
Conghe Wang, Yutong He, Xia Wang, Honghao Huang, Changda Yan, Xin Zhang, Hongwei Chen, "Passive non-line-of-sight imaging for moving targets with an event camera," Chin. Opt. Lett. 21, 061103 (2023)
- Chinese Optics Letters
- Vol. 21, Issue 6, 061103 (2023)
Abstract
1. Introduction
Non-line-of-sight (NLOS) imaging has attracted great attention with its widespread potential applications in object detection, autonomous driving, and anti-terrorist reconnaissance[1–3]. According to whether a controllable light source is used, NLOS imaging is classified as active NLOS imaging[4,5] and passive NLOS imaging[6,7].
Passive NLOS imaging shows promising application and research prospects due to its simple device and convenient data acquisition. However, the NLOS problem is known as an inverse problem in mathematics, and we need to perform blind deconvolution, which is time-consuming and computationally burdened. Consequently, light-cone transform theory using matrix inverse[8], back projection algorithm based on photon time-of-flight information[9], and wave-based phasor field approach[10] are proposed successively. But few of these methods perform well in passive NLOS moving target reconstruction because the steady-state detection mode of passive NLOS suffers from serious degradation of the diffusion spot on the relay surface[11] and the superposition effect of isotropic diffuse reflection by close pixels[12]. Currently, speckle coherence restoration[13] and intensity-based data-driven reconstruction methods[14,15] are used to solve the ill-posed passive NLOS imaging dilemma. Since the movement of the target induces motion blur to the intensity distribution on the relay surface and superposes with the obscurity caused by diffusion[16], the current end-to-end deep-learning approach[11,17] performs well only on static NLOS targets[18] but shows defects in reconstruction quality for moving targets. In contrast, to realize high quality and efficient reconstruction, we deduce the event form detection-forward model of passive NLOS and establish the event-based inverse problem, on the basis of which we first put forward the event cues for passive NLOS moving target reconstruction. In this way, the dynamic information of the intensity diffusion is precisely captured by the event detection paradigm.
2. Principle and Methods
In this section, we present the working principle of the event camera and then explain the inverse problem setup by derivation of the forward model in passive NLOS imaging.
Sign up for Chinese Optics Letters TOC. Get the latest issue of Chinese Optics Letters delivered right to you!Sign up now
2.1. Event-based vision
The event camera[19], known as a novel neuromorphic vision device, only responds to brightness changes per pixel asynchronously, while traditional frame-based cameras measure absolute brightness at a fixed rate. The record paradigm of event-based vision provides high temporal resolution, high dynamic range, and low power consumption[20]. Therefore, it finds great potential in challenging scenarios for standard cameras, such as high speed, high dynamic range imaging[21], or object detection[22] in a slightly changing optical field.
