 0 and a standard deviation of 1). Based on these definitions, the amplitude and phase components of the complex transmittance of , i.e., and , can be written as a function of the thickness of each neuron and the incident wavelength : where the wavelength-dependent parameters and are the refractive index and the extinction coefficient of the diffractive layer material corresponding to the real and imaginary parts of the complex-valued refractive index , i.e., .66 In the numerical analyses of this work, we considered three different materials to form the diffractive layers of a broadband diffractive processor, including a lossy polymer, a lossless dielectric, and a hypothetical lossless dispersion-free material. Among these, the lossy polymer material represents a UV-curable 3D printing material (VeroBlackPlus RGD875, Stratasys Ltd.), which was used in our previous work52,66,67 for 3D printing of diffractive networks. The lossless dielectric material, used for the diffractive models operating at the visible band, represents N-BK7 glass (Schott), ignoring the negligible absorption through thin layers. The dispersion-free material, on the other hand, assumed a lossless material with its refractive index having a flat distribution with respect to the wavelength range of interest, i.e., . The final and curves of different materials that were used for training the diffractive models reported in this paper are shown in Fig. S5 in the Supplementary Material.
4.2 Preparation of the Linear Transformation Data Sets
In this paper, the input and output FOVs of the diffractive networks are assumed to have the same size, which is set as , , or based on the assigned linear transformation tasks, i.e., , , or (). Accordingly, the size of the target complex-valued transformation matrices is equal to , , or , respectively, i.e., (), , or (). For arbitrary linear transformations, the amplitude and phase components of all these target matrices were generated with a uniform () distribution of and , respectively, using the pseudorandom number generation function random.uniform() built-in NumPy. For the arbitrarily selected permutation transformations, all the target matrices (also denoted as ) were generated by permuting an identity matrix of the same size as using the pseudorandom matrix permutation function random.permutation() built-in NumPy. Different random seeds were used to generate these transformation matrices to ensure they were unique. For training a broadband diffractive network with wavelength channels, the amplitude and phase components of the input fields () were randomly generated with a uniform () distribution of and , respectively. The ground-truth (target) fields () were generated by calculating . For each (), we generated a total of 70,000 input/output complex optical fields to form a data set, which was then divided into three parts: training, validation, and testing, each containing 55,000, 5000, and 10,000 complex-valued optical field pairs, respectively.
4.3 Training Loss Function
For each wavelength channel, the normalized MSE loss function is defined as where denotes the average across the current batch, stands for the wavelength channel that is being accessed, and indicates the element of the vector. and are the coefficients used to normalize the energy of the ground-truth (target) field and the diffractive network output field , respectively, which are given by
During the training of each broadband diffractive network, all the wavelength channels are simultaneously simulated, and the training data are fed into the channels at the same time. The wavelength-multiplexed diffractive network is trained based on the loss averaged across different wavelength channels. The total loss function that we used can be written as where is the adaptive spectral weight coefficient applied to the loss for the wavelength channel, which was used to balance the performance achieved by different wavelength channels during the optimization process. The initial values of for all the wavelength channels are set as 1. After the optimization begins, is adaptively updated after each training step using the following equation: where represents the MSE loss of the wavelength channel that is chosen to be a reference to measure the difference in the loss of the other channels. This also means that for the wavelength channel selected as the reference remains unchanged at 1. For the trained broadband diffractive models presented in this paper, we chose the middle channel as the reference wavelength channel, i.e., . According to this approach, for a wavelength channel that is not a reference channel, when the loss of the channel is small compared to that of the reference channel, will automatically decrease to reduce the weight of the corresponding channel. Conversely, when the loss of a specific wavelength channel is large compared to that of the reference channel, will automatically grow to increase the weight of the channel and thus enhance the subsequent penalty on the corresponding channel performance.
In order to increase the output diffraction efficiencies of the diffractive networks, we incorporated an additional efficiency penalty term to the loss function of Eq. (11): where represents the diffraction efficiency penalty loss applied to the wavelength channel, and represents its weight, empirically set as . is defined as where represents the mean output diffraction efficiency for the wavelength channel of the wavelength-multiplexed diffractive network, and refers to a predetermined penalization threshold, which was taken as (for diffractive models using the lossy polymer materials) or (for the other diffractive models using lossless dielectric or dispersion-free materials). is defined as
4.4 Performance Metrics Used for the Quantification of the All-Optical Transformation Errors
To quantitatively evaluate the transformation results of the wavelength-multiplexed diffractive networks, four different performance metrics were calculated per wavelength channel of the diffractive designs using the blind testing data set: (1) the normalized transformation MSE (), (2) the cosine similarity () between the all-optical transforms and the target transforms, (3) the normalized MSE between the diffractive network output fields and their ground truth (), and (4) the output diffraction efficiency [Eq. (15)]. The transformation error for the wavelength channel of the wavelength-multiplexed diffractive network is defined as where is the vectorized version of the ground-truth (target) transformation matrix assigned to the wavelength channel , i.e., . is the vectorized version of , which is the all-optical transformation matrix performed by the trained diffractive network. is a scalar coefficient used to eliminate the effect of diffraction efficiency-related scaling mismatch between and , i.e.,
The cosine similarity between the all-optical diffractive transform and its target (ground truth) for the wavelength channel is defined as
The normalized MSE between the diffractive network outputs and their ground truth for the wavelength channel is defined using the same formula as in Eq. (8), except that is calculated across the entire testing set.