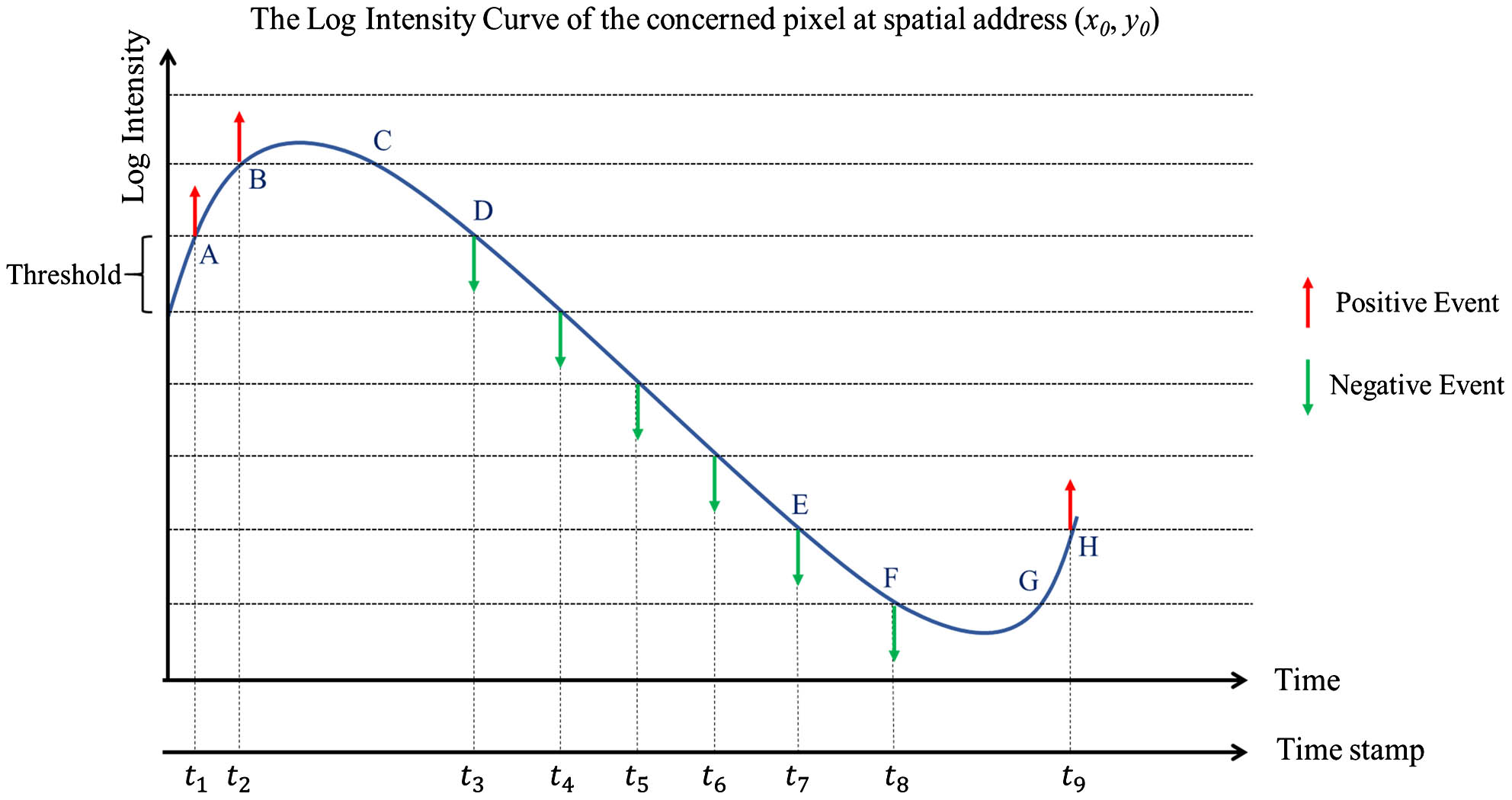
The working principle of the event camera is illustrated in Fig. 1. When the logarithmic intensity of the brightness changes reaches the trigger threshold, the pixel will be triggered and recorded as an event. Each pixel records the logarithmic form of the intensity when an event is fired and continuously monitors for sufficient amplitude changes based on this stored value. The event is described by four characteristic parameters:
![]()
Figure 1.Schematic of events excitation with changes in brightness at pixel level. The red arrow stands for a fired positive event, while the green arrow stands for the negative one.
Data collected by an event camera are recorded in the form of four characteristic parameters, time stamp
2.2. Forward model of passive NLOS
The forward model of NLOS is a modeling expression of the light transport in data collecting, which could be regarded as the inverse process of NLOS imaging. It makes up of the theoretical basis of NLOS reconstruction from the scope of steady-state imaging and derivation.
The intensity of the diffusion spot on the relay surface[23] could be expressed as
The detection function of diffusion on the relay surface could be written in the form of the matrix,
2.3. Event-based reconstruction method
In our work, we adopt the event cues to extract the movement information and texture feature of the targets. The most intuitive representation of the dynamic information on the relay surface is the origin event data. However, as addressed in Eq. (1), an event is composed of the triggered time stamp, spatial address, and polarity flag, which belong to three different data formats, respectively. As a result, it is critical to convert the sparse 4D event points into a featured tensor that contains both temporal and spatial characteristics. Therefore, we adopt the time-surface[24] method to represent the event-based data and extract the featured diffusion spot, which contains rich information on the target movement.
We visualize the event-based data to demonstrate their representations. The relay surface is selected as a mirror for clear visualization. The target “A” is moving from left to right in the FoV, as shown in Fig. 2.
![]()
Figure 2.Representations of event-based data.
In Fig. 2(b), the frame-based image is captured by a traditional camera, while Fig. 2(c) shows the asynchronous events captured by an event camera, consisting of 3D scatter points, which represent the parameters
Based on the detection function in Eq. (6), we represent the intensity of pixel
Then, we utilize the step function
![]()
Figure 3.Discrimination function of fired event.
After extracting the dynamic information on the diffusion spot movements, we put forward an event-embedded framework that fuses the extracted event features with a UNet structure to solve the inverse problem. As shown in Fig. 4, we display a video containing a parallel moving target with a smartphone, and leverage the event-based vision to record the dynamic diffusion spot on the relay surface.
![]()
Figure 4.Flow chart of event-embedded passive NLOS imaging.
We perform a time-surface calculation on the voxel grid[21] to extract the featured diffusion spot and represent event data at different time intervals by a series of 2D intensity images. Time-surface[24] is expressed by
According to the assumption that the fired events of the adjacent voxel grids share a similar spatial address, the spatial address of the fired event stream is highly correlated. As a result, when we perform a time-surface calculation on the acquired event data in a voxel grid, the context information on the movements is accumulated. Then, the temporal and spatial features of the moving target can be expressed by
The event-based inverse problem is established by
A typical solution of this reconstruction is using optimal methods to solve the matrix inverse of
However, the condition number of matrix
3. Experimental Setups
For the experimental proof of the event-based approach, we constructed experimental setups, as shown in Fig. 5. We displayed a video that provided the self-luminous moving target in the NLOS region of the event camera, blocked by the obstacle. The moving diffusion spot on the relay surface is recorded by the event camera (CeleX-V) in Section 1 of the Supplementary Material and Visualization 1.
![]()
Figure 5.Experimental setup. (a) Basic principle of our NLOS scene; (b) experimental settings; the self-luminous target is a video with moving digits.
The targets used in the experiment contain characters of number digits selected from the MNIST training set, MNIST test set, and PRINT test set (Arial font numbers), with the size of
We select 14 different kinds of characters for each digit (0–9) in the MNIST training set and test set, and then acquire both event-based data and frame-based data with different modes of the CeleX-V camera. The self-luminous target displayed by the smartphone translates from left to right in the FoV at a preset speed of 2.5 cm/s. When recording the moving diffusion spot in full-picture (F) mode, we get series of screenshots in different positions with the frame rate of 100 frames per second, while in event-intensity (EI) mode, we get a stream of event-based data of the diffusion spot movement. Data collected by these two modes are calibrated to the ground truth by the time stamp and made into image format data sets event MNIST NLOS (EM-NLOS) and frame MNIST NLOS (FM-NLOS), correspondingly.
To the best of our knowledge, we first established the EM-NLOS data set, which contains 4080 images in the training set and validation set and 210 images in the test set. The training set is made up of 3950 featured events. The time-surface map has 130 targets (13 groups, 0–9) at different positions, while the validation set contains 130 images. The test set consists of 110 images with 10 digits (0–9) selected from the MNIST test set and 100 images with 10 digits (0–9) in Arial font. As the counterpart, FM-NLOS contains the corresponding frame-based intensity diffusion spot movement, with 4180 images in total. We compare the training results on EM-NLOS and FM-NLOS, which are noted as an event-based method (E method) and a frame-based method (F method), respectively. The reconstruction accuracies of the F method and the E method on the MNIST test set and the PRINT test set are shown and compared in Fig. 6.