4.5 Training-Related Details
All the diffractive optical networks used in this work were trained using PyTorch (v1.11.0, Meta Platforms Inc.). We selected AdamW optimizer76,77 for training all the models, and its parameters were taken as the default values and kept identical in each model. The batch size was set as 8. The learning rate, starting from an initial value of 0.001, was set to decay at a rate of 0.5 every 10 epochs, respectively. The training of the diffractive network models was performed with 50 epochs. The best models were selected based on the MSE loss calculated on the validation data set. For the training of our diffractive models, we used a workstation with a GeForce RTX 3090 graphical processing unit (Nvidia Inc.) and Intel® Core™ i9-12900F central processing unit (Intel Inc.) and 64 GB of RAM, running Windows 11 operating system (Microsoft Inc.). The typical time required for training a wavelength-multiplexed diffractive network model with, e.g., and is .
4.6 Experimental Terahertz Setup
The diffractive layers used in our experiments were fabricated using a 3D printer (PR110, CADworks3D). The input test objects and holders were also 3D-printed (Objet30 Pro, Stratasys). After the printing process, the input objects were coated with aluminum foil to define the light-blocking areas, leaving openings at specific positions to define the transmitted pixels of the input patterns. The designed holder was used to assemble the diffractive layers and objects to mechanically maintain their relative spatial positions in line with our numerical design.
To test our fabricated wavelength-multiplexed diffractive network design, we adopted a THz continuous-wave scanning system, whose schematic is presented in Fig. 11(a). A WR2.2 modular amplifier/multiplier chain (AMC) followed by a compatible diagonal horn antenna (Virginia Diode Inc.) is used as the THz source. Each time, a 10-dBm RF input signal was set at 11.944 or 12.500 GHz () at the input of AMC and multiplied 36 times to generate output radiation at 450 or 430 GHz, respectively, which corresponds to the illumination wavelengths and used for the two wavelength channels. A 1-kHz square wave was also generated to modulate the AMC output for lock-in detection. By placing the wavelength-multiplexed diffractive network 600 mm away from the exit aperture of the THz source, an approximately uniform plane wave was created, impinging on the input FOV of the diffractive network. The intensity distribution within the output FOV of the diffractive network was scanned at a step size of 2 mm by a single-pixel mixer/AMC (Virginia Diode Inc.) detector, which was mounted on an positioning stage formed by combining two linearly motorized stages (Thorlabs NRT100). For illumination at or , a 10-dBm sinusoidal signal was also generated at 11.917 or 12.472 GHz (), respectively, as a local oscillator and sent to the detector to downconvert the output signal to 1 GHz. After being amplified by a low-noise amplifier (Mini-Circuits ZRL-1150-LN+) with a gain of 80 dBm, the downconverted signal was filtered by a 1-GHz () bandpass filter (KL Electronics 3C40-1000/T10-O/O) and attenuated by a tunable attenuator (HP 8495B) for linear calibration. This final signal was then measured by a low-noise power detector (Mini-Circuits ZX47-60), whose output voltage was read by a lock-in amplifier (Stanford Research SR830) using the 1-kHz square wave as the reference signal and calibrated to a linear scale. In our postprocessing, cropping and pixel binning were applied to each measurement of the intensity field to match the pixel size and position of the output FOV used in the design phase, resulting in the output measurement images shown in Fig. 11(e).
Jingxi Li received his BS degree in optoelectronic information science and engineering from Zhejiang University, Hangzhou, Zhejiang, China, in 2018. Currently, he is working toward his PhD in the Electrical and Computer Engineering Department, University of California, Los Angeles, California, United States. His work focuses on optical computing and information processing using diffractive networks and computational optical imaging for biomedical applications.
Tianyi Gan received his BS degree in physics from Peking University, Beijing, China, in 2021. He is currently a PhD student in the Electrical and Computer Engineering Department at the University of California, Los Angeles. His research interests are terahertz source and imaging.
Bijie Bai received her BS degree in measurement, control technology, and instrumentation from Tsinghua University, Beijing, China, in 2018. She is currently working toward her PhD in the Electrical and Computer Engineering Department, University of California, Los Angeles, CA, USA. Her research focuses on computational imaging for biomedical applications and machine learning and optics.
Yi Luo received his BS degree in measurement, control technology, and instrumentation from Tsinghua University, Beijing, China, in 2016. He is currently working toward his PhD in the Bioengineering Department, University of California, Los Angeles, CA, USA. His work focuses on the development of computational imaging and sensing platforms.
Mona Jarrahi is a professor and a Northrop Grumman Endowed chair in the Electrical and Computer Engineering Department at the University of California Los Angeles and the director of Terahertz Electronics Laboratory. She has made significant contributions to the development of ultrafast electronic and optoelectronic devices and integrated systems for terahertz, infrared, and millimeter-wave sensing, imaging, computing, and communication systems by utilizing innovative materials, nanostructures, and quantum structures as well as innovative plasmonic and optical concepts.
Aydogan Ozcan is the Chancellor’s professor and the Volgenau chair for engineering innovation at UCLA and an HHMI professor at the Howard Hughes Medical Institute. He is also the associate director of the California NanoSystems Institute. He is elected a fellow of the National Academy of Inventors and holds >60 issued/granted patents in microscopy, holography, computational imaging, sensing, mobile diagnostics, nonlinear optics, and fiber-optics. He is also the author of 1 book and the co-author of >950 peer-reviewed publications in leading scientific journals/conferences. He is elected a fellow of Optica, AAAS, SPIE, IEEE, AIMBE, RSC, APS and the Guggenheim Foundation and is a lifetime fellow member of Optica, NAI, AAAS, and SPIE.