![]()
Figure 6.(a) Part of the reconstruction results for the PRINT test set in both EM-NLOS and FM-NLOS; (b) part of the reconstruction results for the MNIST test set in both EM-NLOS and FM-NLOS.
We trained our residual-UNet (R-UNet) on the EM-NLOS training set with an adaptive moment (Adam) estimation optimizer with Nvidia RTX 3090 GPU for 800 epochs. To achieve fair comparisons, we trained the R-UNet on the FM-NLOS training set with the same configuration[17]. The structure of our R-UNet and training parameters are given in Section 2 of the Supplementary Material.
4. Experimental Results and Discussions
The reconstruction quality of the moving target is assessed from two perspectives: the visual reconstruction quality and the position accuracy. For the former, we introduce the peak signal-to-noise ratio (PSNR) and learned perceptual image patch similarity (LPIPS)[27] to evaluate the reconstructions. The reconstruction accuracies of the F method and the E method on the MNIST test set and the PRINT test set are shown and compared in Figs. 6(a) and 6(b), respectively. It is obvious that the proposed E method with event-based data shows much better reconstruction quality than the F method, especially in recognizing the digits.
As for the position accuracy, we define the index contour distance (Cd) to measure the position of the reconstructions. The Cd value is evaluated by the average distance between the left edge and the digit left contour (made up by first pixels with a gray scale of 255 in each row after image binarization). Digit 7 in the MNIST test set and digit 3 in the PRINT test set are demonstrated as examples in this Letter. As shown in Fig. 7, the reconstruction by the E method is closer to ground truth than that of the F method. The average Cd deviation of the E method is far smaller than that of the F method, as shown in Fig. 8.
![]()
Figure 7.Reconstructions of NLOS moving target at different positions through the E method and the F method. Six different positions of digit 7 (MNIST test set) and digit 3 (PRINT test set) are displayed as examples. The Cd value (pixel) is labeled at the corner of each frame.
![]()
Figure 8.Cd value of NLOS reconstructions at different positions. (a), (b) are the Cd values of reconstructions shown in Fig.
Furthermore, the visual reconstruction accuracy of the E method is also intuitively higher than that of the F method. One can see from Fig. 9 that the E method evidently performs better on both of the two metrics, indicating that the event-based approach exceeds the frame-based method under the same data set size and network structure.
![]()
Figure 9.Evaluation metrics LPIPS and PSNR for reconstructions of digit 7 (MNIST test) and digit 3 (PRINT test) at 10 different positions, respectively. The full line denotes the E method, while the dotted line denotes frame-based ones.
We statistically analyze the reconstruction accuracy indexes of 10 digits in both the MNIST test set and the PRINT test set at different positions. The average LPIPS and PSNR of each reconstructed frame for different test digits with the E method and the F method are shown in Table 1, respectively. One can see from Table 1 that the reconstruction LPIPS obtained by the E method is 38% and 11% lower than by the F method on the two test sets, respectively, which demonstrate the higher quality of human perception. As for the PSNR, the E method scores higher than the F method on every test target and performs about 10% better numerically.
| Digit | PSNR/dB (↑) | LPIPS (↓) | ||||||
|---|---|---|---|---|---|---|---|---|
| MNIST test | PRINT test | MNIST test | PRINT test | |||||
| E (ours) | F | E (ours) | F | E (ours) | F | E (ours) | F | |
| 0 | 17.98 | 17.02 | 18.25 | 16.67 | 0.088 | 0.084 | ||
| 1 | 26.57 | 18.66 | 0.036 | 0.083 | ||||
| 2 | 19.09 | 19.04 | 17.29 | 15.96 | 0.092 | 0.085 | 0.087 | |
| 3 | 16.48 | 16.42 | 0.129 | 0.099 | ||||
| 4 | 19.33 | 18.13 | 15.36 | 0.067 | 0.076 | 0.101 | 0.114 | |
| 5 | 20.84 | 19.56 | 17.42 | 15.96 | 0.075 | 0.082 | 0.090 | |
| 6 | 20.48 | 19.64 | 14.63 | 0.070 | 0.101 | 0.106 | ||
| 7 | 17.22 | 17.78 | 17.26 | 0.106 | 0.081 | 0.086 | ||
| 8 | 19.66 | 18.47 | 15.04 | 0.086 | 0.088 | 0.095 | ||
| 9 | 16.86 | 17.35 | 17.17 | 0.085 | 0.084 | 0.086 | ||
| Avg. | 20.57 | 18.90 | 18.11 | 16.32 | 0.052 | 0.084 | 0.083 | 0.093 |
Table 1. Evaluation Metrics of Results with E Method and F Method
As for the generalization, see Section 3 of the Supplementary Material for discussions about target movement and Visualization 2 for the possibility of applying event-based NLOS imaging in real-world circumstances.
5. Conclusion
In summary, we leverage the sampling specialty of an event camera and propose a new detection and reconstruction method for passive NLOS imaging. The E method extracts rich dynamic information from the diffusion spot movements and provides a physical foundation for passive NLOS imaging of moving targets. Compared with the deep-learning approach with a traditional camera, the event-based framework shows better performance when reconstructing NLOS moving targets. We carry out experiments on two types of targets with different distribution forms and verify that the reconstruction quality is significantly improved with the framework we addressed in both visual accuracy and position accuracy. The reconstruction quality on the PRINT test set indicates that our method has extracted more movement information on moving targets with the event detection paradigm compared with traditional frame-based detection. We believe that the event approach for the inverse problem, together with the EM-NLOS data set, is a big step and can inspire new ideas toward the development of feature-embedded passive NLOS imaging with multidetector information fusion[12] and NLOS target tracking[28]. The event cues we demonstrated fuse the event paradigm information of NLOS moving target with end-to-end data-driven methods for solving the event-based inverse problem. In future work, we will take target movements and environment disturbance into consideration, and continually put forward the applications of event-based cues in practice by providing enhancement for methods based on other dimensions of the light field. The event-based vision utilized in this work has great potential to facilitate further research on feature-embedded passive NLOS and its applications.
References
[1] D. Faccio, A. Velten, G. Wetzstein. Non-line-of-sight imaging. Nat. Rev. Phys., 2, 318(2020).
[2] A. Kirmani, T. Hutchison, J. Davis, R. Raskar. Looking around the corner using transient imaging. IEEE 12th International Conference on Computer Vision (ICCV), 159(2009).
[3] T. Maeda, G. Satat, T. Swedish, L. Sinha, R. Raskar. Recent advances in imaging around corners(2019).
[12] K. Tanaka, Y. Mukaigawa, A. Kadambi. Polarized non-line-of-sight imaging. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2136(2020).
[14] M. Tancik, T. Swedish, G. Satat, R. Raskar. Data-driven non-line-of-sight imaging with a traditional camera. Imaging and Applied Optics, IW2B.6(2018).
[17] C. Zhou, C.-Y. Wang, Z. Liu. Non-line-of-sight imaging off a phong surface through deep learning(2020).
[20] A. Amir, B. Taba, D. Berg, T. Melano, J. McKinstry, C. Di Nolfo, T. Nayak, A. Andreopoulos, G. Garreau, M. Mendoza, J. Kusnitz, M. Debole, S. Esser, T. Delbruck, M. Flickner, D. Modha. A low power, fully event-based gesture recognition system. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7388(2017).
[22] S. Schaefer, D. Gehrig, D. Scaramuzza. AEGNN: asynchronous event-based graph neural networks. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12361(2022).
[27] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 586(2018).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20